向外扩展的解决方案-分散负载在多个奴隶来提高性能。在这种环境下,所有的写和更新必须在主服务器上。读,但是,可能发生在一个或更多的奴隶。这种模式可以提高写操作的性能(因为大师致力于更新),同时极大地提高阅读速度在越来越多的奴隶。 数据安全性:由于数据复制到奴隶和奴隶可以暂停复制过程,可以运行在从备份服务而不会破坏相应的主数据。 分析过的数据可以在主创造的,而这些信息的分析可以发生在奴隶主的性能没有影响。 长距离的数据分布-您可以使用复制来创建一个远程站点使用的数据的本地副本,无主永久访问。
为指导建立两个或两个以上的服务器使用二进制日志文件位置复制, 第17.1.2,“建立复制二进制日志文件的位置 ,随着服务器配置的交易和提供复制数据的主人和奴隶之间的方法。 为指导建立两个或两个以上的服务器使用gtid事务复制, 部分下面,“复制与全球事务标识符” 与配置的交易服务器 在二进制日志事件使用的格式记录。这些被称为基于语句的复制(SBR)或基于行的复制(RBR)。第三型、混合格式复制(混合),采用SBR和RBR复制自动利用双方的SBR和RBR格式的好处时,适当的。不同格式的讨论 17.2.1,“复制格式” 在不同的配置选项和变量适用于复制的详细信息提供 第17.1.6,“复制和二进制日志记录选项和变量” 一旦开始,复制过程需要很少的管理或监控。然而,对常见任务的建议,你可能要执行,看 第17.1.7,“常见的复制管理任务”
server-idCHANGE MASTER TO
上主,你必须确保启用了二进制日志,并配置一个唯一的服务器ID。这可能需要重新启动服务器。看到 第17.1.2.1,“设置复制主配置” 在每一个奴隶,你想连接到的主人,你必须配置一个唯一的服务器ID。这可能需要重新启动服务器。看到 第17.1.2.2,“设置复制从配置” 或者,为您创造奴隶使用认证与掌握阅读复制二进制日志时,在一个单独的用户。看到 第17.1.2.3,“创建一个用户复制” 在创建数据快照或启动复制过程中,你应该记录在二进制日志中的当前位置的主人。你需要这个信息当配置的奴隶,奴隶知道在开始执行的二进制日志事件。看到 第17.1.2.4,“获取复制二进制日志坐标” 如果你已经在主数据,想用它来同步的奴隶,你需要创建一个数据快照拷贝数据到奴隶。存储引擎你运用你如何创建快照的影响。当你使用 MyISAM,你必须停止处理报表在主获得读锁,然后获得其当前的二进制日志坐标和转储数据,之前允许主继续执行语句。如果你不停止执行语句、数据转储和主人的身份信息不匹配,导致不一致或已损坏的数据库上的奴隶。在复制的更多信息 MyISAM主人,看 第17.1.2.4,“获取复制二进制日志坐标” 。如果你使用的是 InnoDB,你不需要读锁和事务,是足够长的时间来传输数据快照是足够的。有关更多信息,参见 15.18节,“InnoDB和MySQL复制” 配置设置连接到主的奴隶,如主机名、登录凭据,和二进制日志文件的名称和位置。看到 第17.1.2.7,“设置主配置上的奴隶”
SUPER
为全新安装的主人和奴隶,不包含数据建立复制,看 第17.1.2.6.1,“设置复制新的主人和奴隶” 建立一个利用现有的MySQL服务器的数据复制到新的主人, 第17.1.2.6.2,“设置复制现有的数据” 添加复制的奴隶一个现有的复制环境,看 第17.1.2.8,“加入奴隶复制环境”
log_bin--log-bin
--server-idserver_id
为最大可能的耐久性和一致性的复制设置使用 InnoDB在交易中,你应该使用 innodb_flush_log_at_trx_commit=1和 sync_binlog=1在复制的 my.cnf 文件 确保 skip-networking在复制没有启用选项。如果网络已被禁用,奴隶不能与主复制失败。
[mysqld]
[mysqld]server-id=2
server-id
A -> B -> C
ABBAC--log-slave-updates--log-slave-updates
--skip-log-bin--skip-log-slave-updates
MASTER_USERREPLICATION
SLAVE
mysql.slave_master_info
CREATE
USERGRANTREPLICATION SLAVEexample.com
MySQL的> CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password';MySQL的> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com';
caching_sha2_passwordcaching_sha2_passwordMASTER_USER
FLUSH TABLES WITH
READ LOCKCOMMITInnoDB
通过连接到它的命令行客户端启动一个在主会议,并冲洗所有的表和块写语句的执行 FLUSH TABLES WITH READ LOCK声明: MySQL的> FLUSH TABLES WITH READ LOCK;警告 让客户从你发布的 FLUSH TABLES语句运行以便读锁仍然有效。如果你退出客户端,锁被释放。 在掌握不同的会话,使用 SHOW MASTER STATUS语句来确定当前的二进制日志文件的名称和位置: MySQL SHOW MASTER STATUS;------------------ ---------- -------------- ------------------ |文件|位置| binlog_do_db | binlog_ignore_db | ------------------ ---------- -------------- ------------------ | mysql-bin.000003 | 73 |测试|手册,MySQL | ------------------ ---------- -------------- ------------------ 这个 File列显示的日志文件的名称和 位置 列显示在文件中的位置。在这个例子中,二进制日志文件 mysql-bin.000003和位置73。记录这些值。你需要他们的时候设置的奴隶。他们所代表的奴隶应该复制坐标处理从主开始新的更新。 如果主人已禁用先前运行的二进制日志,日志文件的名称和位置值显示 SHOW MASTER STATUS或 mysqldump -硕士-日期 将是空的。在这种情况下,这个值,你需要使用后指定奴隶的日志文件和位置时,都是空字符串( '')和 四
如果你现有的数据,需要与从属同步在你开始复制,让客户端运行使锁依然存在。这可以防止任何进一步的变化,使数据复制到奴隶与主人同步。继续 第17.1.2.5,“选择方法对数据的快照” 如果你正在建立一个新的主从复制组,你可以退出第一届释放读锁。看到 第17.1.2.6.1,“设置复制新的主人和奴隶” 对于如何进行
dbdump.db--master-dataCHANGE MASTER
TO
内核> mysqldump --all-databases --master-data > dbdump.db
--master-data
--all-databases
排除所有的表在数据库中使用 --ignore-table选项 只是这些数据库的使用你想甩了 --databases选项
InnoDB
ft_stopword_fileft_min_word_lenft_max_word_len
InnoDB
MyISAMInnoDBinnodb_file_per_table
有关的文件 mysql数据库 主信息库文件 master.info,如果使用;该文件正在使用过时的(见 第17.2.4,“复制继电器和状态日志” ) 主人的二进制日志文件。 任何中继日志文件
InnoDB
InnoDB
获得读锁,得到主人的地位。看到 第17.1.2.4,“获取复制二进制日志坐标” 在一个单独的会话,关闭主服务器: shell>
mysqladmin shutdown复制MySQL数据文件。下面的例子展示了这样的常用方法。你只需选择其中之一: shell>
tar cfshell>/tmp/db.tar./datazip -rshell>/tmp/db.zip./datarsync --recursive./data/tmp/dbdata启动主服务器
InnoDB
获得读锁,得到主人的地位。看到 第17.1.2.4,“获取复制二进制日志坐标” 复制MySQL数据文件。下面的例子展示了这样的常用方法。你只需选择其中之一: shell>
tar cfshell>/tmp/db.tar./datazip -rshell>/tmp/db.zip./datarsync --recursive./data/tmp/dbdata在你获得的读锁定客户,释放锁: mysql>
UNLOCK TABLES;
配置必要的配置属性的MySQL的主。看到 第17.1.2.1,“设置复制主配置” 得到了主人的身份信息。看到 第17.1.2.4,“获取复制二进制日志坐标” 在主,释放读锁: mysql>
UNLOCK TABLES;对奴隶,编辑MySQL的配置。看到 第17.1.2.2,“设置复制从配置”
如果你没有一个数据库导入一个快照,看 第17.1.2.6.1,“设置复制新的主人和奴隶” 如果你有一个数据库导入一个快照,看 第17.1.2.6.2,“设置复制现有的数据”
启动MySQL的奴隶。 执行 CHANGE MASTER TO设置硕士复制服务器配置。See 第17.1.2.7,“设置主配置上的奴隶”
shell> mysql -h master < fulldb.dump
开始使用奴隶, --skip-slave-start选项,复制不启动 进口转储文件: shell>
mysql < fulldb.dump
数据文件提取到你的奴隶数据目录。例如: shell>
tar xvf dbdump.tar您可能需要设置权限和所有权的文件,从服务器可以访问和修改。 开始使用奴隶, --skip-slave-start选项,复制不启动 与复制配置从属坐标从主。这告诉奴隶的二进制日志文件的位置在哪里复制需要的文件。同时,随着登录凭据和主主机名配置从属。上的更多信息 CHANGE MASTER TO声明要求,见 第17.1.2.7,“设置主配置上的奴隶” 启动线程的奴隶: mysql>
START SLAVE;
slave_master_infomysql--master-info-repository=FILE--relay-log-info-repository=FILErelay-log.info
CHANGE MASTER
TO
my.cnf
mysql>CHANGE MASTER TO->MASTER_HOST='->master_host_name',MASTER_USER='->replication_user_name',MASTER_PASSWORD='->replication_password',MASTER_LOG_FILE='->recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;
CHANGE MASTER TO
MASTER_USERMASTER_PUBLIC_KEY_PATHCHANGE MASTER TO
server-id
关闭现有的奴隶: shell>
mysqladmin shutdown数据复制目录从现有的奴隶的奴隶。你可以通过创建一个档案利用 焦油 或 WinZip,或使用工具,如执行直接复制 内容提供商 或 远程同步 。确保你的日志文件复制和中继日志文件。 一个普遍的问题就是遇到增加新复制的奴隶,奴隶没有新一系列这样的警告和错误信息: 071118 16:44:10 [Warning] Neither --relay-log nor --relay-log-index were used; so replication may break when this MySQL server acts as a slave and has his hostname changed!! Please use '--relay-log=
new_slave_hostname-relay-bin' to avoid this problem. 071118 16:44:10 [ERROR] Failed to open the relay log './old_slave_hostname-relay-bin.003525' (relay_log_pos 22940879) 071118 16:44:10 [ERROR] Could not find target log during relay log initialization 071118 16:44:10 [ERROR] Failed to initialize the master info structure这种情况可以发生如果 --relay-log选项,作为中继日志文件包含主机名的文件名的一部分。这也是中继日志索引文件如果 --relay-log-index选项不使用。看到 第17.1.6,“复制和二进制日志记录选项和变量” 有关这些选项的更多信息。 为了避免这个问题,使用相同的值 --relay-log这是用在现有的新奴隶的奴隶。如果这个选项没有显式设置在现有的奴隶,使用 existing_slave_hostname中继站 。如果这是不可能的,复制现有的奴隶的中继日志索引文件到新的奴隶和设置 --relay-log-index选择新的奴隶来匹配所用的奴隶。如果这个选项没有显式设置在现有的奴隶,使用 existing_slave_hostname-relay-bin.index 。或者,如果你已经尝试开始新的奴隶后剩下的本节中的步骤和遇到的错误就像前面描述的那些,然后执行以下步骤: 如果你还没有这样做,问题 STOP SLAVE在新的奴隶 如果你已经开始存在的奴隶了,问题 STOP SLAVE在现有的奴隶一样 复制现有的奴隶的中继日志索引文件的内容到新的奴隶的中继日志索引文件,确保覆盖所有内容已经在文件。 继续在本节剩下的步骤。
如果文件已被用于主信息和中继日志信息库(参见 第17.2.4,“复制继电器和状态日志” ),复制这些文件从现有的奴隶的奴隶。这些持有主人的二进制日志和从中继日志当前日志坐标。如果表被用于仓库,现在是默认的,表在已复制的数据目录。 从现有的奴隶 在新的奴隶,编辑配置给新从一个独特的 server-id由船长或任何现有的奴隶不习惯。 开始新的奴隶。从使用它的主人的信息库的信息开始复制过程。
gtids如何定义和创建的,以及它们是如何在MySQL服务器代表(见 第17.1.3.1”gtid格式和存储” ) 一个gtid生命周期(见 第17.1.3.2,“gtid生命周期” ) 用于同步奴隶和奴隶主使用gtids自动定位功能(见 第17.1.3.3”gtid自动定位” ) 建立和启动gtid基于复制的一般程序(见 第17.1.3.4,“设置复制使用gtids” ) 供应新的复制服务器时使用gtids建议的方法(见 第17.1.3.5,“用gtids故障转移和Scaleout” ) 约束和限制,你应该意识到使用基于gtid复制时(见 第17.1.3.6,”与GTIDs的“复制限制 )
mysql.gtid_executed
:
GTID =source_id: transaction_id
source_idserver_uuidtransaction_idtransaction_idtransaction_id0
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
SHOW SLAVE STATUS--base64-output=DECODE-ROWSSHOW BINLOG
EVENTS
SHOW MASTER STATUS
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
server_uuid
START SLAVESQL_AFTER_GTIDS
gtid_set:uuid_set[,uuid_set] ... | ''uuid_set:uuid:interval[:interval]...uuid:hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhhh: [0-9|A-F]interval:n[-n] (n>= 1)
gtid_executedgtid_purgedGTID_SUBSET()GTID_SUBTRACT()
gtid_executed
mysql.gtid_executedCREATE TABLE
创建表gtid_executed(source_uuid char(36)不为空,interval_start bigint(20)不为空,interval_end bigint(20)不为空,主键(source_uuid,interval_start))
mysql.gtid_executed
mysql.gtid_executedgtid_modeON_PERMISSIVE
如果禁用二进制日志( log_bin是 关闭 ),或者 log_slave_updates是残疾人,服务器存储gtid属于每个交易与表中的交易。此外,该表被压缩在一个用户可配置的周期率;看 mysql.gtid_executed表压缩 为更多的信息。这种情况只能在复制的奴隶,或奴隶的二进制日志更新禁用日志记录的应用。它不会复制申请,因为主人,二进制日志必须复制将启用。 如果启用了二进制日志( log_bin是 打开(放) ),每当二进制日志旋转或服务器关闭,服务器写GTIDs,写进了以前的二进制日志到交易 mysql.gtid_executed表这种情况适用于复制,或复制从二进制日志记录功能。 在服务器停机意外事件,从当前的二进制日志gtids设置不保存在 mysql.gtid_executed表在这种情况下,这些gtids添加到表,在设定的gtids gtid_executed系统变量在恢复 当启用了二进制日志, mysql.gtid_executed表不提供所有已执行的交易记录完整的gtids。这些信息是由全球价值提供 gtid_executed系统变量
mysql.gtid_executedRESET MASTER
mysql.gtid_executed
MySQL的> SELECT * FROM mysql.gtid_executed;-------------------------------------- ---------------- -------------- | source_uuid | interval_start | interval_end | | -------------------------------------- ---------------- -------------- | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 37 | 37 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 38 | 38 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 39 | 39 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 40 | 40 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 41 | 41 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 42 | 42 | | 3e11fa47-71ca-11e1-9e33-c80aa9429562 | 43 | 43 |…
+--------------------------------------+----------------+--------------+ | source_uuid | interval_start | interval_end | |--------------------------------------+----------------+--------------| | 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 43 | ...
mysql.gtid_executedgtid_executed_compression_periodgtid_executed_compression_period
gtid_executed_compression_periodmysql.gtid_executed
mysql.gtid_executedSHOW
PROCESSLISTthreads
MySQL的> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G*************************** 1。行*************************** thread_id:26名称:螺纹/ SQL / compress_gtid_table类型:前景processlist_id:1 processlist_user:空processlist_host:空processlist_db:nullprocesslist_command:守护processlist_time:1509 processlist_state:悬浮processlist_info:空parent_thread_id:1作用:空仪表:是的历史:是的connection_type:空thread_os_id:18677
thread/sql/compress_gtid_tablegtid_executed_compression_periodgtid_executed_compression_period
交易执行和对主人承诺。此客户端事务分配一个由主人的UUID和最小的非零的事务序列号没有在此服务器上使用gtid。的gtid写入到主人的二进制日志(紧接交易本身在日志)。如果客户交易不写入二进制日志(例如,因为交易被过滤掉,或者交易是只读的),它没有指定gtid。 如果一个gtid被分为交易,坚持的gtid原子在写它的二进制日志在事务开始时提交时间(如 Gtid_log_event)。每当二进制日志旋转或服务器关闭,服务器写GTIDs,写进了以前的二进制日志文件到交易 mysql.gtid_executed 表 如果一个gtid被分为交易的gtid是外化,非原子(交易后不久承诺)添加到在集gtids gtid_executed系统变量( global.gtid _ executed @ )。这gtid集包含所有已提交的事务集的表示gtid。二进制日志功能(如主要求),在设定的gtids gtid_executed系统变量是一个完整的交易应用的记录,但 mysql.gtid_executed 表是没有的,因为最近的历史仍在当前的二进制日志文件。 在二进制日志中的数据传输到存储在奴隶和奴隶的中继日志(使用已建立的机制,这个过程中,看到 第17.2节,“复制执行” ,详情),从读gtid和设置它的值 gtid_next系统变量为这gtid。这告诉奴隶,接下来的交易必须登录使用本gtid。需要注意的是,从集重要 gtid _下 在会话上下文 从验证没有线程尚未采取的gtid所有权 gtid_next为了处理交易。通过阅读和检查复制事务的gtid首先处理前奴隶交易本身,不仅保证了没有以前的交易有gtid已应用于奴隶,也没有其他的会话已经读过这gtid但尚未提交关联交易。如果多个客户端试图使用相同的交易的同时,服务器解决这个让他们中只有一个执行。这个 gtid_owned系统变量( 国有global.gtid _ @ )为奴隶显示每个gtids目前正在使用和拥有它的线程的ID。如果gtid已经被使用,没有引发错误,并自动跳过功能是用来忽略交易。 如果gtid尚未使用,奴隶将复制事务。因为 gtid_next设置为gtid由主已经分配,奴隶并不试图生成此交易的一个新的gtid,而是使用gtid存储在 gtid_next如果二进制日志是对奴隶的gtid启用,是坚持原子在写的二进制日志在事务开始时提交时间(如 Gtid_log_event)。每当二进制日志旋转或服务器关闭,服务器写GTIDs,写进了以前的二进制日志文件到交易 mysql.gtid_executed 表 如果二进制日志是从残疾人的gtid坚持写它直接进入原子 mysql.gtid_executed表MySQL的附加声明事务插入gtid到表。在MySQL 8中,这个操作是原子的DDL语句以及DML语句。在这种情况下,的 mysql.gtid_executed 表是一个完整的交易记录于奴隶。 复制交易后不久在奴隶的承诺,gtid体现非自动添加到在集gtids gtid_executed系统变量( global.gtid _ executed @ )为奴隶。作为主人,这gtid集包含所有已提交的事务集的表示gtid。如果二进制日志是对残疾人的奴隶, mysql.gtid_executed表是一个完整的交易记录于奴隶。如果二进制日志是对奴隶的启用,意味着一些gtids仅记录在二进制日志,在设定的gtids gtid_executed系统变量是唯一完整的记录。
gtid_executedGtid_log_eventmysql.gtid_executedgtid_executed
slave_parallel_workers > 0slave_preserve_commit_order=1gtid_executedSTOP SLAVEKILL
@@session.gtid_next
gtid_purged
已复制事务,致力于与二进制日志对残疾人gtids奴隶 交易被写入二进制日志文件已经被清除gtids gtids增加了明确的语句集 SET @@global.gtid_purged
gtid_purgedPrevious_gtids_log_eventPrevious_gtids_log_eventgtid_purged
MASTER_LOG_FILECHANGE MASTER TO
MASTER_AUTO_POSITIONMASTER_LOG_FILE
GTID_MODE=ONOFF_PERMISSIVEGTID_MODE=ONgtid_executedreplication_connection_status
gtid_purgedMASTER_AUTO_POSITIONbinlog_expire_logs_seconds
如果复制已经运行,同步服务器通过使他们只读。 停止服务器 重新启动服务器gtids启用并正确的选项配置。 这个 mysqld 启动服务器进行必要的选项进行了下面的例子在本节稍后。 笔记 server_uuid必须存在gtids正常。 指导奴隶使用主作为复制数据源和使用自动定位。要做到这一步的SQL语句进行了下面的例子在本节稍后。 以一个新的备份。二进制日志包含交易无gtids不能用于服务器,gtids启用,所以才采取这一点不能用你的新配置备份。 开始的奴隶,然后禁用服务器的只读模式,使他们能够接受更新。
server_id
rootSUPERshutdownSHUTDOWN
read_only
mysql> SET @@global.read_only = ON;
username
内核> mysqladmin -uusername-p shutdown
gtid_modeenforce_gtid_consistency
gtid_mode=ONenforce-gtid-consistency=true
--skip-slave-start
--skip-log-bin--skip-log-slave-updates
CHANGE MASTER TO
mysql>CHANGE MASTER TO>MASTER_HOST =>host,MASTER_PORT =>port,MASTER_USER =>user,MASTER_PASSWORD =>password,MASTER_AUTO_POSITION = 1;
MASTER_LOG_FILEMASTER_AUTO_POSITIONCHANGE MASTER
TO
FLUSH
LOGS
mysql> START SLAVE;
mysql> SET @@global.read_only = OFF;
数据集 创建一个转储文件使用 mysqldump 在源服务器上。设置 mysqldump 选项 --master-data(用默认值1)包括 CHANGE MASTER TO与二进制日志信息的声明。设置 --set-gtid-purged选项 汽车 (默认)或 ON,包括执行交易的转储信息。然后使用 MySQL 客户导入转储文件在目标服务器上。 另外,创建一个数据快照使用原始数据文件的源服务器,然后将这些文件复制到目标服务器,下面的指令 第17.1.2.5,“选择方法对数据的快照” 。如果你使用 InnoDB表格,你可以使用 mysqlbackup 从MySQL企业备份组件产生一个一致的快照命令。这个命令记录日志名和偏移量对应的快照用于奴隶。MySQL企业备份是一个商业产品,包括作为一个MySQL企业认购部分。看到 第29,MySQL企业备份概述” 详细信息 另外,同时停止源服务器和目标服务器,复制的源数据目录到新的奴隶数据目录的内容,然后重新启动的奴隶。如果你使用这个方法,奴隶必须被配置为基于gtid复制,换句话说, gtid_mode=ON
交易历史 如果源服务器的二进制日志完整的交易历史(即的gtid集 @@global.gtid_purged是空的),你可以使用这些方法。 进口的二进制日志从源服务器使用的新的奴隶 mysqlbinlog ,与 --read-from-remote-server和 --read-from-remote-master选项 另外,复制源服务器的二进制日志文件的奴隶。你可以从使用拷贝 mysqlbinlog 与 --read-from-remote-server和 --raw选项这些可以读到从用 mysqlbinlog >file(没有 --raw选项)导出二进制日志文件的SQL文件,然后将这些文件到 MySQL 客户端的处理。确保所有的二进制日志文件是使用一个单一的处理 MySQL 的过程,而不是多个连接。例如: shell>
mysqlbinlog copied-binlog.000001 copied-binlog.000002 | mysql -u root -p有关更多信息,参见 第4.6.8.3,“用mysqlbinlog备份二进制日志文件”
gtid_executedgtid_executed
SET GTID_NEXT='aaa-bbb-ccc-ddd:N';BEGIN;COMMIT;SET GTID_NEXT='AUTOMATIC';
N
刷新日志;清除“master-bin.00000二进制日志 N';
FLUSH
LOGSPURGE BINARY LOGS
gtid_purgedgtid_executedPURGE BINARY LOGSgtid_purgedgtid_executed
COMMIT
/*!*/;
MySQL的> DELIMITER ;
mysql>SET GTID_NEXT=automatic;mysql>RESET SLAVE;mysql>START SLAVE;
MyISAMInnoDB
CREATE
TABLE ... SELECT
ALTER TABLE ... ADD
采用基于行的复制或混合,一 ER_BINLOG_UNSAFE_SYSTEM_FUNCTION错误发生时,无论gtid设置。 与基于语句的复制,声明的结果取决于gtid设置: 为 gtid_mode=OFF加 enforce_gtid_consistency=WARN,声明是接受一个警告。 为 gtid_mode=OFF加 enforce_gtid_consistency=ON,一个 ER_GTID_UNSAFE_ALTER_ADD_COL_WITH_DEFAULT_EXPRESSION错误发生 为 gtid_mode=ON_PERMISSIVE加 gtid_next=AUTOMATIC,一个 ER_GTID_UNSAFE_ALTER_ADD_COL_WITH_DEFAULT_EXPRESSION错误发生 为 gtid_mode=ON,一个 ER_GTID_UNSAFE_ALTER_ADD_COL_WITH_DEFAULT_EXPRESSION错误发生 为 gtid_next=UUID:NUMBER,一个 ER_GTID_UNSAFE_ALTER_ADD_COL_WITH_DEFAULT_EXPRESSION错误发生
CREATE TEMPORARY
TABLEDROP TEMPORARY
TABLE--enforce-gtid-consistencyautocommit=1
--enforce-gtid-consistency
--enforce-gtid-consistency
sql_slave_skip_countergtid_executed
CHANGE
MASTER TOSHOW_SLAVE_STATUS
gtid_mode=ON--write-binlog
TABLE--master-info-repository
FILE
STOP SLAVE;SET GLOBAL master_info_repository = 'TABLE';SET GLOBAL relay_log_info_repository = 'TABLE';
gtid_mode=ONCHANGE MASTER TOchannel
master13451master-1
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='', \
MASTER_AUTO_POSITION = 1 FOR CHANNEL 'master-1';
TABLEMASTER_LOG_POSITIONCHANGE MASTER TOchannelmaster13451master-1
CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='rpl', MASTER_PORT=3451, MASTER_PASSWORD='' \
MASTER_LOG_FILE='master1-bin.000006', MASTER_LOG_POS=628 FOR CHANNEL 'master-1';
START SLAVE
thread_types
开始所有的当前配置的复制通道: START SLAVEthread_types;开始只是一个命名的通道,使用 FOR CHANNELchannel条款: START SLAVEthread_typesFOR CHANNELchannel;
thread_types
STOP SLAVEFOR CHANNEL
channel
停止所有当前配置的复制通道: STOP SLAVEthread_types;止命名通道,使用 FOR CHANNELchannel条款: STOP SLAVEthread_typesFOR CHANNELchannel;
thread_types
RESET SLAVEFOR CHANNEL
channel
重置所有的当前配置的复制通道: RESET SLAVE;重置只命名通道,使用 FOR CHANNELchannel条款: RESET SLAVE FOR CHANNELchannel;
使用复制性能模式表。这些表的第一列 Channel_Name。这使您可以编写基于复杂查询 channel_name 作为一个关键的。看到 第25.11.11,绩效模式复制表” 使用 SHOW SLAVE STATUS FOR CHANNELchannel。默认情况下,如果 通道 channel条款是不能用的,这说明所有通道的奴隶地位每通道一行。标识符 channel_name 作为一个结果集中的列。如果一个 FOR CHANNELchannel设置条款,结果表明只有指定复制渠道现状。
SHOW VARIABLESSHOW VARIABLES
mysql> SELECT * FROM replication_connection_status\G;
*************************** 1. row ***************************
CHANNEL_NAME: master1
GROUP_NAME:
SOURCE_UUID: 046e41f8-a223-11e4-a975-0811960cc264
THREAD_ID: 24
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET: 046e41f8-a223-11e4-a975-0811960cc264:4-37
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 2. row ***************************
CHANNEL_NAME: master2
GROUP_NAME:
SOURCE_UUID: 7475e474-a223-11e4-a978-0811960cc264
THREAD_ID: 26
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 0
LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00
RECEIVED_TRANSACTION_SET: 7475e474-a223-11e4-a978-0811960cc264:4-6
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
2 rows in set (0.00 sec)
CHANNEL_NAMEmaster2
CHANNEL_NAMEWHERE CHANNEL_NAME=channel
MySQL的> SELECT * FROM replication_connection_status WHERE CHANNEL_NAME='master1'\G*************************** 1。行*************************** channel_name:master1group_name:source_uuid:046e41f8-a223-11e4-a975-0811960cc264thread_id:24service_state:oncount_received_heartbeats:0last_heartbeat_timestamp:0000-00-00 00:00:00received_transaction_set:046e41f8-a223-11e4-a975-0811960cc264:4-37last_error_number:0last_error_message:last_error_timestamp:0000-00-00 00:00:001行集(0秒)
WHERE
CHANNEL_NAME=channel
gtid交易是通过全局事务标识符(gtid)的形式 UUID:NUMBER。日志中的每gtid交易之前总有 gtid _ _事件日志 。gtid交易可以解决使用的gtid或使用文件的名称和位置。 匿名交易没有gtid分配,并保证每个MySQL日志匿名交易之前 Anonymous_gtid_log_event。在以前的版本中,匿名交易之前没有任何特别的事件。匿名交易只能使用文件名和位置寻址。
WAIT_FOR_EXECUTED_GTID_SET()session_track_gtidssql_slave_skip_counter
Anonymous_gtid_log_event
gtid_modeenforce_gtid_consistencySYSTEM_VARIABLES_ADMINSUPERgtid_modeOFFgtid_mode=ONgtid_mode=OFFgtid_mode=OFF_PERMISSIVEgtid_mode=ON_PERMISSIVEgtid_mode=ONgtid_mode=ON_PERMISSIVEgtid_mode
OFFOFF_PERMISSIVEON_PERMISSIVEON
gtid_modegtid_modeOFFONgtid_mode=ONgtid_mode=OFFgtid_executedgtid_mode
gtid_modegtid_executedgtid_purgedreplication_connection_statusSHOW SLAVE STATUSreplication_applier_status_by_worker
gtid_mode=ONCHANGE MASTER TO MASTER_AUTO_POSITION = 1;
gtid_modegtid_modegtid_mode
|
|
|
| |
|---|---|---|---|---|
| ||||
| ||||
| ||||
|
gtid_modegtid_nextgtid_modegtid_next
ANONYMOUS:生成一个匿名交易 Error:生成一个错误,无法执行 集gtid_next UUID:NUMBER:生成具有指定UUID gtid:数。 New GTID:生成一个自动生成的数量gtid。
gtid_next
全部 在拓扑结构,服务器必须使用MySQL 5.7.6或后。你不能使gtid网上交易对任何单一服务器除非 全部 这是拓扑中的服务器使用的是这个版本。 所有服务器都 gtid_mode设置为默认值 关闭
在每个服务器上,执行: SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
让你的正常工作一段时间服务器运行和监控日志。如果这一步的原因,日志中的任何警告,调整你的应用程序,它仅使用gtid兼容的功能不产生任何警告。 重要 这是重要的第一步。你必须确保没有警告是在错误产生的日志进行下一步之前。 在每个服务器上,执行: SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
不要紧,服务器执行此语句,但重要的是,所有的服务器完成此步骤的任何服务器开始下一步之前。 在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
不要紧,服务器执行此语句的第一。 在每个服务器上,等到状态变量 ONGOING_ANONYMOUS_TRANSACTION_COUNT是零。这可以检查使用: 显示状态“ongoing_anonymous_transaction_count”; 笔记 在一个复制的奴隶,这在理论上是可能的,这表明零和非零再然后。这是没有问题的,这就够了,这表明零次。 等所有的交易产生了第五步复制到所有服务器。你可以不停的更新:唯一重要的事是,所有匿名交易得到复制。 看到 第17.1.5.4,“验证复制匿名交易” 一检查所有的匿名交易已复制到所有服务器的方法。 如果你使用二进制日志以外的任何复制,在备份和恢复时间的例子,等到你不需要旧的二进制日志具有交易无gtids。 例如,在第6步完成后,您可以执行 FLUSH LOGS在服务器上你要备份。然后直接把备份或等待任何周期的备份程序可以设置下一个迭代。 理想情况下,等待服务器来清除所有的二进制日志时存在步骤6完成。还等在步骤6之前到期采取任何备份。 重要 这是第二重要点。理解二进制日志包含匿名交易是至关重要的,没有gtids无法使用后的下一步。在这一步中,您必须确保交易无gtids不在任何地方存在的拓扑结构。 在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = ON;
在每个服务器,添加 gtid-mode=ON到 my.cnf 你现在是保证所有的交易都有一个gtid(除交易产生在步骤5或更早,已经处理过的)。开始使用gtid协议以便以后可以执行自动故障切换,每个奴隶执行以下。或者,如果你使用多源复制,这样每个通道包括 FOR CHANNELchannel条款: STOP SLAVE [FOR CHANNEL 'channel'];CHANGE MASTER TO MASTER_AUTO_POSITION = 1 [FOR CHANNEL 'channel'];START SLAVE [FOR CHANNEL 'channel'];
全部 在拓扑结构,服务器必须使用MySQL 5.7.6或后。你不能禁用gtid网上交易对任何单一服务器除非 全部 这是拓扑中的服务器使用的是这个版本。 所有服务器都 gtid_mode设置 打开(放)
在每一个奴隶执行下面的,如果你使用多源复制,做为每个通道包括 FOR CHANNEL通道条款: STOP SLAVE [FOR CHANNEL 'channel'];CHANGE MASTER TO MASTER_AUTO_POSITION = 0, MASTER_LOG_FILE = file, \MASTER_LOG_POS = position [FOR CHANNEL 'channel'];START SLAVE [FOR CHANNEL 'channel'];
在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
在每个服务器上,等到变“@global.gtid_owned等于空字符串。这可以检查使用: SELECT @@GLOBAL.GTID_OWNED;
在一个复制的奴隶,这在理论上是可能的,这是空的,那么空了。这是没有问题的,这就够了,这一次是空的。 等所有的交易目前存在于任何二进制日志复制到所有的奴隶。看到 第17.1.5.4,“验证复制匿名交易” 一检查所有的匿名交易已复制到所有服务器的方法。 如果你使用二进制日志为别的比复制,例如做备份或恢复时间点:等到你不需要旧的二进制日志有gtid交易。 例如,在5步完成后,您可以执行 FLUSH LOGS在服务器上你要备份。然后直接把备份或等待任何周期的备份程序可以设置下一个迭代。 理想情况下,等待服务器来清除所有的二进制日志时存在步骤5完成。还等在第五步到期采取任何备份。 重要 这是很重要的一点是在这个过程中。这是了解含gtid事务日志不能用于下一步的重要。继续之前您必须确保gtid交易不在任何地方存在的拓扑结构。 在每个服务器上,执行: SET @@GLOBAL.GTID_MODE = OFF;
在每个服务器设置 gtid-mode=OFF进入 my.cnf 如果你想设置 enforce_gtid_consistency=OFF现在,你可以这样做。设置完成后,你应该添加 enforce_gtid_consistency=OFF您的配置文件
在主,执行: SHOW MASTER STATUS;
记下的价值 File和 位置 专栏 在每一个奴隶,使用从主执行文件和位置信息: SELECT MASTER_POS_WAIT(file, position);
For example, suppose you have three servers A, B, and C, replicating in a circle so that A -> B -> C -> A. The procedure is then:
做步骤1和步骤2在B上 做第一步和第二步C对B 做步骤1和步骤2 A,C 做步骤1和步骤2在B上 做第一步和第二步C对B 做步骤1和步骤2 A,C
--server-id
--server-id=# | |
server_id | |
1 | |
0 | |
0 | |
4294967295 |
server_id--server-id
server_idserver_uuid
server_uuid--server-id
server_uuid | |
auto.cnfmy.ini[auto]server_uuid
[auto]server_uuid=8a94f357-aab4-11df-86ab-c80aa9429562
auto.cnf
SHOW SLAVE HOSTSSTART SLAVESHOW SLAVE STATUS
STOP SLAVERESET SLAVE
server_uuid
--replicate-same-server-id
没有主人的期望 server_uuid存在. 硕士 server_uuid变了,虽然没有 CHANGE MASTER TO声明中曾被处决
abort-slave-event-count:通过调试和测试复制MySQL测试选项 binlog_gtid_simple_recovery:如何在二进制日志进行迭代gtid恢复控制 Com_change_master:改变主报表数 Com_show_master_status:SHOW MASTER STATUS语句数 Com_show_new_master:显示新主报表数 Com_show_slave_hosts:显示从主机报表数 Com_show_slave_status:显示奴隶地位的报表数 Com_show_slave_status_nonblocking:显示奴隶地位的非阻塞语句数 Com_slave_start开始从报表统计: Com_slave_stop停止从报表统计: disconnect-slave-event-count:通过调试和测试复制MySQL测试选项 enforce-gtid-consistency:防止报表无法登录事务安全的方式执行 enforce_gtid_consistency:防止报表无法登录事务安全的方式执行 executed-gtids-compression-period:废弃,会在未来的版本中删除;使用改名gtid执行压缩段代替 executed_gtids_compression_period:废弃,会在未来的版本中删除;使用改名gtid_executed_compression_period相反 gtid-executed-compression-period:压缩gtid_executed表每次许多交易发生。0意味着没有压缩表。仅适用于二进制日志被禁用。 gtid-mode基于gtid:控制是否启用了日志和什么类型的事务日志可以包含 gtid_executed:全球:在二进制日志中所有gtids(全球)或当前事务(会议)。只读。 gtid_executed_compression_period:压缩gtid_executed表每次许多交易发生。0意味着没有压缩表。仅适用于二进制日志被禁用。 gtid_mode基于gtid:控制是否启用了日志和什么类型的事务日志可以包含 gtid_next:指定要执行的下一条语句的gtid;看到文件的细节 gtid_owned:对gtids归该客户端集(会话),或由所有客户,共同与业主的线程ID(全球)。只读。 gtid_purged:所有gtids已经从二进制日志清除设置 init_slave:语句被执行时,从连接到一个主 log-slave-updates:告诉奴隶日志更新的SQL线程执行它自己的二进制日志 log_slave_updates:是否应该日志更新奴隶的SQL线程执行它自己的二进制日志。只读;用原木从更新服务器选项。 log_statements_unsafe_for_binlog错误1592:禁用警告被写入错误日志 master-info-file:的位置和文件名,记得师父在I/O复制线程在主人的二进制日志 master-info-repository:是否写主人的身份信息和复制I/O线位置在主人的二进制日志文件或表 master-retry-count:尝试次数的奴隶会放弃之前连接到主 master_info_repository:是否写主人的身份信息和复制I/O线位置在主人的二进制日志文件或表 max_relay_log_size:如果非零,中继日志是自动旋转时,它的大小超过此值。如果零,大小,旋转时是由价值决定的max_binlog_size。 original_commit_timestamp:时间是在原来的主人承诺交易 relay-log:名称使用中继日志的位置和基础 relay-log-index:的位置和名称的使用,保持一个列表的最后中继文件日志 relay-log-info-file的文件,记得:在SQL复制线程是在继电器的位置和名称的日志 relay-log-info-repository:是否在接力写复制SQL线程的位置记录到一个文件或表 relay-log-recovery:使主在启动时自动恢复中继日志文件 relay_log_basename:中继日志完整的路径,包括文件名 relay_log_index:继电器的日志索引文件的名称 relay_log_info_file:该文件中记录日志信息从继电器的名称 relay_log_info_repository:是否在接力写复制SQL线程的位置记录到一个文件或表 relay_log_purge:决定是否中继日志清除 relay_log_recovery:无论从主在启动时自动恢复中继日志文件启用;必须是一个安全的奴隶使 relay_log_space_limit:最大的空间用于所有中继日志 replicate-do-db:告诉奴隶SQL线程限制复制到指定的数据库 replicate-do-table:告诉奴隶的SQL线程限制复制到指定的表 replicate-ignore-db:告诉奴隶SQL线程不复制到指定的数据库 replicate-ignore-table:告诉奴隶SQL线程不复制到指定的表 replicate-rewrite-db:更新具有不同名称的数据库比原来 replicate-same-server-id:在复制中,如果设置为1,不要跳过我们的服务器ID事件 replicate-wild-do-table:告诉奴隶线程限制复制到表中指定的通配符模式匹配 replicate-wild-ignore-table:告诉奴隶线程不复制到表中给定的通配符模式匹配 report-host:主机名称或IP的奴隶是奴隶主在注册报告 report-password:任意一个密码,从服务器到主报告。不一样的MySQL复制的用户帐户的密码。 report-port:用于连接到奴隶主的奴隶报告在登记口 report-user:任意一个用户名,一个从服务器到主报告应。不一样的使用MySQL复制的用户帐户的名称。 Rpl_semi_sync_master_clients半同步奴隶的数量: rpl_semi_sync_master_enabled:半同步复制是否在主机启用 Rpl_semi_sync_master_net_avg_wait_time:平均时间主等待奴隶的答复 Rpl_semi_sync_master_net_wait_time:总时间的主人等待从机响应 Rpl_semi_sync_master_net_waits:时代的大师总数等待从机响应 Rpl_semi_sync_master_no_times:时代的主机关闭半同步复制数 Rpl_semi_sync_master_no_tx:提交数目不承认成功 Rpl_semi_sync_master_status半同步复制:是否是运行在主 Rpl_semi_sync_master_timefunc_failures:时代的主人失败的时候调用时间函数数 rpl_semi_sync_master_timeout:等待的毫秒数奴隶的承认 rpl_semi_sync_master_trace_level:半同步复制在痕量水平的掌握 Rpl_semi_sync_master_tx_avg_wait_time:平均时间的主人等待每个事务 Rpl_semi_sync_master_tx_wait_time:总时间的主人等待交易 Rpl_semi_sync_master_tx_waits:时代的大师数量等交易 rpl_semi_sync_master_wait_for_slave_count:有多少奴隶主必须接受确认每笔交易之前 rpl_semi_sync_master_wait_no_slave师父:是否等待超时甚至没有奴隶 rpl_semi_sync_master_wait_point:奴隶交易确认收到的等待点 Rpl_semi_sync_master_wait_pos_backtraverse:时代的大师总数等二进制坐标低于先前事务的等待事件 Rpl_semi_sync_master_wait_sessions:会议目前正在等待答复的奴隶数 Rpl_semi_sync_master_yes_tx:一些有公认的成功 rpl_semi_sync_slave_enabled半同步复制:是否启用奴隶 Rpl_semi_sync_slave_status半同步复制:是否运行在奴隶 rpl_semi_sync_slave_trace_level:半同步复制在痕量水平的奴隶 rpl_read_size:设置最小数据量的字节读取二进制日志文件和中继日志文件 rpl_stop_slave_timeout:设置秒,停止超时前等待数的奴隶 server_uuid:服务器的全局唯一的ID,自动生成的(再)在服务器启动 show-slave-auth-info:显示主机显示奴隶主的用户名和密码 simplified_binlog_gtid_recovery:如何在二进制日志进行迭代gtid恢复控制 skip-slave-start:如果设置了,奴隶是不autostarted slave-checkpoint-group:检查点操作前的一个多线程的最大数量的奴隶交易处理来更新进度。通过NDB集群不支持。 slave-checkpoint-period:更新进度多线程的奴隶和冲洗中继日志信息的磁盘数毫秒后。通过NDB集群不支持。 slave-load-tmpdir:位置的奴隶把临时文件复制时一个LOAD DATA INFILE语句 slave-max-allowed-packet:以字节为单位,一个数据包的最大大小,可以从复制给一个奴隶;覆盖max_allowed_packet slave_net_timeout:数秒,等待更多的数据从主/从之前中止阅读连接 slave-parallel-type:告诉奴隶使用时间戳信息(logical_clock)或数据库分区(数据库)并行交易。默认的是logical_clock。 slave-parallel-workers:在并行执行复制交易施放的线程数。默认的是四施放螺纹。设置0禁用从多线程。MySQL集群不支持。 slave-pending-jobs-size-max:奴隶工人队列举行活动尚未应用的最大尺寸 slave-rows-search-algorithms:决定用于奴隶批量更新搜索算法。任何2或3从列表中index_search,table_scan,hash_scan slave-skip-errors:告诉奴隶线程继续复制查询时返回一个错误从提供的列表 slave_checkpoint_group:检查点操作前的一个多线程的最大数量的奴隶交易处理来更新进度。通过NDB集群不支持。 slave_checkpoint_period:更新进度多线程的奴隶和冲洗中继日志信息的磁盘数毫秒后。通过NDB集群不支持。 slave_compressed_protocol:使用压缩的主/从协议 slave_exec_mode:允许幂等模式之间切换的从属线程(密钥和其他一些错误抑制)和严格的模式;严格模式是默认的,除了NDB集群,其中幂等总是用 Slave_heartbeat_period:奴隶的复制心跳的间隔,以秒 slave_max_allowed_packet:以字节为单位,一个数据包的最大大小,可以从复制给一个奴隶;覆盖max_allowed_packet Slave_open_temp_tables::从SQL线程当前已经打开的临时表的数量 slave_parallel_type:告诉奴隶使用时间戳信息(logical_clock)或数据库分区(数据库)并行交易。 slave_parallel_workers:在并行执行复制交易施放的线程数。值为0禁止奴隶多线程。MySQL集群不支持。 slave_pending_jobs_size_max:奴隶工人队列举行活动尚未应用的最大尺寸 slave_preserve_commit_order:确保所有提交的奴隶工人发生在相同的顺序在主线程并行应用使用时保持一致。 Slave_retried_transactions:从启动SLAVE端已尝试事务的总次数 slave_rows_search_algorithms:决定用于奴隶批量更新搜索算法。任何2或3从列表中index_search,table_scan,hash_scan。 Slave_rows_last_search_algorithm_used搜索算法:最近使用的奴隶来定位行基于行的复制(或哈希表,索引扫描) Slave_running:作为一个复制从这个服务器的状态(从I/O线程的状态) slave_transaction_retries:时代的奴隶SQL线程将重试事务的情况下,未能与死锁或经过锁等待超时,放弃之前停止 slave_type_conversions:控制复制从类型转换模式。价值是一个列表的零个或多个元素的列表:all_lossy,all_non_lossy。设置为不允许类型转换的主人和奴隶之间的空字符串。 sql_slave_skip_counter:从主人的从属服务器应该跳过事件数。与gtid复制不兼容。 sync_binlog同花顺:同步二进制日志到磁盘的每一#日事件后 sync_master_infomaster.info:同步磁盘每#日事件后 sync_relay_log继电器:同步日志到磁盘每#日事件后 sync_relay_log_inforelay.info:同步文件到磁盘的每一#日事件后
binlog-checksum二进制校验/日志:enable disable binlog-do-db限制到特定的数据库二进制日志: binlog_expire_logs_seconds二进制日志:清洗后这几秒 binlog_format:指定的二进制日志格式 binlog-ignore-db:告诉主人,对给定的数据库更新不应被记录到二进制日志 binlog-row-event-max-size事件:二进制日志最大大小 binlog-rows-query-log-events:可以使用基于行的记录时,行查询日志事件记录。默认情况下禁用。不允许在生产日志pre-5.6奴隶/读者。 Binlog_cache_disk_use:使用临时文件,而不是二进制日志缓存交易数 binlog_cache_size高速缓存的大小:在一个事务中保持二进制日志的SQL语句 Binlog_cache_use:那用临时的二进制日志缓存交易数 binlog_checksum二进制校验/日志:enable disable binlog_direct_non_transactional_updates更新:原因使用语句格式非事务性的发动机是直接写入二进制日志。使用前请参阅文档。 binlog_error_action:控制会发生什么当服务器无法写入二进制日志 binlog_group_commit_sync_delay:设置在同步前,交易盘等的微秒数 binlog_group_commit_sync_no_delay_count:设置等待指定的binlog_group_commit_sync_delay之前中止当前延迟交易的最大数量 binlog_max_flush_queue_time:多久前冲洗二进制日志读事务 binlog_order_commits:是否犯相同的顺序写入二进制日志 binlog_row_image:使用完整的或最小的图像时,记录行的变化 binlog_row_metadata:配置相关的元数据二进制记录使用基于行的记录在表量。 binlog_row_value_options:使二进制日志部分json更新基于行的复制。 binlog_rows_query_log_events:当真实,使测井在排排查询日志事件的日志模式。默认值是false。不允许在生产日志pre-5.6复制奴隶或其他读者。 Binlog_stmt_cache_disk_use:对非事务语句使用一个临时文件,而不是二进制日志语句缓存数 binlog_stmt_cache_size高速缓存的大小:在一个事务中保持二进制日志非事务性的陈述 Binlog_stmt_cache_use:,使用临时的二进制日志语句缓存报表数 binlog_transaction_dependency_tracking:依赖信息源(提交时间戳或交易写套),评估交易可以并行执行的多线程应用的奴隶。 binlog_transaction_dependency_history_size:行数哈希查找,保持交易的最后更新某些行。 Com_show_binlog_events:显示binlog事件报表数 Com_show_binlogs统计显示binlogs陈述: expire_logs_days二进制日志:清除后这几天 log_bin_basename:二进制日志文件的路径和名称 log-bin-trust-function-creators:如果等于0(默认值),然后,使用一个日志本,存储函数创建只允许具有超级权限的用户,只有不断的二进制日志功能创建 log-bin-use-v1-row-events第一个版本:使用二进制日志行事件 log_bin_use_v1_row_events:显示服务器使用的是1版本的二进制日志行事件 log_builtin_as_identified_by_password:是否记录创建/修改用户,格兰特在向后兼容的方式 master-verify-checksum因为主人检查校验:当读取二进制日志 master_verify_checksum:因为大师读取二进制日志校验 max-binlog-dump-events:通过调试和测试复制MySQL测试选项 max_binlog_cache_size:可以用来限制用于缓存多语句事务的总大小 max_binlog_size:二进制日志将自动旋转时的大小超过此值 max_binlog_stmt_cache_size:可以用来限制使用高速缓存中的所有非事务语句在事务期间的总大小 slave-sql-verify-checksum:因为奴隶检查校验当读取中继日志 slave_sql_verify_checksum因为从检查校验:当读取中继日志 sporadic-binlog-dump-fail:通过调试和测试复制MySQL测试选项 sql_log_bin:切换二进制日志 transaction_write_set_extraction:定义用于哈希写入事务期间的算法提取
SET
server-idserver-id=3
财产 价值 命令行格式 --show-slave-auth-info类型 布尔 默认值 FALSE显示从用户名和密码的输出 SHOW SLAVE HOSTS在主服务器上的奴隶开始的 --report-user和 --report-password选项
财产 价值 系统变量 auto_increment_increment范围 全球会议 动态 是 看到的是_ 提示应用 是 类型 整数 默认值 1最小值 1最大值 65535auto_increment_increment和 auto_increment_offset是用于掌握复制,可用于控制操作 汽车 专栏两变量的全局和会话值,每个可以假设1和65535之间的整数的包容。设置两变量的值为0的原因是设置为1,而其价值。试图设置两变量的值为整数,大于65535或小于0的原因是设置为65535,而其价值。试图设置值 auto_increment_increment或 auto_increment_offset一个非整数的值产生误差,以及变量的实际值不变。 笔记 auto_increment_increment目的是为使用MySQL集群,这是目前不支持MySQL 5.0。 这两个变量的影响 AUTO_INCREMENT列行为如下: auto_increment_increment控制连续列值之间的时间间隔。例如: MySQL的> SHOW VARIABLES LIKE 'auto_inc%';-------------------------- ------- | variable_name |价值| -------------------------- ------- | auto_increment_increment | 1 | | auto_increment_offset | 1 | -------------------------- ------- 2行集(0秒)MySQL > CREATE TABLE autoinc1-> (col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);查询行,0行受影响(0.04秒)MySQL > SET @@auto_increment_increment=10;查询好,为受影响的行(0.001秒)MySQL > SHOW VARIABLES LIKE 'auto_inc%';-------------------------- ------- | variable_name |价值| -------------------------- ------- | auto_increment_increment | 10 | | auto_increment_offset | 1 | -------------------------- ------- 2行集(0.01秒)MySQL > INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);查询行,4行受影响(0秒)记录:4份:0警告:0mysql > SELECT col FROM autoinc1;----- | Col | ----- | 1 | | 11 | | 21 | | 31 | ----- 4行集(0秒) auto_increment_offset确定为出发点 汽车 列值。考虑以下,假设这些语句被执行在同一会议上给出的描述为例 auto_increment_increment: MySQL的> SET @@auto_increment_offset=5;查询好,为受影响的行(0.001秒)MySQL > SHOW VARIABLES LIKE 'auto_inc%';-------------------------- ------- | variable_name |价值| -------------------------- ------- | auto_increment_increment | 10 | | auto_increment_offset | 5 | -------------------------- ------- 2行集(0秒)MySQL > CREATE TABLE autoinc2-> (col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);查询行,0行受影响(0.06秒)MySQL > INSERT INTO autoinc2 VALUES (NULL), (NULL), (NULL), (NULL);查询行,4行受影响(0秒)记录:4份:0警告:0mysql > SELECT col FROM autoinc2;----- | Col | ----- | 5 | | 15 | | 25 | | 35 | ----- 4行集(0.02秒) 当价值 auto_increment_offset大于 auto_increment_increment,价值 auto_increment_offset被忽略
如果这些变量的变化,然后新的行插入到表中包含一个 AUTO_INCREMENT柱,结果可能似乎有悖常理,因为系列 汽车 价值观是不考虑任何价值已经在柱计算,然后插入值系列中,大于最大值最小值存在的 AUTO_INCREMENT专栏该系列是这样计算的: auto_increment_offsetN× 【解释】:自我维持 哪里 N在系列[ 1,一个正整数2,3,…]。例如: MySQL的> SHOW VARIABLES LIKE 'auto_inc%';-------------------------- ------- | variable_name |价值| -------------------------- ------- | auto_increment_increment | 10 | | auto_increment_offset | 5 | -------------------------- ------- 2行集(0秒)MySQL > SELECT col FROM autoinc1;----- | Col | ----- | 1 | | 11 | | 21 | | 31 | -----四行集(0.001秒)MySQL > INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);查询行,4行受影响(0秒)记录:4份:0警告:0mysql > SELECT col FROM autoinc1;----- | Col | ----- | 1 | | 11 | | 21 | | 31 | | 35 | | 45 | | 55 | | 65 | ----- 8行集(0秒) 的幻觉 auto_increment_increment和 auto_increment_offset生成系列5 N×10,即[ 5, 15, 25,35, 45 ],。目前价值最高 Col 前柱 INSERT是日,和下一个可用的价值在 汽车 系列35,所以插入的值 col开始在这一点上,结果显示为 SELECT查询 这是不可能的限制这两个变量的影响,一个表;这些变量控制所有的行为 AUTO_INCREMENT柱 全部 在MySQL服务器表。如果任一变量的全局值设定,其影响持续到全球价值变化或通过设置会话值重写,直到 mysqld 重新启动。如果本地值设置,新的价值观的影响 AUTO_INCREMENT所有表,新的行由电流在会话期间用户插入的列的值,除非是在会话改变。 默认值 auto_increment_increment在1。这 第17.4.1.1,“复制和auto_increment” 财产 价值 系统变量 auto_increment_offset范围 全球会议 动态 是 看到的是_ 提示应用 是 类型 整数 默认值 1最小值 1最大值 65535这个变量的默认值为1。更多信息,见描述 auto_increment_increment笔记 auto_increment_offset目的是为使用MySQL集群,这是目前不支持MySQL 5.0。 财产 价值 系统变量 rpl_semi_sync_master_enabled范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF控制半同步复制是否在主机启用。启用或禁用插件,设置这个变量 ON或 关闭 (or 1 or 0),respectively .默认的是 OFF这个变量是只有安装主侧半同步复制可用的插件。 财产 价值 系统变量 rpl_semi_sync_master_timeout范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 10000以毫秒为单位控制多久主机等待一个提交从奴隶确认超时并恢复异步复制前一个值。默认值是10000(10秒)。 这个变量是只有安装主侧半同步复制可用的插件。 rpl_semi_sync_master_trace_level财产 价值 系统变量 rpl_semi_sync_master_trace_level范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 32半同步复制在痕量水平的掌握。定义了四个层次: 1 = general level (for example, time function failures)
16 = detail level (more verbose information)
32 = net wait level (more information about network waits)
64 = function level (information about function entry and exit)
这个变量是只有安装主侧半同步复制可用的插件。 rpl_semi_sync_master_wait_for_slave_count财产 价值 系统变量 rpl_semi_sync_master_wait_for_slave_count范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1最小值 1最大值 65535奴隶主的数量确认每笔交易之前必须接受。默认情况下 rpl_semi_sync_master_wait_for_slave_count是 一 半同步复制,即收益接收一个奴隶的确认后。表现最好的是,这个变量的值小。 例如,如果 rpl_semi_sync_master_wait_for_slave_count是 二 ,然后两奴隶必须在配置的超时时间承认交易收据 rpl_semi_sync_master_timeout对于半同步复制继续进行。如果不承认奴隶交易收据超时期间,主机恢复到正常复制。 笔记 这个变量是只有安装主侧半同步复制可用的插件。 rpl_semi_sync_master_wait_no_slave财产 价值 系统变量 rpl_semi_sync_master_wait_no_slave范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 ON控制主机是否在等待配置的超时时间 rpl_semi_sync_master_timeout到期,即使从计数下降到少于奴隶配置数量 rpl_semi_sync_master_wait_for_slave_count在超时期间 当价值 rpl_semi_sync_master_wait_no_slave是 打开(放) (默认),对奴隶的数量下降到低于它是允许的 rpl_semi_sync_master_wait_for_slave_count在超时期间。只要有足够的奴隶的超时时间到期之前确认交易,半同步复制下去。 当价值 rpl_semi_sync_master_wait_no_slave是 关闭 ,如果从计数下降到低于数量配置 rpl_semi_sync_master_wait_for_slave_count在任何时间配置的超时期间 rpl_semi_sync_master_timeout,主机恢复到正常复制。 这个变量是只有安装主侧半同步复制可用的插件。 rpl_semi_sync_master_wait_point财产 价值 系统变量 rpl_semi_sync_master_wait_point范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 AFTER_SYNC有效值 AFTER_SYNCAFTER_COMMIT这个变量控制点半同步复制等交易收据从确认之前返回一个状态到客户端提交事务。这些值是允许的: AFTER_SYNC(默认):大师写的每一笔交易的二进制日志和奴隶,并同步二进制日志到磁盘。主等待收到确认后同步奴隶交易。在收到确认,主提交事务的存储引擎并返回结果给客户端,然后才能进行。 AFTER_COMMIT:主写每个事务的二进制日志和奴隶,同步二进制日志,并提交事务的存储引擎。主等待交易收据确认提交后的奴隶。在收到确认,主人将结果返回给客户端,然后才能进行。
如下这些设置的复制特性不同: 与 AFTER_SYNC看,所有客户承诺同时交易:在它被承认的奴隶和致力于存储引擎在主。因此,所有的客户看到主人相同的数据。 在主失败的事件,在主所犯下的所有交易都复制到奴隶(保存到其中继日志)。一个崩溃的奴隶主和故障转移是无损因为奴隶是最新的。注意,然而,这总不能在这种情况下重新启动,必须丢弃,因为它的二进制日志可能包含未提交的事务,会导致奴隶冲突时表现的二进制日志恢复后。 与 AFTER_COMMIT,客户发行交易只在服务器向存储引擎和接收从确认得到的返回状态。提交之前,从确认后,客户可以在客户端看到的已提交的事务提交。 如果做错了事情,奴隶不处理事务,然后在主碰撞和故障转移事件的奴隶,这是可能的,这样的客户将看到的损失相对于他们所看到的在主数据。
这个变量是只有安装主侧半同步复制可用的插件。 与另外的 rpl_semi_sync_master_wait_point在MySQL 5.7版本相容约束的产生是由于它增加半同步接口版本:MySQL 5.7和更高的不半同步复制插件从旧版本的服务器,也没有从旧版本的服务器和MySQL 5.7和更高的半同步复制插件工作。
CHANGE MASTER TOSET
server-idmy.cnf
[mysqld]server-id=3
CHANGE MASTER TO
财产 价值 命令行格式 --log-slave-updates系统变量 log_slave_updates范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 (>= 8.0.3)ON默认值 (<= 8.0.2)OFF此选项使奴隶写的,从主服务器接收和奴隶的SQL线程执行的二进制日志更新自己的奴隶。二进制日志,由 --log-bin默认启用的是选项,还必须启用奴隶要记录更新。 --log-slave-updates默认是启用的,除非你指定 --skip-log-bin禁用二进制日志,在这种情况下,MySQL也禁用默认奴隶更新日志。如果你需要禁用从更新日志时启用二进制日志,指定 --skip-log-slave-updates--log-slave-updates使复制服务器被。例如,您可能想要建立复制服务器使用这样的安排: A -> B -> C
在这里, A作为奴隶的主人 B ,和 B作为奴隶的主人 C 。这个工作, B必须是主 和 一个奴隶。二进制日志和 --log-slave-updates启用选项,这是默认设置,更新收到 一 记录的 B其二进制日志,因此可以通过对 C 财产 价值 命令行格式 --master-info-file=file_name类型 文件名 默认值 master.info为掌握信息日志的名称,如 --master-info-repository=FILE是集。默认名称是 master.info 在数据目录 --master-info-repository=FILE现在已不再使用。关于掌握信息的日志信息,看 第17.2.4.2,“奴隶状态日志” 财产 价值 命令行格式 --master-retry-count=#过时的 是 类型 整数 默认值 86400最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295次奴隶试图放弃之前连接到主数。尝试重新连接时间间隔设定的 MASTER_CONNECT_RETRY期权的 CHANGE MASTER TO声明(默认为60)。能够被触发时,读取数据的时间根据奴隶 --slave-net-timeout选项默认值是86400。值为0表示 “ 无限的 “ ;奴隶试图连接永远 这个选项是过时的、将在未来的MySQL版本中删除。应用程序应该更新使用 MASTER_RETRY_COUNT期权的 CHANGE MASTER TO语句 财产 价值 命令行格式 --max-relay-log-size=#系统变量 max_relay_log_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 1073741824大小的服务器中继日志文件自动旋转。如果该值为零,继电器的日志是自动旋转时它的大小超过此值。如果这个值是零(默认),大小在中继日志旋转是由价值决定的 max_binlog_size。有关更多信息,参见 第17.2.4.1,“从中继日志” 对于中继日志的基本名称。服务器上添加一个数字后缀的基本名称创建日志文件序列继电器。 对于默认复制通道,中继日志的默认名称是基础 host_name-relay-bin,使用的主机名。对于非默认复制通道,中继日志的默认名称是基础 host_name中继站— channel,在那里 channel是记录在这个中继日志复制通道的名称。 中继日志文件的默认位置是数据目录。你可以使用 --relay-log选项指定一个替代的位置,通过对基地的名字加入领先的绝对路径名来指定一个不同的目录。 中继日志和继电器在复制服务器不能登录指数被给予相同的名称作为二进制日志和二进制日志索引,他们的名字是由指定的 --log-bin和 --log-bin-index选项服务器发出一个错误消息和不启动如果二进制日志和中继日志文件库名称将是相同的。 由于以何种方式MySQL解析服务器选项,如果指定此选项,您必须提供一个值; 默认的库名字只是如果期权实际上没有指定使用 。如果你使用 --relay-log如果没有指定值的选择,可能会导致意外的行为;这种行为取决于其他选项的应用,它们指定的顺序,以及他们是否是在命令行或在一个选项指定的文件。更多信息关于MySQL如何处理服务器选项,看 4.2.3节”指定程序选项” 如果指定此选项,指定的值也可以用来作为中继日志索引文件的基名称。你可以重写此行为,通过指定不同的中继日志索引文件的基名称的使用 --relay-log-index选项 当服务器读取索引文件的一个条目,它检查条目是否包含相对路径。如果是这样,该路径的相对与绝对路径替换设置使用 --relay-log选项一个绝对路径保持不变;在这种情况下,索引必须手动编辑启用新的路径被使用。此前,人工干预是必要时将二进制日志或中继日志文件。(错误# 11745230,错误# 12133) 你可能会发现 --relay-log用于执行以下任务的选择: 创建中继日志名字是独立的主机名称。 如果你需要把中继日志在一些地区以外的数据目录,因为你的中继日志往往是非常大的,你不想减少 max_relay_log_size通过使用磁盘间负载均衡的增长速度。
你可以获得中继日志文件名(路径)从 relay_log_basename系统变量 财产 价值 命令行格式 --relay-log-index=file_name系统变量 relay_log_index范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 为中继日志索引文件的名称。如果你不指定 --relay-log-index选项,但 --relay-log选项指定的值作为中继日志索引文件的默认名称。如果 中继日志 选项也没有指定,则默认复制通道,默认名称是 host_name-relay-bin.index,使用的主机名。对于非默认复制通道,默认名称是 host_name中继站— channel指数 ,在那里 channel是记录在这个中继日志索引复制通道的名称。 中继日志文件的默认位置是数据目录,或任何其他位置,被指定使用 --relay-log选项你可以使用 中继日志索引 选项指定一个替代的位置,通过对基地的名字加入领先的绝对路径名来指定一个不同的目录。 中继日志和继电器在复制服务器不能登录指数被给予相同的名称作为二进制日志和二进制日志索引,他们的名字是由指定的 --log-bin和 --log-bin-index选项服务器发出一个错误消息和不启动如果二进制日志和中继日志文件库名称将是相同的。 由于以何种方式MySQL解析服务器选项,如果指定此选项,您必须提供一个值; 默认的库名字只是如果期权实际上没有指定使用 。如果你使用 --relay-log-index如果没有指定值的选择,可能会导致意外的行为;这种行为取决于其他选项的应用,它们指定的顺序,以及他们是否是在命令行或在一个选项指定的文件。更多信息关于MySQL如何处理服务器选项,看 4.2.3节”指定程序选项” --relay-log-info-file=file_name财产 价值 命令行格式 --relay-log-info-file=file_name类型 文件名 默认值 relay-log.info对于中继日志文件的名称,如果 --relay-log-info-repository设置文件。默认名称是 relay-log.info 在数据目录 --relay-log-info-repository=FILE现在已不再使用。关于中继日志信息的日志信息,看 第17.2.4.2,“奴隶状态日志” 财产 价值 命令行格式 --relay-log-purge系统变量 relay_log_purge范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 TRUE禁用或启用自动清除中继日志就不再需要。默认值是1(启用)。这是一个全局变量,可以动态改变与 SET GLOBAL relay_log_purge =N。禁用中继日志清除时使用 --relay-log-recovery期权的风险数据的一致性,因此不安全。 财产 价值 命令行格式 --relay-log-recovery类型 布尔 默认值 FALSE使自动中继日志恢复后立即启动服务器。恢复过程将创建一个新的中继日志文件、初始化SQL线程位置这一新的中继日志,并初始化I/O线程SQL线程位置。从主然后继续中继日志阅读。这应该是用在复制从崩溃确保不可能损坏继电器日志处理。默认值是0(禁用)。 提供一个安全的奴隶,此选项必须启用(设置为1), --relay-log-info-repository必须设置为 表 ,和 relay-log-purge必须启用。使 --relay-log-recovery选择 relay-log-purge是残疾的风险,不被清除的文件读取中继日志,导致数据的不一致性,因此是不安全。看到 制作复制弹性意外停止 为更多的信息 使用多线程的奴隶时(换句话说 slave_parallel_workers大于0),如能在不一致的差距已从中继日志执行交易的发生顺序。使 --relay-log-recovery选项时有不一致导致错误的选项不起作用。在这种情况下,解决方案是问题 START SLAVE UNTIL SQL_AFTER_MTS_GAPS,以更一致的状态带来的服务器,然后发出 RESET SLAVE删除中继日志。看到 第17.4.1.34,“复制和事务不一致” 更多信息 财产 价值 命令行格式 --relay-log-space-limit=#系统变量 relay_log_space_limit范围 全球 动态 否 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295此选项将在总规模上的限制在所有继电器字节的奴隶的日志。值为0表示 “ 没有限制 “ 。这对于一个从服务器主机,具有有限的磁盘空间是有用的。当达到极限时,I/O线程停止读取二进制日志事件从主服务器到SQL线程已经赶上并删除一些不用的中继日志。注意,这个限制不是绝对的:在有些情况下,SQL线程需要更多的事件才可以删除中继日志。在这种情况下,I/O线程超过限制直到它变成可能的SQL线程删除一些中继日志,因为不这样做会导致死锁。你不应该 --relay-log-space-limit不到两倍的价值 --max-relay-log-size(或 --max-binlog-size如果 --max-relay-log-size0)。在这种情况下,有一个机会,I/O线程等待自由的空间,因为 --relay-log-space-limit超标,但SQL线程无中继日志清除,无法满足I/O线程。这迫使I/O线程忽略 --relay-log-space-limit暂时 财产 价值 命令行格式 --replicate-do-db=name类型 字符串 创建一个使用数据库的名称复制器。这样的过滤器也可以使用创建 CHANGE REPLICATION FILTER REPLICATE_DO_DB此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 -复制- DOB: channel_1: db_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 这种复制筛选精确的效果取决于是否基于或基于行的复制是使用语句。 基于语句的复制 告诉从SQL线程限制复制语句在默认的数据库(即,一个选择 USE)是 db_name。要指定多个数据库,多次使用此选项,一次为每个数据库;然而,这样做 不 复制跨数据库的报表等 UPDATEsome_db.some_tableSET foo='bar'而不同的数据库(或数据库)的选择。 警告 指定多个数据库的你 必须 使用此选项的多个实例。因为数据库名称不能包含逗号,如果你提供一个以逗号分隔的列表然后列表被视为一个单一的数据库的名称。 什么不工作,你可能希望使用基于语句的复制的一个例子:如果奴隶开始 --replicate-do-db=sales你的问题在主报表的 UPDATE语句 不 复制: USE prices; UPDATE sales.january SET amount=amount+1000;
这其中的主要原因 “ 检查只是默认的数据库 “ 行为是它知道它应该被复制的是仅从陈述困难(例如,如果你正在使用多个表 DELETE表或多个表 UPDATE陈述行为跨越多个数据库)。它也越来越快,而不是所有的数据库都没有需要检查只有默认的数据库。 基于行的复制 对奴隶的SQL线程限制复制数据库 db_name。只有表属于 db_name改变;当前数据库有无影响。假设从开始 --replicate-do-db=sales与基于行的复制效果,然后下面的语句是运行在主: USE prices;UPDATE sales.february SET amount=amount+100;
这个 february表中 特价 在从数据库改变按照 UPDATE声明;这是否 USE声明发表。然而,发行以下在主报表已经使用基于行的复制,当奴隶没有影响 --replicate-do-db=sales: USE prices;UPDATE prices.march SET amount=amount-25;
即使是停滞不前 USE prices改变了 使用销售 ,的 UPDATE声明的作用仍然不可复制。 在另一个重要的区别 --replicate-do-db处理基于语句的复制而不是基于行的复制发生在语句引用多个数据库。假设从开始 --replicate-do-db=db1,和下面的语句是在主执行: USE db1;UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
如果您使用的是基于语句的复制,然后从更新表。然而,使用基于行的复制时,只 table1在奴隶的影响;由于 表2 是在一个不同的数据库, table2在奴隶是没有改变的 UPDATE。现在假设,相反的 使用db1 声明一个 USE db4声明已被使用: USE db4;UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
在这种情况下,的 UPDATE语句会使用基于语句的复制当奴隶没有影响。然而,如果您使用的是基于行的复制, UPDATE会改变 表1 对奴隶,但不 table2换句话说,只有在指定的数据库表 --replicate-do-db改变默认的数据库的选择和对这种行为没有影响。 如果你需要跨数据库的更新工作,使用 --replicate-wild-do-table=db_name.%相反。看到 第17.2.5,“服务器如何评价复制过滤规则” 笔记 这个选项会影响复制在相同的方式, --binlog-do-db对二进制日志、效果以及如何复制格式 --replicate-do-db影响复制行为与记录格式的行为相同 --binlog-do-db财产 价值 命令行格式 --replicate-ignore-db=name类型 字符串 创建一个使用数据库的名称复制器。这样的过滤器也可以使用创建 CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 -先生-复制- DB: channel_1: db_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 指定要忽略多个数据库,多次使用此选项,一次为每个数据库。因为数据库名称不能包含逗号,如果你提供一个以逗号分隔的列表然后列表将被视为一个单一的数据库的名称。 与 --replicate-do-db,这过滤精确的效果取决于基或基于行的复制是使用语句,并在接下来的几个段落描述。 基于语句的复制 告诉从SQL线程不复制任何声明,默认的数据库(即,一个选择 USE)是 db_name基于行的复制 告诉从SQL线程不更新数据库中的任何表 db_name。默认的数据库没有影响。 当使用基于语句的复制,下面的例子不工作,你可能期望。假设从开始 --replicate-ignore-db=sales你的问题在主报表: USE prices;UPDATE sales.january SET amount=amount+1000;
这个 UPDATE陈述 是 在这种情况下,因为复制 --replicate-ignore-db仅适用于默认数据库(由 USE声明)。因为 特价 数据库在声明中明确规定,声明未被过滤。然而,使用基于行的复制时, UPDATE语句的作用 不 传播到奴隶的奴隶的副本 sales.january表是不变的;在这种情况, --replicate-ignore-db=sales起因 全部 使在师父的复制表的变化 sales数据库是由从忽视 你不应该如果你使用跨数据库的更新,你不希望这些更新被复制,使用此选项。看到 第17.2.5,“服务器如何评价复制过滤规则” 如果你需要跨数据库的更新工作,使用 --replicate-wild-ignore-table=db_name.%相反。看到 第17.2.5,“服务器如何评价复制过滤规则” 笔记 这个选项会影响复制在相同的方式, --binlog-ignore-db对二进制日志、效果以及如何复制格式 --replicate-ignore-db影响复制行为与记录格式的行为相同 --binlog-ignore-db--replicate-do-table=db_name.tbl_name财产 价值 命令行格式 --replicate-do-table=name类型 字符串 通过讲述从SQL线程限制复制到一个给定的表创建一个复制器。指定多个表,多次使用此选项,一次为每个表。本工程为跨数据库的更新和默认数据库的更新,在对比 --replicate-do-db。看到 第17.2.5,“服务器如何评价复制过滤规则” 。你也可以通过发布创建一个过滤器 CHANGE REPLICATION FILTER REPLICATE_DO_TABLE声明 此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 ——复制表: channel_1: db_name.tbl_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 此选项只影响报表,申请表。它不影响语句只适用于其他数据库对象,如存储过程。筛选报表存储程序操作,使用一个或一个以上的 --replicate-*-db选项 --replicate-ignore-table=db_name.tbl_name财产 价值 命令行格式 --replicate-ignore-table=name类型 字符串 通过讲述从SQL线程不复制任何声明,更新指定表创建一个复制器,即使任何其他表可能由同一语句更新。指定要忽略多个表,多次使用此选项,一次为每个表。本工程为跨数据库的更新,在对比 --replicate-ignore-db。看到 第17.2.5,“服务器如何评价复制过滤规则” 。你也可以通过发布创建一个过滤器 CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE声明 此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 ——复制忽略表: channel_1: db_name.tbl_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 此选项只影响报表,申请表。它不影响语句只适用于其他数据库对象,如存储过程。筛选报表存储程序操作,使用一个或一个以上的 --replicate-*-db选项 --replicate-rewrite-db=from_name->to_name财产 价值 命令行格式 --replicate-rewrite-db=old_name->new_name类型 字符串 告诉奴隶创造一个复制的过滤器,将默认的数据库(即,一个选择 USE)来 to_name如果它是 from_name在主。只有报表涉及到数据表的影响(不象 CREATE DATABASE, DROP DATABASE,和 ALTER DATABASE),and only if from_name在主人的默认数据库。指定多个重写,多次使用这个选项。服务器使用一个 from_name价值匹配。数据库名称的翻译是 之前 这个 --replicate-*规则测试。你也可以通过发布创建一个过滤器 CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB声明 如果你使用这个选项在命令行和 >性格是特别给你的命令解释器,报价的期权价值。例如: 内核> mysqld --replicate-rewrite-db="olddb->newdb"此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。指定频道名称后跟一个冒号,然后通过过滤器规格。第一个冒号被解释为一个分离器,任何后续的冒号被解释为文本的颜色。例如,配置信道滤波器对信道指定特定复制 channel_1,使用: 内核> mysqld --replicate-rewrite-db=channel_1:db_name1->db_name2如果你用冒号而不指定通道名称选项配置为默认的复制通道复制器。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 语句中表名符合数据库名称使用此选项时不使用表级复制过滤选项,如工作 --replicate-do-table。假设我们有一个数据库命名 一 在主,一个名为 b对奴隶,每一个表 T ,并已开始掌握 --replicate-rewrite-db='a->b'。在稍后的时间点,我们执行 DELETE FROM a.t。在这种情况下,没有相关的过滤规则的作品,在这里显示的原因: --replicate-do-table=a.t没有工作,因为从表 T 在数据库 b--replicate-do-table=b.t不匹配的原始报表等被忽略。 --replicate-do-table=*.t处理相同 --replicate-do-table=a.t,从而不工作,要么
同样,该 --replication-rewrite-db选项不跨数据库更新工作。 财产 价值 命令行格式 --replicate-same-server-id类型 布尔 默认值 FALSE用于从服务器。通常你应该使用设置为默认值,以防止无限循环的循环复制造成的。如果设置为-1,奴隶不跳过有自己的服务器ID。正常的事件,这是只有在罕见的配置有用。该选项不能设置为1时 --log-slave-updates启用,这是默认的 默认情况下,从I/O线程不写入二进制日志事件的中继日志如果他们有奴隶的服务器ID(这种优化有助于节省磁盘使用)。如果你想使用 --replicate-same-server-id,一定要开始从这个选项在您做出从读自己的事件,你要从SQL线程执行。 --replicate-wild-do-table=db_name.tbl_name财产 价值 命令行格式 --replicate-wild-do-table=name类型 字符串 创建一个复制筛选告诉奴隶线程限制复制语句在任何更新的表匹配指定的数据库和表名模式。模式可以包含 %和 _ 通配符,具有同样的含义 LIKE模式匹配算子。指定多个表,多次使用此选项,一次为每个表。本工程为跨数据库的更新。看到 第17.2.5,“服务器如何评价复制过滤规则” 。你也可以通过发布创建一个过滤器 CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE声明 此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 ——复制野生做表: channel_1: db_name.tbl_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 此选项适用于表,视图和触发器。它不适用于存储过程和函数,或事件。过滤语句对后者的对象操作,使用一个或一个以上的 --replicate-*-db选项 作为一个例子, --replicate-wild-do-table=foo%.bar%只复制更新,使用表所在的数据库名称的开始 Foo 和表的名字开始 bar如果表名模式 %,它匹配任何表名和选项同样适用于数据库级的语句( CREATE DATABASE, DROP DATABASE,和 ALTER DATABASE)。例如,如果你使用 --replicate-wild-do-table=foo%.%数据库级的语句,如果数据库名称相匹配的模式复制 foo % 包括在数据库或表名称图案文字的通配符,逃避加上一个反斜杠。例如,复制所有的数据库表名 my_own%db,但不可复制的表的 my1ownaabcdb 数据库,You should Escape the _和 % 像这样的角色: --replicate-wild-do-table=my\_own\%db。如果你使用这个选项在命令行上,您可能需要双反斜杠或报价的期权价值,取决于你的命令解释器。例如,与 猛击 内核,你需要的类型 --replicate-wild-do-table=my\\_own\\%db--replicate-wild-ignore-table=db_name.tbl_name财产 价值 命令行格式 --replicate-wild-ignore-table=name类型 字符串 创建一个复制器使从属线程复制了一份声明,任何表匹配给定的通配符。指定要忽略多个表,多次使用此选项,一次为每个表。本工程为跨数据库的更新。看到 第17.2.5,“服务器如何评价复制过滤规则” 。你也可以通过发布创建一个过滤器 CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE声明 此选项支持通道特异性复制的过滤器,使多源复制奴隶使用特定的滤波器对不同来源。配置一个特定渠道复制过滤通道命名 channel_1使用 ——复制野生忽略: channel_1: db_name.tbl_name。在这种情况下,第一个冒号被解释为一个分离器和随后的文字冒号冒号。看到 第17.2.5.4,“复制通道滤波器” 更多信息 笔记 全球复制器不能用在一个MySQL服务器实例配置为组复制,因为有些服务器过滤交易将使集团无法达成一致的状态协议。通道特定复制过滤器可用于复制的通道没有直接参与组的复制,如其中一组成员也作为一个奴隶主,是一个复制组外。他们不能用对 group_replication_applier或 group_replication_recovery 频道 作为一个例子, --replicate-wild-ignore-table=foo%.bar%不会复制更新,使用表所在的数据库名称的开始 Foo 和表的名字开始 bar。有关如何匹配的工作信息,看到的描述 --replicate-wild-do-table选项的规则,包括选择价值字面的通配符是相同的 --replicate-wild-ignore-table也. 财产 价值 命令行格式 --report-host=host_name系统变量 report_host范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 主机名称或IP地址的奴隶是奴隶主在注册报告。这个值出现在输出 SHOW SLAVE HOSTS在主服务器上。如果你不想做奴隶与主人登记本身把值设置。 笔记 充分掌握简单地阅读从IP地址的TCP/IP套接字连接后是不是奴隶。由于NAT和路由问题,IP可能不能从主或其他主机连接到奴隶。 财产 价值 命令行格式 --report-password=name系统变量 report_password范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 奴隶的账号密码被报道在奴隶主登记。这个值出现在输出 SHOW SLAVE HOSTS在主服务器上,如果主人是开始 --show-slave-auth-info虽然这可能意味着其他选项的名称, --report-password没有连接到MySQL用户权限系统,所以不一定是(或可能)为MySQL复制用户帐户的密码相同。 财产 价值 命令行格式 --report-port=#系统变量 report_port范围 全球 动态 否 看到的是_ 提示应用 否 类型 整数 默认值 [slave_port]最小值 0最大值 65535TCP/IP端口号连接到奴隶,是奴隶主在注册报告。这只有当奴隶是听非默认端口或如果你有从主或其他客户从一个特殊的隧道。如果你不确定,不要使用此选项。 此选项的默认值是实际使用的奴隶的端口号(bug # 13333431)。这也显示默认值 SHOW SLAVE HOSTS财产 价值 命令行格式 --report-user=name系统变量 report_user范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 奴隶的帐户的用户名被报道在奴隶主登记。这个值出现在输出 SHOW SLAVE HOSTS在主服务器上,如果主人是开始 --show-slave-auth-info虽然这可能意味着其他选项的名称, --report-user没有连接到MySQL用户权限系统,所以不一定是(或可能)作为MySQL复制的用户帐户名称相同。 财产 价值 命令行格式 --slave-checkpoint-group=#类型 整数 默认值 512最小值 32最大值 524280块的大小 8套成交,可以检查点操作之前的一个多线程处理的最大数量的奴隶来显示其状态更新 SHOW SLAVE STATUS。设置此选项对奴隶的多线程是不影响功能。 这个选项结合作品 --slave-checkpoint-period在这样一个选项,当超过极限,检查站执行计数器跟踪交易数量从上一个检查点复位时间。 允许的最小值,这个选项是32,除非服务器建成使用 -DWITH_DEBUG在这种情况下,最小值为1。有效值是8的倍数;你可以将它设置为一个值,是不是这么多,但是服务器发到下一个8之前储存的价值。( 例外 :没有这样的舍入的调试服务器执行。)无论服务器如何建,默认值是512,和最大允许值为524280。 财产 价值 命令行格式 --slave-checkpoint-period=#类型 整数 默认值 300最小值 1最大值 4G设置最大时间(以毫秒为单位)是允许一个检查点操作之前,通过被称为显示更新的一个多线程的奴隶的地位 SHOW SLAVE STATUS。设置此选项对奴隶的多线程是不影响功能。 这个选项结合作品 --slave-checkpoint-group在这样一个选项,当超过极限,检查站执行计数器跟踪交易数量从上一个检查点复位时间。 允许的最小值,这个选项是1,除非服务器建成使用 -DWITH_DEBUG,在这种情况下,最小值为0。无论服务器如何建,默认值是300,和可能的最大值是4294967296(4GB)。 财产 价值 命令行格式 --slave-parallel-workers=#类型 整数 默认值 0最小值 0最大值 1024使奴隶和多线程并行执行的复制事务集奴隶施放的线程数。当该值是一个大于0的数,奴隶是一个多线程的奴隶与指定数量的应用线程,再加上一个协调线程管理。如果你正在使用多个复制的通道,每个通道都有这个线程数。 重试交易支持多线程是一个奴隶启用时。什么时候 slave_preserve_commit_order=1在奴隶交易,外化在同一命令奴隶一样出现在奴隶的中继日志。在交易分配线程的方式配置的应用 --slave-parallel-type禁用并行执行,将此选项设置为0,这给奴隶一个应用线程没有协调线程。使用此设置的 --slave-parallel-type和 slave_preserve_commit_order选项没有效果而被忽略。 --slave-pending-jobs-size-max=#财产 价值 命令行格式 --slave-pending-jobs-size-max=#类型 整数 默认值 (>= 8.0.12)128M默认值 (<= 8.0.11)16M最小值 1024最大值 16EiB块的大小 1024多线程的奴隶,这个选项设置的最大内存量(以字节为单位)提供给奴隶工人队列举行活动尚未应用。设置此选项对奴隶的多线程是不影响功能。 此选项的最小可能值是1024字节;默认为128MB。可能的最大值是18446744073709551615(16 exbibytes)。是不是1024字节的倍数的值向下舍入到下一个1024字节的数据被存储之前。 这个变量的值是一个软限位,可以设置匹配的正常工作。如果一个非常大的事件超过这一规模,交易直到所有奴隶工人有空队列,然后处理。所有后续的交易才举行大型的交易已经完成。 财产 价值 命令行格式 --skip-slave-start类型 布尔 默认值 FALSE告诉从服务器没有启动从属线程服务器启动时。在线程开始后,使用 START SLAVE声明 --slave_compressed_protocol={0|1}财产 价值 命令行格式 --slave-compressed-protocol系统变量 slave_compressed_protocol范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF如果此选项设置为-1,如果奴隶和主人的支持为奴隶/主协议使用压缩。默认值是0(不压缩)。 财产 价值 命令行格式 --slave-load-tmpdir=dir_name系统变量 slave_load_tmpdir范围 全球 动态 否 看到的是_ 提示应用 否 类型 目录名称 默认值 /tmp在奴隶创建临时文件的目录的名称。这个选项默认是相等的价值 tmpdir系统变量。当从SQL线程复制 LOAD DATA INFILE声明,它提取的文件可从中继日志到临时文件加载,然后加载到表。如果文件装在主是巨大的,对奴隶的临时文件是巨大的,太。因此,最好用这个选项告诉奴隶把临时文件目录中的一些位于文件系统,有很多可用的空间。在这种情况下,中继日志是巨大的,所以你可能也要使用 --relay-log日志文件系统选项,将继电器。 这个选项指定的目录必须位于一个基于磁盘的文件系统(不是基于内存的文件系统)因为临时文件用于复制 LOAD DATA INFILE必须在机器重新启动。目录也不应该是一个被操作系统的启动过程。 slave-max-allowed-packet=bytes财产 价值 命令行格式 --slave-max-allowed-packet=#类型 整数 默认值 1073741824最小值 1024最大值 1073741824这个选项设置最大包大小以字节为单位,从SQL和I/O线程可以处理。它是可能的复制写入二进制日志事件的时间比其 max_allowed_packet设置一旦添加事件标头。设置 slave_max_allowed_packet必须大于 max_allowed_packet设置在主,因此采用基于行的复制大更新而不导致复制失败。 相应的服务器变量 slave_max_allowed_packet总是有一个值,是一个正整数的1024倍;如果你将它设置为一定值,不这么多,该值将自动向下舍入到下一个最高的1024的倍数。(例如,如果你启动服务器 --slave-max-allowed-packet=10000,使用的值是9216;以0为值使1024用于截断。)就是在这样的情况下发出警告。 最大值(默认)值为1073741824(1 GB);最低的是1024。 财产 价值 命令行格式 --slave-net-timeout=#系统变量 slave_net_timeout范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 60最小值 1等待更多的数据从奴隶认为连接断开的前主人的秒数,中止阅读,并尝试重新连接。第一重试超时后立即发生。重试之间的间隔是由 MASTER_CONNECT_RETRY选择的 CHANGE MASTER TO声明,并尝试重新连接的数量是有限的 --master-retry-count选项默认值是60秒(一分钟)。 财产 价值 命令行格式 --slave-parallel-type=type类型 枚举 默认值 DATABASE有效值 DATABASELOGICAL_CLOCK使用多线程时(奴隶 slave_parallel_workers大于0),此选项指定用来决定哪些交易可以并行执行的奴隶政策。这个选项对奴隶的多线程是不影响功能。可能的值: LOGICAL_CLOCK:这是相同的二进制日志组部分在主提交并行应用在奴隶交易。事务之间的依赖关系是基于时间戳提供额外的并行可能跟踪。当这个值设置,这 binlog_transaction_dependency_tracking系统变量可用于主指定写是用来代替时间戳的并行化,如果写集可供交易,给出了改进的结果相比,时间戳。 DATABASE更新:交易不同数据库的并行应用。如果数据被分割成多个数据库被更新的同时就掌握了这是唯一适当的价值。必须没有跨数据库的约束,这种约束可能受到侵犯的奴隶。
什么时候 slave_preserve_commit_order=1是,你只能使用 logical_clock 如果你使用多层次的复制拓扑的奴隶, LOGICAL_CLOCK可实现各层次的奴隶离主并行不。你可以利用这一效应降低 binlog_transaction_dependency_tracking在指定写集代替并行化在可能的时间戳的主人。 slave-rows-search-algorithms=list财产 价值 命令行格式 --slave-rows-search-algorithms=list类型 配置 默认值 (>= 8.0.2)INDEX_SCAN,HASH_SCAN默认值 (<= 8.0.1)TABLE_SCAN,INDEX_SCAN有效值 TABLE_SCAN,INDEX_SCANINDEX_SCAN,HASH_SCANTABLE_SCAN,HASH_SCANTABLE_SCAN,INDEX_SCAN,HASH_SCAN(等值的索引扫描,Hash San Scan) 当制备批次行基于行的记录和复制,这个选项控制如何行搜索匹配,是否使用散列使用主键或唯一键搜索,其他一些关键的,或没有在所有的关键。这个选项设置为初始值 slave_rows_search_algorithms系统变量 指定一个以逗号分隔的列表中有2(或3)从列表中的值 INDEX_SCAN, table_scan , HASH_SCAN。列表不需要引用,但不能包含空格,是否用引号。可能的组合(列表)和它们的影响如下表所示: 使用索引值/选项 INDEX_SCAN,HASH_SCAN或 index_scan,table_scan,hash_scan INDEX_SCAN,TABLE_SCANTABLE_SCAN,HASH_SCANprimary key或独特的关键 索引扫描 索引扫描 哈希索引扫描 (其他)的密钥 哈希索引扫描 索引扫描 哈希索引扫描 没有索引 哈希扫描 表扫描 哈希扫描 该算法是在列表中指定的顺序并不使它们显示的顺序有什么不同 SELECT或 SHOW VARIABLES声明(如用于表只是证明以前相同)。 默认值是 INDEX_SCAN,HASH_SCAN。在这种设置下,哈希是用于任何搜索不使用主键或唯一键。指定 index_scan,table_scan,hash_scan 具有相同的效果作为指定 INDEX_SCAN,HASH_SCAN给力的散列 全部 搜索,设置这个选项 TABLE_SCAN,HASH_SCAN删除散列,设置这个选项 TABLE_SCAN,INDEX_SCAN。这样设置后,所有的搜索,可以使用索引要使用它们,没有任何指标使用表搜索扫描。
有可能这个选项指定单个值,但这并不是最优的,因为设置一个值,算法只使用限制搜索。特别是,设置 INDEX_SCAN一个人是不推荐的,因为,如果没有指数是目前的情况下,搜索是根本无法找到的行。 笔记 只有一个性能上的优势 INDEX_SCAN和 hash_scan 如果行事件足够大。行事件的大小配置使用 --binlog-row-event-max-size。例如,假设一个 DELETE声明中删除25000行生成大 delete_row_event 事件在这种情况下,如果 slave_rows_search_algorithms是集 index_scan 或 HASH_SCAN有一个性能的改善。然而,如果有25000 DELETE报表,每一个都是在独立的事件,然后设置为代表 slave_rows_search_algorithms到 index_scan 或 HASH_SCAN没有提供性能改进在执行这些单独的事件。 --slave-skip-errors=[err_code1,err_code2,...|all|ddl_exist_errors]财产 价值 命令行格式 --slave-skip-errors=name系统变量 slave_skip_errors范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 默认值 OFF有效值 OFF[list of error codes]allddl_exist_errors通常情况下,复制停止在奴隶中发生错误时,它会给你机会去解决不一致性的数据手动。此选项将使从SQL线程继续复制语句时返回的任何错误上市的期权价值。 不要使用这个选项,除非你完全理解你为什么得到错误。如果你复制安装程序和客户端程序没有错误,和MySQL本身没有错误,错误,停止复制,应该永远不会发生。乱用此选项的结果奴隶成为无可救药的同步性的大师,你不知道为什么发生的。 错误代码,你应该利用你从错误日志和输出的错误信息提供的号码 SHOW SLAVE STATUS附录B, 错误,错误代码,及常见问题 ,列出服务器错误代码。 速记的价值 ddl_exist_errors相当于错误代码列表 1007100810501051105410601061106810941146 你也可以(但不应擅自使用的价值) all使奴隶忽略所有的错误信息和保持下去不管发生什么。不用说,如果你使用 全部 ,有关于数据的完整性没有保证。请不要抱怨(或文件错误报告)在这种情况下,如果奴隶的数据是不接近它的主人。 你已经被警告 实例: --slave-skip-errors=1062,1053 --slave-skip-errors=all --slave-skip-errors=ddl_exist_errors
--slave-sql-verify-checksum={0|1}财产 价值 命令行格式 --slave-sql-verify-checksum=value类型 布尔 默认值 1有效值 01当启用此选项,从检查校验和从中继日志阅读,在不匹配的事件,从停止错误。
财产 价值 命令行格式 --abort-slave-event-count=#类型 整数 默认值 0最小值 0当这个选项被设置为一个正整数 value除了0(默认值)对复制行为如下:当奴隶的SQL线程已启动, value事件日志可以执行;之后,从SQL线程不接收任何事件,就像从主网络连接被切断。从线程继续运行,并输出 SHOW SLAVE STATUS显示器 是 在两 Slave_IO_Running和 slave_sql_running 列,但没有进一步的事件是从中继日志读取。 --disconnect-slave-event-count财产 价值 命令行格式 --disconnect-slave-event-count=#类型 整数 默认值 0
mysql
--master-info-repository={TABLE|FILE}财产 价值 命令行格式 --master-info-repository=FILE|TABLE类型 字符串 默认值 (>= 8.0.2)TABLE默认值 (<= 8.0.1)FILE有效值 FILETABLE此选项决定从服务器日志的主人翁地位和连接信息,InnoDB表中 mysql数据库,或者在数据目录中的文件。 默认设置是 TABLE。作为一个InnoDB表,主日志命名 mysql.slave_master_info 。这个 TABLE设置时需要多个复制通道配置。 这个 FILE设置是过时的,并将在未来的版本中删除。作为一个文件,主日志命名 master.info 默认情况下,你可以改变这个名字的使用 --master-info-file选项 对于这个奴隶状态日志的位置设置的设置对效果有直接的影响 sync_master_info系统变量。你只能改变设置时没有复制线程执行。 --relay-log-info-repository={TABLE|FILE}财产 价值 命令行格式 --relay-log-info-repository=FILE|TABLE类型 字符串 默认值 (>= 8.0.2)TABLE默认值 (<= 8.0.1)FILE有效值 FILETABLE此选项决定从服务器日志中记录一个中继位置,InnoDB表中 mysql数据库,或者在数据目录中的文件。 默认设置是 TABLE。作为一个InnoDB表,中继日志信息日志命名 mysql.slave_relay_log_info 。这个 TABLE设置时需要多个复制通道配置。这个 表 对于中继日志信息的日志设置也需要复制弹性意外停止,这 --relay-log-recovery必须启用。看到 制作复制弹性意外停止 更多信息 这个 FILE设置是过时的,并将在未来的版本中删除。作为一个文件,中继日志日志命名 relay-log.info 默认情况下,你可以改变这个名字的使用 --relay-log-info-file选项 对于这个奴隶状态日志的位置设置的设置对效果有直接的影响 sync_relay_log_info系统变量。你只能改变设置时没有复制线程执行。
SET
财产 价值 命令行格式 --init-slave=name系统变量 init_slave范围 全球 动态 是 看到的是_ 提示应用 否 类型 字符串 这个变量是相似的 init_connect,但是是一个字符串是由每次SQL线程开始从服务器上执行。该字符串的格式为相同 init_connect变量。这一变量的设置生效以后 START SLAVE声明. 笔记 SQL线程发送一个确认给客户之前执行 init_slave。因此,它不能保证 init_slave已经执行的时候 START SLAVE退货看到 第13.4.2.6,“开始从语法” 为更多的信息 财产 价值 系统变量 log_slow_slave_statements范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF当慢查询日志启用,这个变量使得已经超过查询日志 long_query_time秒的奴隶执行。设置这个变量没有直接的影响。该变量的状态适用于所有后续 START SLAVE声明. 注意:所有报表登录在主行格式将不会被记录在奴隶的慢日志,即使 log_slow_slave_statements启用 财产 价值 命令行格式 --master-info-repository=FILE|TABLE系统变量 master_info_repository范围 全球 动态 是 看到的是_ 提示应用 否 类型 字符串 默认值 (>= 8.0.2)TABLE默认值 (<= 8.0.1)FILE有效值 FILETABLE这一变量的设置决定是否从服务器日志的主人翁地位和连接信息,InnoDB表中 mysql数据库,或者在数据目录中的文件。 默认设置是 TABLE。作为一个InnoDB表,主日志命名 mysql.slave_master_info 。这个 TABLE设置时需要多个复制通道配置。 这个 FILE设置是过时的,并将在未来的版本中删除。作为一个文件,主日志命名 master.info 默认情况下,你可以改变这个名字的使用 --master-info-file选项 对于这个奴隶状态日志的位置设置的设置对效果有直接的影响 sync_master_info系统变量。你只能改变设置时没有复制线程执行。 财产 价值 命令行格式 --max-relay-log-size=#系统变量 max_relay_log_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 1073741824如果用复制的奴隶的中继日志导致当前日志文件的大小超过此变量的值,从旋转的中继日志(关闭当前文件并打开下一个)。如果 max_relay_log_size0、服务器使用 max_binlog_size对于二进制日志和中继日志。如果 max_relay_log_size大于0,这限制了中继日志的大小,使你的日志有不同的尺寸。你必须设置 max_relay_log_size4096个字节和1GB之间(含),或0。默认值是0。看到 第17.2.2,“复制的实施细则》 中继日志文件的基名称,没有路径,没有文件扩展名。对于默认复制通道,中继日志的默认名称是基础 host_name-relay-bin。对于非默认复制通道,中继日志的默认名称是基础 host_name中继站— channel,在那里 channel是记录在这个中继日志复制通道的名称。 财产 价值 系统变量 relay_log_basename范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 默认值 datadir + '/' + hostname + '-relay-bin'持名和完整路径中继日志文件。 财产 价值 命令行格式 --relay-log-index系统变量 relay_log_index范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 默认值 *host_name*-relay-bin.index对于默认复制通道的中继日志索引文件的名称。默认名称是 host_name-relay-bin.index财产 价值 命令行格式 --relay-log-info-file=file_name系统变量 relay_log_info_file范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 默认值 relay-log.info继电器的日志信息的日志的名称,当 relay_log_info_repository=FILE是集。默认名称是 relay-log.info 在数据目录 relay_log_info_repository=FILE现在已不再使用 财产 价值 系统变量 relay_log_info_repository范围 全球 动态 是 看到的是_ 提示应用 否 类型 字符串 默认值 (>= 8.0.2)TABLE默认值 (<= 8.0.1)FILE有效值 FILETABLE这一变量的设置决定是否从服务器日志中记录一个中继位置,InnoDB表中 mysql数据库,或者在数据目录中的文件。 默认设置是 TABLE。作为一个InnoDB表,中继日志信息日志命名 mysql.slave_relay_log_info 。这个 TABLE设置时需要多个复制通道配置。这个 表 对于中继日志信息的日志设置也需要复制弹性意外停止,这 --relay-log-recovery必须启用。看到 制作复制弹性意外停止 更多信息 这个 FILE设置是过时的,并将在未来的版本中删除。作为一个文件,中继日志日志命名 relay-log.info 默认情况下,你可以改变这个名字的使用 --relay-log-info-file选项 对于这个奴隶状态日志的位置设置的设置对效果有直接的影响 sync_relay_log_info系统变量。你只能改变设置时没有复制线程执行。 财产 价值 命令行格式 --relay-log-purge系统变量 relay_log_purge范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 TRUE禁用或启用自动清除中继日志文件就不再需要。默认值是1( ON) 财产 价值 命令行格式 --relay-log-recovery系统变量 relay_log_recovery范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 FALSE使自动中继日志恢复后立即启动服务器。恢复过程将创建一个新的中继日志文件、初始化SQL线程位置这一新的中继日志,并初始化I/O线程SQL线程位置。从主然后继续中继日志阅读。这个全局变量是只读的;它的价值可以从奴隶与改变 --relay-log-recovery选项,可在复制从崩溃确保不可能损坏继电器的日志进行处理后,必须用以保证安全的奴隶。默认值是0(禁用)。 这个变量也与 relay-log-purge控制清除日志,当他们不再需要。使 --relay-log-recovery选择 relay-log-purge是残疾的风险,不被清除的文件读取中继日志,导致数据的不一致性,因此是不安全。 什么时候 relay_log_recovery启用和奴隶已经停止,由于在多线程模式下运行时遇到错误,你可以使用 START SLAVE UNTIL SQL_AFTER_MTS_GAPS确保所有缝隙处理后,切换到单线程模式或执行 改变主 声明 财产 价值 命令行格式 --relay-log-space-limit=#系统变量 relay_log_space_limit范围 全球 动态 否 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295空间的最大使用量为所有中继日志。 财产 价值 命令行格式 --report-host=host_name系统变量 report_host范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 的价值 --report-host选项 财产 价值 命令行格式 --report-password=name系统变量 report_password范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 的价值 --report-password选项不一样的使用MySQL复制的用户帐户的密码。 财产 价值 命令行格式 --report-port=#系统变量 report_port范围 全球 动态 否 看到的是_ 提示应用 否 类型 整数 默认值 [slave_port]最小值 0最大值 65535的价值 --report-port选项 财产 价值 命令行格式 --report-user=name系统变量 report_user范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 的价值 --report-user选项不一样的MySQL复制的用户帐户的名称。 财产 价值 命令行格式 --rpl-read-size=#介绍 8.0.11 系统变量 rpl_read_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 8192最小值 8192最大值 4294967295这个 rpl_read_size系统变量控制的最小数据量的字节读取二进制日志文件和中继日志文件。如果重磁盘I/O活动,这些文件是阻碍对数据库的性能,增加了阅读的大小可以减少文件读取和I / O档当文件数据不被操作系统缓存。 最小值和默认值 rpl_read_size是8192字节。该值必须是4KB的多。注意,这个值的大小的缓冲区分配给每个线程读取二进制日志和中继日志文件,包括转储线程对奴隶主人和协调线程。设置较大的值,因此可能有对于服务器内存消耗的影响。 财产 价值 系统变量 rpl_semi_sync_slave_enabled范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF控制是否启用半同步复制是奴隶。启用或禁用插件,设置这个变量 ON或 关闭 (or 1 or 0),respectively .默认的是 OFF这个变量是只有安装从侧半同步复制可用的插件。 rpl_semi_sync_slave_trace_level财产 价值 系统变量 rpl_semi_sync_slave_trace_level范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 32半同步复制在痕量水平的奴隶。看到 rpl_semi_sync_master_trace_level《permissible值。 这个变量是只有安装从侧半同步复制可用的插件。 财产 价值 命令行格式 --rpl-stop-slave-timeout=seconds系统变量 rpl_stop_slave_timeout范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 31536000最小值 2最大值 31536000你可以控制的时间长度(秒), STOP SLAVE等待超时设置此变量之前。这可以用来避免死锁之间 停止奴隶 和其他奴隶的SQL语句中使用不同的客户端连接到奴隶。 最大值和默认值 rpl_stop_slave_timeout是31536000秒(1年)。最小为2秒。更改此变量生效以后 STOP SLAVE声明. 这个变量只影响客户端的问题 STOP SLAVE声明。当超时达成,发行客户端返回一个错误消息,说明命令的执行是不完整的。然后客户端停止等待线程停止奴隶,但奴隶线程继续停止,和 停止奴隶 教学效果仍在。一旦从线程不再忙碌的 STOP SLAVE执行语句和从站 财产 价值 命令行格式 --slave-allow-batching系统变量 slave_allow_batching范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 off是否启用批量更新复制的奴隶。 设置这个变量的影响只有当使用复制的 NDB存储引擎;在MySQL服务器8,这是目前并没有。有关更多信息,参见 从NDB集群复制(单复制通道) 财产 价值 命令行格式 --slave-checkpoint-group=#系统变量 slave_checkpoint_group=#范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 512最小值 32最大值 524280块的大小 8套成交,可以检查点操作之前的一个多线程处理的最大数量的奴隶来显示其状态更新 SHOW SLAVE STATUS。设置这个变量对奴隶的多线程是不影响功能。设置这个变量没有直接的影响。该变量的状态适用于所有后续 START SLAVE命令 这个变量结合的作品 slave_checkpoint_period在这样一个系统变量,当超过极限,检查站执行计数器跟踪交易数量从上一个检查点复位时间。 允许的最小值,这个变量是32,除非服务器建成使用 -DWITH_DEBUG在这种情况下,最小值为1。有效值是8的倍数;你可以将它设置为一个值,是不是这么多,但是服务器发到下一个8之前储存的价值。( 例外 :没有这样的舍入的调试服务器执行。)无论服务器如何建,默认值是512,和最大允许值为524280。 财产 价值 命令行格式 --slave-checkpoint-period=#系统变量 slave_checkpoint_period=#范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 300最小值 1最大值 4G设置最大时间(以毫秒为单位)是允许一个检查点操作之前,通过被称为显示更新的一个多线程的奴隶的地位 SHOW SLAVE STATUS。设置这个变量对奴隶的多线程是不影响功能。这个变量设置立即生效,所有复制的渠道,包括运行通道。 这个变量结合的作品 slave_checkpoint_group在这样一个系统变量,当超过极限,检查站执行计数器跟踪交易数量从上一个检查点复位时间。 允许的最小值,这个变量是1,除非服务器建成使用 -DWITH_DEBUG,在这种情况下,最小值为0。无论服务器如何建,默认值是300,和可能的最大值是4294967296(4GB)。 财产 价值 命令行格式 --slave-compressed-protocol系统变量 slave_compressed_protocol范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF是否当奴隶和主人都支持使用奴隶/主协议压缩。更改此变量采取后续连接尝试的效果;这包括发卡后 START SLAVE声明,以及由运行的I/O线程重新连接(例如发卡后 改变主master_retry_count statement)。 财产 价值 命令行格式 --slave-exec-mode=mode系统变量 slave_exec_mode范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 IDEMPOTENT(NDB) STRICT(其他) 有效值 IDEMPOTENTSTRICT控制如何从线程解决冲突和错误在复制。 IDEMPOTENT模式使得重复关键的抑制和无钥匙上发现的错误; 严格 没有这种抑制的发生 IDEMPOTENT模式是用在多主复制,循环复制,和其他一些特殊的复制方案。 这种模式只能用于当你绝对肯定,重复键错误和未找到密钥错误可以安全地忽略 。这意味着使用多主复制失败的情况下,或采用循环复制,不推荐使用在其他情况下。 这个变量设置立即生效,所有复制的渠道,包括运行通道。 财产 价值 命令行格式 --slave-load-tmpdir=dir_name系统变量 slave_load_tmpdir范围 全球 动态 否 看到的是_ 提示应用 否 类型 目录名称 默认值 /tmp复制在奴隶创建临时文件的目录的名称 LOAD DATA INFILE声明.这个变量设置立即生效,所有复制的渠道,包括运行通道。 财产 价值 系统变量 slave_max_allowed_packet范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1073741824最小值 1024最大值 1073741824这个选项设置最大包大小以字节为单位,从SQL和I/O线程可以处理。这个变量设置立即生效,所有复制的渠道,包括运行通道。它是可能的复制写入二进制日志事件的时间比其 max_allowed_packet设置一旦添加事件标头。设置 slave_max_allowed_packet必须大于 max_allowed_packet设置在主,因此采用基于行的复制大更新而不导致复制失败。 这个全局变量总是有价值的,是一个正整数倍数为1024;如果你把它的一些价值,不是价值向下舍入到下一个最高的1024的倍数是存放或使用;设置 slave_max_allowed_packet0个原因来使用1024。(截断警告是在这种情况下,发行)默认最大值为1073741824(1GB);最小的是1024。 slave_max_allowed_packet也可以设置在启动时,使用 --slave-max-allowed-packet选项 财产 价值 命令行格式 --slave-net-timeout=#系统变量 slave_net_timeout范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 60最小值 1数秒等待更多的数据从主/从之前中止阅读连接。设置这个变量没有直接的影响。该变量的状态适用于所有后续 START SLAVE命令 财产 价值 命令行格式 --slave-parallel-type=type类型 枚举 默认值 DATABASE有效值 DATABASELOGICAL_CLOCK使用多线程时(奴隶 slave_parallel_workers大于0),这个变量指定用于决定哪些交易可以并行执行的奴隶政策。变量对奴隶的多线程是不影响功能。可能的值: LOGICAL_CLOCK:这是相同的二进制日志组部分在主提交并行应用在奴隶交易。事务之间的依赖关系是基于时间戳提供额外的并行可能跟踪。当这个值设置,这 binlog_transaction_dependency_tracking系统变量可用于主指定写是用来代替时间戳的并行化,如果写集可供交易,给出了改进的结果相比,时间戳。 DATABASE更新:交易不同数据库的并行应用。如果数据被分割成多个数据库被更新的同时就掌握了这是唯一适当的价值。必须没有跨数据库的约束,这种约束可能受到侵犯的奴隶。
什么时候 slave_preserve_commit_order=1是,你只能使用 logical_clock 如果你使用多层次的复制拓扑的奴隶, LOGICAL_CLOCK可实现各层次的奴隶离主并行不。你可以利用这一效应降低 binlog_transaction_dependency_tracking在指定写集代替并行化在可能的时间戳的主人。 财产 价值 命令行格式 --slave-parallel-workers=#系统变量 slave_parallel_workers范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 1024使奴隶和多线程并行执行的复制事务集奴隶施放的线程数。当该值是一个大于0的数,奴隶是一个多线程的奴隶与指定数量的应用线程,再加上一个协调线程管理。如果你正在使用多个复制的通道,每个通道都有这个线程数。 重试交易支持多线程是一个奴隶启用时。什么时候 slave_preserve_commit_order=1在奴隶交易,外化在同一命令奴隶一样出现在奴隶的中继日志。在交易分配线程的方式配置的应用 --slave-parallel-type禁用并行执行,将此选项设置为0,这给奴隶一个应用线程没有协调线程。使用此设置的 --slave-parallel-type和 slave_preserve_commit_order选项没有效果而被忽略。 设置 slave_parallel_workers没有直接的影响。该变量的状态适用于所有后续 START SLAVE声明. 财产 价值 命令行格式 --slave-pending-jobs-size-max=#系统变量 slave_pending_jobs_size_max范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 (>= 8.0.12)128M默认值 (<= 8.0.11)16M最小值 1024最大值 16EiB块的大小 1024多线程的奴隶,这个变量设置的最大内存量(以字节为单位)提供给奴隶工人队列举行活动尚未应用。设置这个变量对奴隶的多线程是不影响功能。设置这个变量没有直接的影响。该变量的状态适用于所有后续 START SLAVE命令 此变量的最小可能值是1024字节;默认为128MB。可能的最大值是18446744073709551615(16 exbibytes)。这不是1024字节的整数倍值向下舍入到下一个1024字节存储之前。 这个变量的值是一个软限位,可以设置匹配的正常工作。如果一个非常大的事件超过这一规模,交易直到所有奴隶工人有空队列,然后处理。所有后续的交易才举行大型的交易已经完成。 财产 价值 命令行格式 --slave-preserve-commit-order=value系统变量 slave_preserve_commit_order范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 0有效值 01多线程的奴隶,设置1此变量确保交易是体现在同一命令奴隶一样出现在奴隶的中继日志,并在已经从中继日志执行的交易顺序防止间隙。这个变量对奴隶的多线程是不影响功能。 slave_preserve_commit_order=1要求 --log-bin和 --log-slave-updates在奴隶的启用,和 ——从平行式 将logical_clock。 与 slave_preserve_commit_order启用,执行线程等待直到所有以前的交易承诺之前。而从属线程等待其他工人把他们的交易报告其状态为 等待前要提交事务 。在这种模式下,一个多线程的奴隶从来没有进入状态,主人不在。这支持了阅读规模复制使用。看到 第17.3.5,使用复制的规模” 改变这个变量之前,所有复制线程(所有复制的渠道,如果你正在使用多个复制通道)必须停止。如果 slave_preserve_commit_order=0是集交易,从适用于并行可能会失灵。因此,检查最近执行的交易并不能保证从主以前所有的交易已经从执行。在已经从奴隶的中继日志执行事务的序列机会差距。这对日志和恢复的影响时,使用多线程的奴隶。注意,设置 slave_preserve_commit_order=1防止间隙,但是间隙不预防无低水印位置(在 exec_master_log_pos 由交易已执行后面的位置)。看到 第17.4.1.34,“复制和事务不一致” 更多信息 财产 价值 系统变量 slave_rows_search_algorithms=list范围 全球 动态 是 看到的是_ 提示应用 否 类型 配置 默认值 (>= 8.0.2)INDEX_SCAN,HASH_SCAN默认值 (<= 8.0.1)TABLE_SCAN,INDEX_SCAN有效值 TABLE_SCAN,INDEX_SCANINDEX_SCAN,HASH_SCANTABLE_SCAN,HASH_SCANTABLE_SCAN,INDEX_SCAN,HASH_SCAN(等值的索引扫描,Hash San Scan) 当制备批次行基于行的记录和复制,这个变量控制如何行搜索匹配,是否使用散列使用主键或唯一键搜索,其他键,或使用任何键都。这个变量设置立即生效,所有复制的渠道,包括运行通道。对系统变量的初始设置,可以指定使用的 --slave-rows-search-algorithms选项 指定一个以逗号分隔的列表中有2(或3)从列表中的值 INDEX_SCAN, table_scan , HASH_SCAN。预计值为字符串,那么该值必须引用。此外,该值必须不包含任何空格。可能的组合(列表)和它们的影响如下表所示: 使用索引值/选项 INDEX_SCAN,HASH_SCAN或 index_scan,table_scan,hash_scan INDEX_SCAN,TABLE_SCANTABLE_SCAN,HASH_SCANprimary key或独特的关键 索引扫描 索引扫描 哈希索引扫描 (其他)的密钥 哈希索引扫描 索引扫描 哈希索引扫描 没有索引 哈希扫描 表扫描 哈希扫描 该算法是在列表中指定的顺序并不使它们显示的顺序有什么不同 SELECT或 SHOW VARIABLES声明(如用于表只是证明以前相同)。 默认值是 INDEX_SCAN,HASH_SCAN。在这种设置下,哈希是用于任何搜索不使用主键或唯一键。指定 index_scan,table_scan,hash_scan 具有相同的效果作为指定 INDEX_SCAN,HASH_SCAN给力的散列 全部 搜索,设置这个选项 TABLE_SCAN,HASH_SCAN删除散列,设置这个选项 TABLE_SCAN,INDEX_SCAN。这样设置后,所有的搜索,可以使用索引要使用它们,没有任何指标使用表搜索扫描。
有可能这个选项指定单个值,但这并不是最优的,因为设置一个值,算法只使用限制搜索。特别是,设置 INDEX_SCAN一个人是不推荐的,因为,如果没有指数是目前的情况下,搜索是根本无法找到的行。 笔记 只有一个性能上的优势 INDEX_SCAN和 hash_scan 如果行事件足够大。行事件的大小配置使用 --binlog-row-event-max-size。例如,假设一个 DELETE声明中删除25000行生成大 delete_row_event 事件在这种情况下,如果 slave_rows_search_algorithms是集 index_scan 或 HASH_SCAN有一个性能的改善。然而,如果有25000 DELETE报表,每一个都是在独立的事件,然后设置为代表 slave_rows_search_algorithms到 index_scan 或 HASH_SCAN没有提供性能改进在执行这些单独的事件。 财产 价值 命令行格式 --slave-skip-errors=name系统变量 slave_skip_errors范围 全球 动态 否 看到的是_ 提示应用 否 类型 字符串 默认值 OFF有效值 OFF[list of error codes]allddl_exist_errors通常情况下,复制停止在奴隶中发生错误时,它会给你机会去解决不一致性的数据手动。这个变量会导致从SQL线程继续复制语句时返回的任何变量的值列出的错误。 财产 价值 系统变量 slave_sql_verify_checksum范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 1有效值 01因为从SQL线程使用校验和验证数据从中继日志读取。在不匹配的事件,从停止错误。这个变量设置立即生效,所有复制的渠道,包括运行通道。 笔记 从I/O线程读取校验和,如果可能的话,总是在接受来自网络上的事件。 财产 价值 命令行格式 --slave-transaction-retries=#系统变量 slave_transaction_retries范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 10最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295设置复制从SQL线程在单线程或多线程从自动重试失败的交易停止前的最大时间数。这个变量设置立即生效,所有复制的渠道,包括运行通道。默认值是10。将该变量设置为0,禁用自动重试交易。 如果一个SLAVE端未执行的交易因为一个 InnoDB死锁或因为事务的执行时间超过 InnoDB的 innodb_lock_wait_timeout,它会自动重试 slave_transaction_retries在停止一个错误的时候。与非暂时的错误交易不重试。性能模式表 replication_applier_status显示重试发生在每个复制通道的数量,在 count_transactions_retries 专栏 财产 价值 命令行格式 --slave-type-conversions=set系统变量 slave_type_conversions范围 全球 动态 否 看到的是_ 提示应用 否 类型 配置 默认值 有效值 ALL_LOSSYALL_NON_LOSSYALL_SIGNEDALL_UNSIGNED控件的类型转换方式对使用基于行的复制当奴隶。它的值是一个逗号分隔的列表中的零个或多个元素: ALL_LOSSY, 所有非lossy _ _ , ALL_SIGNED, all_unsigned 。这个变量设置为不允许类型转换的主人与奴隶之间的空字符串。这个变量设置立即生效,所有复制的渠道,包括运行通道。 有关类型转换的模式适用于基于行的复制的升级和降级属性的更多信息,参见 基于行的复制:属性升级和降级 财产 价值 系统变量 sql_slave_skip_counter范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 从掌握的从属服务器应该跳过事件的数目。设置选项没有直接的影响。变量适用于下一个 START SLAVE下一个语句; START SLAVE声明同时变化值回零。当这个变量设置为非零值,有多个复制通道的配置, START SLAVE声明只能用 通道 channel条款. 此选项是基于gtid复制不兼容,不能设置为非零值时, --gtid-mode=ON。如果你需要跳过交易时采用的gtids,使用 gtid_executed从主而。看到 注射空交易 ,有关如何做这个 重要 如果不设置此变量指定事件的数量会导致奴隶在事件组中开始,奴隶继续跳直到它找到下一个事件组开始,从这一点开始。有关更多信息,参见 第13.4.2.5,“全球sql_slave_skip_counter语法” 财产 价值 命令行格式 --sync-master-info=#系统变量 sync_master_info范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 10000最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295这个变量复制奴隶的影响取决于奴隶的 master_info_repository是集 文件 或 TABLE,在下面解释 master_info_repository = FILE.
如果价值 sync_master_info大于0,主从同步 master.info 文件到磁盘(使用 fdatasync())在每 信息技术硕士 事件如果是0,MySQL服务器不同步的 master.info文件服务器磁盘;相反,依赖于操作系统将其内容定期与任何其他文件。 master_info_repository = TABLE.
如果价值 sync_master_info大于0,奴隶主信息库表更新后每 信息技术硕士 事件如果它是零,表不更新。 默认值为 sync_master_info10000。这个变量设置立即生效,所有复制的渠道,包括运行通道。 财产 价值 命令行格式 --sync-relay-log=#系统变量 sync_relay_log范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 10000最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295如果这个变量的值大于零,MySQL服务器同步中继日志到磁盘(使用 fdatasync())在每 sync_relay_log 事件日志写入继电器。这个变量设置立即生效,所有复制的渠道,包括运行通道。 设置 sync_relay_log0不同步做盘;在这种情况下,服务器依赖于操作系统冲洗中继日志的内容以时间为任何其他文件。 价值是最安全的选择,因为在发生崩溃,你失去最多一个事件从中继日志。然而,它也是最慢的选择(除非盘面有电池支持的高速缓存,使同步速度非常快)。 财产 价值 命令行格式 --sync-relay-log-info=#系统变量 sync_relay_log_info范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 10000最小值 0最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295默认值为 sync_relay_log_info10000。这个变量设置立即生效,所有复制的渠道,包括运行通道。 这个变量对复制的奴隶的影响取决于服务器的 relay_log_info_repository设置( 文件 或 TABLE)。if the setting is 表 ,该变量的影响还取决于由中继日志信息表用于存储引擎是事务性的(如 InnoDB)或不交易( MyISAM)。这些因素的影响服务器的性能 sync_relay_log_info 值为零,大于零,如下: sync_relay_log_info = 0如果 relay_log_info_repository是集 文件 ,MySQL服务器不同步的 relay-log.info文件服务器磁盘;相反,依赖于操作系统将其内容定期与任何其他文件。 如果 relay_log_info_repository是集 表 ,和该表的存储引擎是事务性的,桌子是每次交易后更新。(The sync_relay_log_info设置在这种情况下有效地忽略。) 如果 relay_log_info_repository是集 表 ,和该表的存储引擎不是事务性的,桌子是从不更新。
sync_relay_log_info =N> 0如果 relay_log_info_repository是集 文件 ,从同步 relay-log.info文件到磁盘(使用 fdatasync() )在每 N交易 如果 relay_log_info_repository是集 表 ,和该表的存储引擎是事务性的,桌子是每次交易后更新。(The sync_relay_log_info设置在这种情况下有效地忽略。) 如果 relay_log_info_repository是集 表 ,和该表的存储引擎不是事务性的,更新的表后每 N事件
财产 价值 命令行格式 --binlog-row-event-max-size=#类型 整数 默认值 8192最小值 256最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295指定基于二进制日志事件一行的最大大小,以字节为单位。行分为事件小于这个尺寸如果可能的话。该值应该是256的倍数。默认值是8192。看到 17.2.1,“复制格式” --binlog-rows-query-log-events财产 价值 命令行格式 --binlog-rows-query-log-events类型 布尔 默认值 FALSE此选项使 binlog_rows_query_log_events,使MySQL服务器写信息日志事件如行查询日志事件为其二进制日志。 指定用于二进制日志文件的基名称。二进制日志功能,服务器记录所有语句更改数据的二进制日志,这是用于备份和复制。二进制日志是一个序列文件的基本名称和数字扩展。这个 --log-bin期权价值的日志序列的基本名称。服务器上添加一个数字后缀的基本名称创建序列的二进制日志文件。 如果你不提供 --log-bin选项,MySQL的使用 二进制日志 作为默认的二进制日志文件的基名称。与早期版本兼容,如果你的供应 --log-bin没有字符串或空字符串的选择,基名称默认为 host_name宾 ,使用的主机名 二进制日志文件的默认位置是数据目录。你可以使用 --log-bin选项指定一个替代的位置,通过对基地的名字加入领先的绝对路径名来指定一个不同的目录。当服务器读取二进制日志索引文件的录入,跟踪二进制日志文件已被使用,它检查条目是否包含相对路径。如果是这样,该路径的相对与绝对路径替换设置使用 ——日志本 选项一个绝对路径记录在二进制日志索引文件保持不变;在这种情况下,索引文件必须手动编辑,使一个新的路径或路径被使用。二进制日志文件的基名称和任何指定的路径是可用的 log_bin_basename系统变量 二进制日志是默认启用(的 log_bin系统变量设置为ON)。唯一的例外是如果你使用 mysqld 初始化数据目录手动调用它的 --initialize或 -初始化不安全 选项,在默认情况下禁用二进制日志。它有可能使二进制日志在这种情况下,通过指定 --log-bin选项 禁用二进制日志,你可以指定 --skip-log-bin或 --disable-log-bin在启动选项。如果这些选项指定 ——日志本 还规定,指定的选项后优先。 这个 --log-slave-updates和 --slave-preserve-commit-order选择需要的二进制日志。如果您禁用二进制日志,要么忽略这些选项,或指定 --skip-log-slave-updates和 --skip-slave-preserve-commit-order。MySQL默认禁用这些选项时 --skip-log-bin或 --disable-log-bin指定。如果你指定 --log-slave-updates或 --slave-preserve-commit-order在一起 --skip-log-bin或 --disable-log-bin、警告或发出错误信息。 在MySQL 5.7,服务器ID必须指定当二进制日志被启用,或服务器启动不了。在MySQL 8的 server_id系统变量默认设置为1。服务器现在可以开始使用这个默认的服务器ID二进制日志时启用,但信息性消息发出后如果不指定服务器ID显式使用 --server-id选项所使用的复制拓扑中的服务器,你必须指定一个唯一的非零服务器ID为每个服务器。 在二进制日志格式和管理信息,看 5.4.4节,“二进制日志” 财产 价值 命令行格式 --log-bin-index=file_name类型 文件名 对于二进制日志索引文件的名称。二进制日志索引文件包含所有使用的二进制日志文件的名字。默认情况下,它具有相同的位置和基本名称为您指定的二进制日志文件的使用 --log-bin选择,扩大 指数 。如果你没有提供 --log-bin选项,用于二进制日志索引文件的默认名称为 binlog.index 。如果你提供的 --log-bin没有字符串或空字符串的选择,对于二进制日志索引文件的默认名称为 host_name-二.索引 ,使用的主机名 在二进制日志格式和管理信息,看 5.4.4节,“二进制日志” --log-bin-trust-function-creators[={0|1}]财产 价值 命令行格式 --log-bin-trust-function-creators系统变量 log_bin_trust_function_creators范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 FALSE此选项设置相应的 log_bin_trust_function_creators系统变量。如果没有给出参数,选项设置变量1。 log_bin_trust_function_creators影响MySQL如何执行限制存储函数和触发器的创建。看到 23.7节,“二进制日志存储程序” --log-bin-use-v1-row-events[={0|1}]财产 价值 命令行格式 --log-bin-use-v1-row-events[={0|1}]系统变量 log_bin_use_v1_row_events范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 0MySQL 8使用2版本的二进制日志行事件,它不能用MySQL服务器读稿到MySQL 5.6.6之前。将此选项设置为1的原因 mysqld 写使用1版本的二进制日志记录事件,这是二进制日志事件中释放的唯一版本,并由此产生的二进制日志,可以读取在释放这些奴隶。设置 --log-bin-use-v1-row-events0(默认)的原因 mysqld 使用2版本的二进制日志事件。 使用这个选项的值可以从只读了 log_bin_use_v1_row_events系统变量
财产 价值 命令行格式 --binlog-do-db=name类型 字符串 这个选项影响的方式类似于这样的二进制日志 --replicate-do-db影响复制 这个选项的效果取决于基于语句或基于行的记录格式使用,效果一样 --replicate-do-db取决于基础或基于行的复制是使用语句。你应该记住,格式用来记录某一言论未必相同,所表示的值 binlog_format。例如,DDL语句,如 CREATE TABLE和 ALTER TABLE经常登录的陈述,不考虑日志格式的效果,所以下面的语句基础规则 - Binlog - do-DB 总是将决定是否记录表。 基于语句的日志 只有那些语句写入二进制日志在默认的数据库(即,一个选择 USE)是 db_name。要指定多个数据库,多次使用此选项,一次为每个数据库;然而,这样做 不 因为跨数据库的报表等 UPDATEsome_db.some_tableSET foo='bar'被记录在一个不同的数据库(或数据库)的选择。 警告 指定多个数据库的你 必须 使用此选项的多个实例。因为数据库名称不能包含逗号,名单将被视为一个单一的数据库的名称如果你提供一个以逗号分隔的列表。 什么不工作,你可能希望使用基于语句的记录的一个例子:如果服务器开始 --binlog-do-db=sales你发出以下声明,该 UPDATE语句 不 记录: USE prices; UPDATE sales.january SET amount=amount+1000;
这其中的主要原因 “ 只是检查默认数据库 “ 行为是它知道它应该被复制的是仅从陈述困难(例如,如果你正在使用多个表 DELETE表或多个表 UPDATE陈述行为跨越多个数据库)。它也越来越快,而不是所有的数据库都没有需要检查只有默认的数据库。 另一种情况可能不是不言而喻的发生在一个给定的数据库复制,尽管它没有指定设置选项时。如果服务器开始 --binlog-do-db=sales,以下 UPDATE尽管声明记录 价格 不包括在设置 --binlog-do-db: USE sales;UPDATE prices.discounts SET percentage = percentage + 10;
因为 sales是默认的数据库时, UPDATE声明发出后,该 UPDATE登录 基于行的日志 测井是限制数据库 db_name。表属于唯一的变化 db_name登录的默认数据库;有无影响。假设服务器开始 --binlog-do-db=sales与基于行的记录是有效的,然后下面的语句被执行: USE prices;UPDATE sales.february SET amount=amount+100;
的变化 february表中 特价 数据库记录按照 UPDATE声明;这是否 USE声明发表。然而,当使用基于日志格式的行 --binlog-do-db=sales,继受取得的变化 UPDATE没有登录: USE prices;UPDATE prices.march SET amount=amount-25;
即使 USE prices语句改变了 使用销售 ,的 UPDATE语句的效果还没有被写入二进制日志。 另一个重要的区别在 --binlog-do-db处理报表的记录相对于基于行的记录发生在语句引用多个数据库。假设服务器开始 --binlog-do-db=db1,和下面的语句被执行: USE db1;UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
如果您使用的是基于语句的记录,既表更新写入二进制日志。然而,基于格式的行时,只有改变 table1登录; 表2 是在一个不同的数据库,所以它是不会改变的 UPDATE。现在假设,相反的 使用db1 声明一个 USE db4声明已被使用: USE db4;UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
在这种情况下,的 UPDATE声明中没有写入二进制日志,当使用基于语句的日志。然而,使用基于行的记录时,改变 表1 登录,但不知道 table2换句话说,在指定的数据库表的变化 --binlog-do-db登录的默认数据库的选择,以及对这种行为没有影响。 财产 价值 命令行格式 --binlog-ignore-db=name类型 字符串 这个选项影响的方式类似于这样的二进制日志 --replicate-ignore-db影响复制 这个选项的效果取决于基于语句或基于行的记录格式使用,效果一样 --replicate-ignore-db取决于基础或基于行的复制是使用语句。你应该记住,格式用来记录某一言论未必相同,所表示的值 binlog_format。例如,DDL语句,如 CREATE TABLE和 ALTER TABLE经常登录的陈述,不考虑日志格式的效果,所以下面的语句基础规则 ——binlog-ignore-db 总是将决定是否记录表。 基于语句的日志 告诉服务器不记录任何语句,默认的数据库(即,一个选择 USE)是 db_name如果没有默认的数据库,没有 --binlog-ignore-db期权的应用,这样的陈述是经常登录。(错误# 11829838,错误# 60188) 基于行的格式 告诉服务器不要日志更新数据库中的任何表 db_name。目前的数据库没有影响。 采用基于语句的记录时,下面的例子不工作,你可能期望。假设服务器开始 --binlog-ignore-db=sales你发出以下声明: USE prices;UPDATE sales.january SET amount=amount+1000;
这个 UPDATE陈述 是 在这种情况下,由于登录 --binlog-ignore-db仅适用于默认数据库(由 USE声明)。因为 特价 数据库在声明中明确规定,声明未被过滤。然而,使用基于行的日志时, UPDATE语句的作用 不 写入二进制日志,这意味着没有变化的 sales.january表格记录;在这种情况, --binlog-ignore-db=sales起因 全部 使在师父的复制表的变化 sales数据库是对二进制日志的目的忽视。 指定要忽略多个数据库,多次使用此选项,一次为每个数据库。因为数据库名称不能包含逗号,名单将被视为一个单一的数据库的名称如果你提供一个以逗号分隔的列表。 你不应该如果你使用跨数据库的更新,你不希望这些更新会记录使用此选项。
--binlog-checksum={NONE|CRC32}财产 价值 命令行格式 --binlog-checksum=type类型 字符串 默认值 CRC32有效值 NONECRC32启用此选项使主人写写入二进制日志事件校验。设置 NONE禁用,或名称的算法用于生成校验;目前,只有crc32校验的支持,和CRC32是默认的。你不能在一个事务中更改此选项的设置。 --master-verify-checksum={0|1}财产 价值 命令行格式 --master-verify-checksum=name类型 布尔 默认值 OFF启用此选项主验证事件使用校验和的二进制日志,并停止在不匹配的事件错误。默认情况下禁用。
--slave-sql-verify-checksum
财产 价值 命令行格式 --max-binlog-dump-events=#类型 整数 默认值 0这个选项是通过复制测试MySQL测试和调试内部使用。 财产 价值 命令行格式 --sporadic-binlog-dump-fail类型 布尔 默认值 FALSE这个选项是通过复制测试MySQL测试和调试内部使用。
SET
财产 价值 命令行格式 --binlog-cache-size=#系统变量 binlog_cache_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 32768最小值 4096最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295缓存的大小来把握变化的二进制日志中的事务。当二进制日志服务器上启用(与 log_bin系统变量设置为on),二进制日志缓存分配给每个客户如果服务器支持任何事务性存储引擎。如果你经常使用大量的交易,你可以增加缓存大小以获得更好的性能。这个 Binlog_cache_use和 Binlog_cache_disk_use在这一变数中,情况可变。See 5.4.4节,“二进制日志” binlog_cache_size集只为交易的缓存大小;语句缓存的大小是由 binlog_stmt_cache_size系统变量 财产 价值 系统变量 binlog_checksum范围 全球 动态 是 看到的是_ 提示应用 否 类型 字符串 默认值 CRC32有效值 NONECRC32当启用时,此变量的原因主在二进制日志写的每一个事件的校验。 binlog_checksum支持的值 无 (禁用)和 CRC32。默认值是 CRC32 。你不能改变的价值 binlog_checksum在一个事务 什么时候 binlog_checksum被剥夺(价值) 无 ),服务器验证,这是写作的唯一完整的事件写检查事件长度的二进制日志(而不是一个校验和)为每个事件。 改变这个变量的值使二进制日志可以旋转;校验总是写给一个二进制日志文件,而不只是一部分人。 在主一个值由从未知的原因从设定自己设置这个变量 binlog_checksum价值 无 ,和一个错误停止复制。(错误# 13553750,错误# 61096)如果老奴隶的向后兼容性是一个问题,你可能需要明确设定值 NONEbinlog_direct_non_transactional_updates财产 价值 命令行格式 --binlog-direct-non-transactional-updates[=value]系统变量 binlog_direct_non_transactional_updates范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF由于并发问题,奴隶可以不一致时,一个事务中包含更新的事务性和非事务表。MySQL试图通过写作非事务性事务的语句缓存保存在这些陈述的因果关系,这是在犯冲。然而,出现问题时进行修改,非事务表代表的交易成为其他连接立即可见,因为这些变化可能不会立即写入到二进制日志。 这个 binlog_direct_non_transactional_updates变量提供了一个可能的解决这个问题。默认情况下,这个变量被禁用。有可能 binlog_direct_non_transactional_updates导致更新非事务性表被直接写入二进制日志,而不是交易缓存。 binlog_direct_non_transactional_updates只为陈述,重复使用基于二进制日志格式的语句 ;那是,它只能在价值 binlog_format是 声明 ,或当 binlog_format是 混合的 与一个给定的声明被复制使用的格式声明。这个变量没有影响二进制日志格式时 ROW,或当 binlog_format是集 混合的 与一个给定的陈述是基于行的复制格式。 重要 在启用这个变量,你必须确保有事务和非事务表之间没有依赖关系;这种依赖的一个例子是声明 INSERT INTO myisam_table SELECT * FROM innodb_table。否则,这样的说法可能导致奴隶偏离主。 这个变量没有影响二进制日志格式时 ROW或 混合的 财产 价值 命令行格式 --binlog-error-action[=value]系统变量 binlog_error_action范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 ABORT_SERVER有效值 IGNORE_ERRORABORT_SERVER控制当服务器遇到错误,例如:无法写入,冲洗或同步二进制日志,可以使主人的日志变得不一致和复制失去同步的奴隶。 这个变量的默认值 ABORT_SERVER,使服务器停止采伐和关闭它遇到一个这样的错误时,二进制日志。在服务器重启,所有先前的准备和二进制记录交易的承诺,而任何交易都准备好但不是二进制日志由于错误被中止。 什么时候 binlog_error_action是集 主_误差 ,如果服务器遇到这样的错误继续正在进行的事务,记录错误并停止采伐,并继续执行更新。恢复的二进制日志 log_bin必须再次启用。这提供了向后兼容旧版本的MySQL。 财产 价值 命令行格式 --binlog-expire-logs-seconds=#介绍 8.0.1 系统变量 binlog_expire_logs_seconds范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 (>= 8.0.11)2592000默认值 (<= 8.0.4)0最小值 0最大值 4294967295集的二进制日志保质期秒。有效期结束后,二进制日志文件可以被自动删除。可能清除发生在启动时的二进制日志刷新。日志冲洗时如 最后,“MySQL服务器日志” 默认的二进制日志的保质期是2592000秒,这相当于30天(30×24×60*60秒)。如果没有默认的应用 binlog_expire_logs_seconds也不过时的系统变量 expire_logs_days已经在启动一个值。如果一个变量不为零的值 binlog_expire_logs_seconds或 expire_logs_days设置在启动时,此值作为二进制日志的截止日期。如果对这些变量的一个非零的值设置为在启动时,该值为 binlog_expire_logs_seconds作为二进制日志的保质期,和值 expire_logs_days被忽略的警告消息 禁用自动的二进制日志清除,指定值0明确 binlog_expire_logs_seconds,而不指定值 expire_logs_days。与早期版本的兼容性,自动清除也是残疾人如果你指定一个值0明确 expire_logs_days不指定一个值 binlog_expire_logs_seconds。在这种情况下,默认为 binlog_expire_logs_seconds不适用 删除二进制日志文件手动,使用 PURGE BINARY LOGS声明。看到 第13.4.1.1,“清除二进制日志语法” 财产 价值 命令行格式 --binlog-format=format系统变量 binlog_format范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 ROW有效值 ROWSTATEMENTMIXED这组变量的二进制日志格式,可以是任何一个 STATEMENT, 行 ,或 MIXED。看到 17.2.1,“复制格式” binlog_format是由 --binlog-format选择在启动时,或由 binlog_format变量在运行时 笔记 虽然你可以在运行时更改日志格式,它是 不 建议你改变它而复制正在进行。这部分是由于这样的事实,不尊重主人的奴隶 binlog_format设置;一个给定的MySQL服务器只能改变自己的日志格式。 默认值是 ROW你必须有 SYSTEM_VARIABLES_ADMIN或 SUPER权限设置全局或会话 binlog_format价值 规则的更改时,这个变量的作用和影响会持续多久是作为其他MySQL服务器系统变量相同。有关更多信息,参见 第13.7.5.1,”句法变量赋值” 什么时候 MIXED指定基于复制技术的声明,除的情况下,只有基于行的复制是保证导致正确的结果。例如,当报表包含用户定义函数(UDF)或 UUID()功能 对于存储程序的细节(存储过程和函数、触发器和事件)处理时,每个二进制日志格式设置,看 23.7节,“二进制日志存储程序” 也有例外的时候,你不能在运行时切换复制格式: 从在存储函数或触发器。 如果会话是目前基于行的复制模式,具有开放的临时表。 在一个事务内
试图转换格式在这种情况下导致错误。 二进制日志格式影响以下服务器选项的行为: 在个人选项的描述中详细讨论这些影响。 binlog_group_commit_sync_delay财产 价值 命令行格式 --binlog-group-commit-sync-delay=#系统变量 binlog_group_commit_sync_delay范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 1000000控制多少微秒的二进制日志提交之前等待的二进制日志文件同步到磁盘。默认情况下 binlog_group_commit_sync_delay设置为0,也就是说没有延迟。设置 binlog_group_commit_sync_delay一微秒的延迟使得更多的交易可同步到磁盘时,降低整体的时间提交一组交易因为较大的群体需要更少的时间单位组。 什么时候 sync_binlog=0或 sync_binlog=1设置指定的延迟 binlog_group_commit_sync_delay适用于每一个二进制日志提交集团之前同步(或在案件 sync_binlog=0在程序之前当 sync_binlog设置的值 N 大于1,延迟应用后每 N 二进制日志提交组 设置 binlog_group_commit_sync_delay可以增加任何服务器上具有并行进行的交易数量(或可能在故障转移后)复制的奴隶,因此可以增加并行执行复制的奴隶。从这个效应中获益,从服务器必须有 slave_parallel_type=LOGICAL_CLOCK集,而效果更为显著, binlog_transaction_dependency_tracking=COMMIT_ORDER也是集。重要的是要考虑到主人的吞吐量和奴隶的吞吐量,当你调整设置 binlog_group_commit_sync_delay设置 binlog_group_commit_sync_delay也可以减少一些 fsync() 调用服务器上的二进制日志(主从)具有一个二进制日志。 注意设置 binlog_group_commit_sync_delay增加交易服务器上的延迟,这可能会影响客户端应用程序。同时,在高度并行的工作负载,它是可能的延迟增加竞争和降低吞吐量。通常情况下,设置一个延迟大于弊的好处,但调整都要进行确定最佳设置。 binlog_group_commit_sync_no_delay_count财产 价值 命令行格式 --binlog-group-commit-sync-no-delay-count=#系统变量 binlog_group_commit_sync_no_delay_count范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 1000000等待终止当前延迟指定的最大交易数 binlog_group_commit_sync_delay。如果 binlog_group_commit_sync_delay设置为0,那么这个选项不起作用。 财产 价值 过时的 是 系统变量 binlog_max_flush_queue_time范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 0最小值 0最大值 100000binlog_max_flush_queue_time是过时的,是在未来的MySQL释放最终去除。以前,这个系统变量控制在微秒的时间继续阅读交易从冲洗队列之前,集团承诺。它不再有任何作用。 财产 价值 系统变量 binlog_order_commits范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 ON当这个变量是在一个主启用(默认),交易体现在相同的命令,他们都写入二进制日志。如果禁用,交易可能会致力于并行。在某些情况下,禁用此变量可能产生的业绩增量。 财产 价值 命令行格式 --binlog-row-image=image_type系统变量 binlog_row_image=image_type范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 full有效值 full(日志的所有列) minimal(只记录更改的列,并需要确定排列) noblob(日志的所有列,除不必要的BLOB和文本字段) MySQL的基于行的复制,这个变量决定如何行图像写入二进制日志。运行时更改此变量的要求 SYSTEM_VARIABLES_ADMIN或 SUPER特权,甚至在会议上的价值。 基于MySQL的行复制,每行更改事件包含两个图像,一个 “ 之前 “ 图像的列匹配搜索时的行被更新,和 “ 之后 “ 包含变化的图像。通常情况下,MySQL日志整行(即所有列)对之前和之后的图像。然而,它没有必要包括在图像每一列,我们往往可以节省磁盘,内存,和记录只有那些列实际上是要求网络使用。 笔记 删除行时,只有在记录的图像,因为没有改变价值观传播的缺失。插入一行时,只有在记录的图像,因为没有现有的行相匹配。只有当更新一排都是之前和之后的图像,并写入二进制日志。 对于之前的形象,它是只需要登录所需的唯一标识列的最小集合。如果包含行的表有一个主键,那么只有主键列或列写入二进制日志。否则,如果表中有一个独特的密钥的所有列 NOT NULL,那么只有列在独特的关键需要登录。(如果表没有主键或唯一键没有任何 无效的 列,然后所有列必须使用以前的图像,并记录图像。)在后,这是必要的日志仅列事实上改变了。 你可以导致服务器日志或最小行使用 binlog_row_image系统变量。这个变量实际上需要一个可能的值,如下面的表所示: 默认值是 full当使用 minimal或 noblob 删除和更新,保证正确的工作对于一个给定的表,当且仅当下列条件的源和目标表是真的: 所有列必须出现在同一顺序;每一列必须使用相同的数据类型为在其他表中的对应。 该表必须有相同的主键定义。
(换句话说,该表必须索引的可能的例外是不表的主键的一部分是相同的。) 如果这些条件不满足,这是可能的,目标表中的主键列的值可能不足以用于删除或更新提供了一个独特的比赛。在这种情况下,没有任何警告或错误发出;主从默默发散,从而打破一致性。 设置这个变量没有影响的二进制日志格式时 STATEMENT。什么时候 binlog_format是 混合的 ,设置 binlog_row_image适用于登录使用基于行的格式的变化,但这种变化记录为报表设置无影响。 设置 binlog_row_image在全球或会话水平不会导致一个隐含的承诺;这意味着,该变量可以改变而不影响交易过程中的交易。 财产 价值 命令行格式 --binlog-row-metadata=metadata_type介绍 8.0.1 系统变量 binlog_row_metadata=metadata_type范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 MINIMAL有效值 FULL(所有的元数据都包括在内。) MINIMAL(限制包括元数据。) 配置表的元数据量添加到二进制日志记录时,使用基于行的。当设置为 MINIMAL,默认情况下,只有元数据相关 签署 旗帜,列的字符集和几何类型记录。当设置为 FULL记录表完整的元数据,如柱的名字, ENUM或 配置 字符串值, PRIMARY KEY信息,等等 扩展的元数据用于以下目的: 奴隶使用元数据来传递数据时,其表结构不同于硕士学位。 外部软件可以使用元数据来解码行事件和数据保存到外部数据库,如数据仓库。
财产 价值 命令行格式 --binlog-row-value-options=#介绍 8.0.3 系统变量 binlog_row_value_options范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 配置 默认值 ''有效值 PARTIAL_JSON当设置为 PARTIAL_JSON,这使得利用空间高效的二进制日志格式更新,只修改一个JSON文档的一小部分,使基于行的复制只写修改部分的JSON文件后在二进制日志更新图像(而不是写完整的文件)。本工程为一个 UPDATE语句修改JSON列使用任何序列 JSON_SET(), JSON_REPLACE(),和 JSON_REMOVE()。如果修改需要比完整的文件更多的空间,或者服务器无法生成一个局部更新,完整的文件代替。 你必须有 SYSTEM_VARIABLES_ADMIN或 SUPER权限设置全局或会话的值。 片名:杰森 是唯一支持的值来设置; binlog_row_value_options,设置它的值为空字符串。 binlog_row_value_options=PARTIAL_JSON只有生效时启用和二进制日志 binlog_format是集 行 或 MIXED。基于语句的复制 总是 只记录修改部分的JSON文档,无论设置为任何值 binlog_row_value_options。最大限度的节省了空间,使用 binlog_row_image=NOBLOB或 binlog_row_image=MINIMAL加上这个选项 binlog_row_image=FULL节省比这更少的空间,因为完整的JSON文档存储在以前的图像,和局部更新只存储在图像。 binlog_row_value_options=PARTIAL_JSON覆盖的任何设置 log_bin_use_v1_row_events变量。如果该选项被启用,需要由事件格式 binlog_row_value_options=PARTIAL_JSON仍在使用 mysqlbinlog 输出包括部分json更新的形式事件编码为Base-64字符串 BINLOG声明。if the --verbose指定选项, mysqlbinlog 显示部分JSON更新JSON使用伪SQL语句的可读性。 如果修改不适用于对奴隶的JSON文档MySQL复制产生一个错误。这包括未能找到路径。要知道,即使这个和其他的安全检查,如果在从JSON文件有偏离,在主和部分更新应用,它仍然是理论上可能产生一个有效的但意想不到的JSON文档的奴隶。 复制到老版本 当复制一个奴隶使用MySQL 8.0.2或从主运行MySQL 8.0.3或晚以前的版本, binlog_row_value_options必须禁用(即设置 ' ' )。这是因为JSON部分更新记录使用二进制日志事件类型介绍MySQL 8.0.3;该事件类型不是由MySQL以前版本的认可。 财产 价值 命令行格式 --binlog-rows-query-log-events系统变量 binlog_rows_query_log_events范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 FALSE这个 binlog_rows_query_log_events系统变量影响的基于行的记录只有。当启用时,它会导致MySQL服务器写信息日志事件如行查询日志事件为其二进制日志。此信息可用于调试和相关用途;如获得原始查询发布的主人就不能从行更新改造。运行时更改此变量的要求 SYSTEM_VARIABLES_ADMIN或 SUPER特权,甚至在会议上的价值。 这些事件通常是由MySQL程序读取二进制日志,所以没有问题时,复制或从备份还原忽略。看他们,用mysqlbinlog详细级别的增加 --verbose选择两次,无论是为 - VV 或 --verbose --verbose财产 价值 命令行格式 --binlog-stmt-cache-size=#系统变量 binlog_stmt_cache_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 32768最小值 4096最大值 (64位平台) 18446744073709551615最大值 (32位平台) 4294967295这个变量决定举行非事务语句在事务期间发布的二进制日志缓存的大小。当二进制日志服务器上启用(与 log_bin系统变量设置为on),单独的二进制日志事务和语句缓存分配给每个客户端,如果服务器支持任何事务性存储引擎。如果你经常使用大型非事务语句在交易过程中,你可以增加缓存大小以获得更好的性能。这个 Binlog_stmt_cache_use和 Binlog_stmt_cache_disk_use在这一变数中,情况可变。See 5.4.4节,“二进制日志” 这个 binlog_cache_size系统变量设置的缓存大小的交易。 binlog_transaction_dependency_tracking财产 价值 命令行格式 --binlog-transaction-dependency-tracking=value介绍 8.0.1 系统变量 binlog_transaction_dependency_tracking范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 COMMIT_ORDER有效值 COMMIT_ORDERWRITESETWRITESET_SESSION源依赖信息,主用于确定哪些交易可以并行执行的奴隶的多线程应用。这个变量可以取三个值,在下面的列表描述: COMMIT_ORDER:依赖信息产生于主人的提交时间戳。这是默认的。这种模式也可用于任何交易没有写集,即使这是可变的 writeset 或 WRITESET_SESSION;这也是为交易更新没有主键的表和事务更新有外键约束的表。 WRITESET:依赖信息是从主人的写集生成的,和任何交易写不同的元组可以并行。 WRITESET_SESSION:依赖信息是从主人的写集产生的,但没有两更新相同的会话可以被重新排序。
WRITESET和 writeset_session 模式不提供,比那些已经返回更新的任何交易的依赖 COMMIT_ORDER模式 这个变量的值不能设置任何其他比 COMMIT_ORDER如果 transaction_write_set_extraction是 关闭 。你也应该注意,价值 transaction_write_set_extraction如果不能改变目前的价值 binlog_transaction_dependency_tracking 是 WRITESET或 writeset_session 排数值保持和检查已经改变给定行是由价值决定的最新交易 binlog_transaction_dependency_history_sizebinlog_transaction_dependency_history_size财产 价值 命令行格式 --binlog-transaction-dependency-history-size=#介绍 8.0.1 系统变量 binlog_transaction_dependency_history_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 25000最小值 1最大值 1000000集排数的哈希值,保存在内存中,用于寻找交易,最后修改给定行的上限。一旦这样的哈希值已经达到,历史被清除。 财产 价值 命令行格式 --expire-logs-days=#过时的 8.0.3 系统变量 expire_logs_days范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 (>= 8.0.11)0默认值 (>= 8.0.2, <= 8.0.4)30默认值 (<= 8.0.1)0最小值 0最大值 99指定的二进制日志文件自动清除之前的天数。 expire_logs_days是过时的,并将在未来的版本中删除。相反,使用 binlog_expire_logs_seconds,在秒集的二进制日志保质期。如果你不设置为系统变量的值,默认的有效期是30天。可能清除发生在启动时的二进制日志刷新。日志冲洗时如 最后,“MySQL服务器日志” 任何非零的值,可以指定 expire_logs_days如果是忽略 binlog_expire_logs_seconds还规定,与价值 binlog_expire_logs_seconds而不是作为二进制日志的截止日期。一个警告信息,就是在这种情况下发行。一个非零的值 expire_logs_days仅仅作为二进制日志保质期如果 binlog_expire_logs_seconds没有指定或指定为0 禁用自动的二进制日志清除,指定值0明确 binlog_expire_logs_seconds,而不指定值 expire_logs_days。与早期版本的兼容性,自动清除也是残疾人如果你指定一个值0明确 expire_logs_days不指定一个值 binlog_expire_logs_seconds。在这种情况下,默认为 binlog_expire_logs_seconds不适用 删除二进制日志文件手动,使用 PURGE BINARY LOGS声明。看到 第13.4.1.1,“清除二进制日志语法” 是否启用或禁用二进制日志。二进制日志功能,服务器记录所有语句更改数据的二进制日志,这是用于备份和复制。 ON意味着二进制日志可用, 关闭 这意味着在不使用 二进制日志是默认启用的,与 log_bin在线看两个系统变量。《 --log-bin选项用于对二进制日志指定一个基地的名称和位置。 如果 --skip-log-bin或 --disable-log-bin选项指定在启动时,二进制日志被禁用,与 log_bin 系统变量设置为OFF。 在二进制日志格式和管理信息,看 5.4.4节,“二进制日志” 财产 价值 系统变量 log_bin_basename范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 持有的基名称和路径的二进制日志文件,并可以设置与 --log-bin服务器的选择。在MySQL 8.0,if the ——日志本 不提供选项,默认的库名称 binlog。对于MySQL 5.7的兼容性,如果 ——日志本 选择不提供任何字符串或空字符串,默认的库名称 host_name-bin,使用的主机名。默认位置是数据目录。 财产 价值 系统变量 log_bin_index范围 全球 动态 否 看到的是_ 提示应用 否 类型 文件名 持有的基名称和路径的二进制日志索引文件,可设置与 --log-bin-index服务器选项 log_bin_trust_function_creators财产 价值 命令行格式 --log-bin-trust-function-creators系统变量 log_bin_trust_function_creators范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 FALSE这个变量适用于二进制日志功能。它控制存储功能的创建者是否可以信任不创建存储功能,将导致不安全的事件被写入二进制日志。如果设置为0(默认),不允许用户创建或更改存储功能,除非他们有 SUPER除了特权 CREATE ROUTINE或 ALTER ROUTINE特权。0的设置也执行一个函数必须声明的约束 确定性 特征,或与 READS SQL DATA或 没有SQL 特征。如果变量设置为1,MySQL不执行这些限制存储功能创新。这个变量也适用于触发创作。看到 23.7节,“二进制日志存储程序” 财产 价值 命令行格式 --log-bin-use-v1-row-events[={0|1}]系统变量 log_bin_use_v1_row_events范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 0显示是否在使用2版本的二进制日志。值1表明服务器是使用1版本写日志记录事件的二进制日志(二进制日志事件中使用以前版本的版本),从而产生一个二进制日志可以通过读老奴隶。0表明第2版二进制日志事件都在使用。 这个变量是只读的。1版和2版的二进制事件的二进制日志切换,需要重新开始 mysqld 与 --log-bin-use-v1-row-events选项 log_builtin_as_identified_by_password财产 价值 命令行格式 --log-builtin-as-identified-by-password[={OFF|ON}]远离的 8.0.11 系统变量 log_builtin_as_identified_by_password范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF这是8.0.11删除MySQL系统变量。 财产 价值 命令行格式 --log-slave-updates系统变量 log_slave_updates范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 (>= 8.0.3)TRUE默认值 (<= 8.0.2)FALSE无论是从主服务器从服务器接收更新应记录到自己的二进制日志的奴隶。二进制日志一定要为这个变量有什么影响奴隶启用。看到 第17.1.6,“复制和二进制日志记录选项和变量” 本系统变量设置为默认,并且是只读的。如果你需要防止从服务器日志更新,指定 --skip-log-slave-updates当你的奴隶,或指定 log_slave_updates=OFF在从配置文件中 log_statements_unsafe_for_binlog财产 价值 系统变量 log_statements_unsafe_for_binlog范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 ON如果遇到错误1592,控制是否产生警告添加到错误日志或不。 财产 价值 系统变量 master_verify_checksum范围 全球 动态 是 看到的是_ 提示应用 否 类型 布尔 默认值 OFF使这个变量会导致主检查校验当读取二进制日志。 master_verify_checksum默认是禁用的;在这种情况下,主使用二进制日志事件长度验证事件,所以只有完整的事件是从二进制日志读取。 财产 价值 命令行格式 --max-binlog-cache-size=#系统变量 max_binlog_cache_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 18446744073709551615最小值 4096最大值 18446744073709551615如果一个交易需要比这多个字节的内存,服务器产生一个 多语句事务需要超过“max_binlog_cache_size的字节的存储 误差。最小值是4096。可能的最大值是16eib(exbibytes)。建议的最大价值是4GB;这是由于MySQL目前无法使用二进制日志位置超过4GB。 max_binlog_cache_size集只为交易的缓存大小;对于语句缓存的上限是由 max_binlog_stmt_cache_size系统变量 能见度的会议 max_binlog_cache_size匹配的 binlog_cache_size系统变量;换句话说,改变它的值只会影响新的会话,该值后开始改变。 财产 价值 命令行格式 --max-binlog-size=#系统变量 max_binlog_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1073741824最小值 4096最大值 1073741824如果写入二进制日志导致当前日志文件的大小超过此变量的值时,服务器的二进制日志(关闭当前文件并打开下一个)。最小值是4096字节。最大值和默认值为1GB。 一个事务是写在一块的二进制日志,因此几个二进制日志之间没有分裂。因此,如果你有大的交易,你可能会看到二进制日志文件大于 max_binlog_size如果 max_relay_log_size0,价值 max_binlog_size适用于中继日志以及 财产 价值 命令行格式 --max-binlog-stmt-cache-size=#系统变量 max_binlog_stmt_cache_size范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 18446744073709547520最小值 4096最大值 18446744073709547520如果非事务语句在事务需要超过多少字节的内存,服务器会生成一个错误。最小值是4096。最大值和默认值32位平台上和16eb 4GB容量(字节)在64位平台。 max_binlog_stmt_cache_size集只有语句缓存的大小;对交易缓存上限是遵守 max_binlog_cache_size系统变量 财产 价值 介绍 8.0.1 状态变量 original_commit_timestamp范围 会话 动态 是 类型 数字 通过复制内部使用。当你执行一个事务上的奴隶,这是设置的时候,交易是在原来的主人承诺,以微秒计算新纪元后的。这让原本承诺的时间戳被传播到复制拓扑。 财产 价值 系统变量 sql_log_bin范围 会话 动态 是 看到的是_ 提示应用 否 类型 布尔 这个变量可以用来交换记录到二进制日志和关闭当前会话。默认值是1(二进制日志做的)。停止或为当前会话开始的二进制日志,改变这个变量的值的会话。会话的用户必须有 SYSTEM_VARIABLES_ADMIN或 SUPER权限设置这个变量 这是不可能的设置 @@session.sql_log_bin在一个事务或子查询 设置此变量为0防止gtids被分配到二进制日志中的事务 。如果你使用的是gtids复制,这意味着即使二进制日志后再次启用,该gtids写入的日志不占在此期间发生的任何交易,所以实际上这些交易损失。 财产 价值 命令行格式 --sync-binlog=#系统变量 sync_binlog范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1最小值 0最大值 4294967295控制多久MySQL服务器同步二进制日志到磁盘。 sync_binlog=0:禁用二进制日志磁盘同步MySQL服务器。相反,MySQL服务器依赖于操作系统冲洗二进制日志磁盘时,它的任何其他文件。此设置提供了最好的性能,但在一个断电或操作系统崩溃的事件,很可能是服务器已提交的事务没有被同步到二进制日志。 sync_binlog=1:使二进制日志同步到磁盘之前交易的承诺。这是最安全的设置,但可以对性能的磁盘数量增加的负面影响写。在一个断电或操作系统崩溃的事件,是从二进制日志丢失的交易只有在准备好的状态。这允许自动恢复程序回滚事务,保证没有交易是从二进制日志丢失。 sync_binlog=N,在那里 N除了0或1个值:二进制日志同步到磁盘后 N 二进制日志提交组已收集。在一个断电或操作系统崩溃的事件,很可能是服务器已提交的事务尚未刷新到二进制日志。这个设置会对性能产生由于磁盘数量增加的负面影响写。较高的值可以提高性能,但随着数据丢失的风险增加。
为最大可能的耐久性和一致性的复制设置,使用 InnoDB在交易中,使用这些设置: 注意安全 许多操作系统和磁盘硬件傻瓜刷新到磁盘操作。他们可能会告诉 mysqld ,冲洗已经发生,即使它没有。在这种情况下,交易的耐久性是不是推荐的设置保证,在最坏的情况下,停电可以腐败 InnoDB数据在SCSI磁盘控制器或磁盘本身加快文件刷新使用电池备份磁盘高速缓存,使操作更安全。你也可以尝试禁用缓存写入磁盘的硬件高速缓存。 transaction_write_set_extraction财产 价值 命令行格式 --transaction-write-set-extraction=[value]系统变量 transaction_write_set_extraction范围 全球会议 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 (>= 8.0.2)XXHASH64默认值 OFF有效值 OFFMURMUR32XXHASH64定义用于哈希写入事务期间的算法提取。如果您使用的是集团的复制,这个变量必须设置为 XXHASH64由于提取写从交易过程是在所有组成员的冲突检测要求。看到 第18.7.1,“组复制的要求” 笔记 这个变量的值不能被改变的时候 binlog_transaction_dependency_tracking设置两 writeset 或 WRITESET_SESSION
财产 价值 命令行格式 --enforce-gtid-consistency[=value]系统变量 enforce_gtid_consistency范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 OFF有效值 OFFONWARN当启用时,服务器执行gtid一致通过允许只陈述,可以安全地登录使用gtid执行。你 必须 设置此选项 ON在启用gtid以复制。 价值观 --enforce-gtid-consistency可配置是: OFF:所有的交易都不得违反gtid一致性。 ON:交易不允许违反gtid一致性。 WARN:所有的交易都不得违反gtid一致,但警告是在这种情况下产生的。
设置 --enforce-gtid-consistency没有价值的别名 --enforce-gtid-consistency=ON。这种影响在变量的行为,看 enforce_gtid_consistency只有报表,可以登录使用gtid安全声明可以登录时 enforce-gtid-consistency是集 打开(放) ,所以操作列在这里不能使用这个选项: 交易或语句更新事务和非事务表。有一个例外,非事务DML允许在同一事务中或在同一声明事务DML,如果所有 非事务性 桌子是暂时的
--enforce-gtid-consistency只有生效如果二进制日志发生的声明。如果二进制日志服务器上禁用,或者语句不写入二进制日志,因为它们通过过滤除去,gtid一致性不检查或执行不记录报表。 有关更多信息,参见 第17.1.3.6,”与GTIDs的“复制限制 --executed-gtids-compression-period财产 价值 命令行格式 --executed-gtids-compression-period=#过时的 是 类型 整数 默认值 1000最小值 0最大值 4294967295这个选项是过时的、将在未来的MySQL版本中删除。使用改名gtid_executed_compression_period控制如何gtid_executed表压缩。 财产 价值 命令行格式 --gtid-mode=MODE系统变量 gtid_mode范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 OFF有效值 OFFOFF_PERMISSIVEON_PERMISSIVEON此选项指定全局事务标识符(gtids)是用来确定交易。设置此选项 --gtid-mode=ON要求 enforce-gtid-consistency被设置为 打开(放) 。这个 gtid_mode变量是动态的,使gtid通过复制配置在线。在使用此功能之前,看到 第17.1.5,“改变复制模式的在线服务器” --gtid-executed-compression-period财产 价值 命令行格式 --gtid-executed-compression-period=#类型 整数 默认值 1000最小值 0最大值 4294967295压缩 mysql.gtid_executed表每次许多交易发生。0就是,这桌子不压缩。无压缩的表时发生的二进制日志启用,因此选择没有影响,除非 log_bin是 关闭 看到 mysql.gtid_executed表压缩 为更多的信息
财产 价值 命令行格式 --binlog-gtid-simple-recovery系统变量 binlog_gtid_simple_recovery范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 TRUE这个变量控制二进制日志文件迭代搜索gtids MySQL启动时,或重新启动时。 什么时候 binlog_gtid_simple_recovery=FALSE,迭代的二进制日志文件的方法: 初始化 gtid_executed,二进制日志文件进行迭代,从最新的文件,在第一个二进制日志有任何停止 以前_ gtids _ _事件日志 。。。。。。。从全gtids Previous_gtids_log_event和 gtid _ _事件日志 从这个二进制日志文件读取。这gtid集内部存储和调用 gtids_in_binlog。价值 gtid_executed计算这一套联盟和存储在该gtids mysql.gtid_executed 表 这个过程中如果你有大量的二进制日志文件没有gtid事件需要很长的时间,例如创建时 gtid_mode=OFF初始化 gtid_purged,二进制日志文件进行迭代,从最新的,在第一个二进制日志包含停 以前_ gtids _ _事件日志 这是非空(至少有一gtid)或至少有一个 Gtid_log_event。从这个二进制日志读取 以前_ gtids _ _事件日志 。这gtid集减去 gtids_in_binlog结果存储在内部变量 gtids _ _ binlog _ purged _ not in 。the value of gtid_purged初始化的值 gtid_executed,减 gtids _ _ binlog _ purged _ not in
什么时候 binlog_gtid_simple_recovery=TRUE,这是默认的服务器,只有最古老和最新的迭代的二进制日志文件和价值 gtid_purged和 gtid_executed计算仅基于 以前_ gtids _ _事件日志 或 Gtid_log_event在这些文件中找到。这确保了只有两个二进制日志文件在服务器重启时迭代二进制日志被清除。 笔记 如果启用此选项, gtid_executed和 gtid_purged可以初始化错误在以下情况: 最新的二进制日志是由MySQL 5.7.5以上生成的,和 gtid_mode是 打开(放) 对于一些二进制日志 OFF最新的二进制日志 一 SET GTID_PURGED声明是在之前5.7.7 MySQL版本的发布,和二进制日志,当时是活跃的 集gtid_purged 尚未清除
如果一个不正确的gtid集是在任何一种情况下计算的,它仍将是正确的即使服务器后重新启动,无论此选项的值。 如果你使用的是MySQL 5.7.7或更早,发卡后 SET gtid_purged声明记下当前的二进制日志文件的名称,它可以检查使用 SHOW MASTER STATUS。如果重新启动服务器之前,该文件已被清除,那么你应该使用 binlog_gtid_simple_recovery=FALSE为了避免 gtid_purged或 gtid_executed计算错误 财产 价值 命令行格式 --enforce-gtid-consistency[=value]系统变量 enforce_gtid_consistency范围 全球 动态 是 看到的是_ 提示应用 否 类型 枚举 默认值 OFF有效值 OFFONWARN根据这个变量的值,服务器执行gtid一致通过允许只陈述,可以安全地登录使用gtid执行。你 必须 设置这个变量 ON在启用gtid以复制。 价值观 enforce_gtid_consistency可配置是: OFF:所有的交易都不得违反gtid一致性。 ON:交易不允许违反gtid一致性。 WARN:所有的交易都不得违反gtid一致,但警告是在这种情况下产生的。
enforce_gtid_consistency只有生效如果二进制日志发生的声明。如果二进制日志服务器上禁用,或者语句不写入二进制日志,因为它们通过过滤除去,gtid一致性不检查或执行不记录报表。 在陈述,可以登录使用gtid基于复制的更多信息,参见 --enforce-gtid-consistencyMySQL 5.7中,发布系列的早期版本之前,布尔 enforce_gtid_consistency拖欠 关闭 。保持与这些早期版本的兼容性,枚举的默认值 OFF,和设置 --enforce-gtid-consistency没有值被解释为设定值 打开(放) 。变量也具有多重文本的别名值: 0=OFF=FALSE, 1=ON=TRUE, 2=WARN。这不同于其他的枚举类型但保持与以前版本的使用布尔类型的兼容性。这些变化对什么是由变量返回的影响。使用 选择@ @ enforce _ gtid _ consistency , SHOW VARIABLES LIKE 'ENFORCE_GTID_CONSISTENCY',和 SELECT * FROM INFORMATION_SCHEMA.VARIABLES WHERE 'VARIABLE_NAME' = 'ENFORCE_GTID_CONSISTENCY',所有返回的文本形式,不是数字的形式。这是一个不兼容的改变,因为 @@ENFORCE_GTID_CONSISTENCY返回值的形式返回布尔值,但在textual形式 商展 和信息架构 executed_gtids_compression_period财产 价值 过时的 是 系统变量 executed_gtids_compression_period范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1000最小值 0最大值 4294967295这个选项是过时的、将在未来的MySQL版本中删除。使用改名 gtid_executed_compression_period控制如何 gtid _ executed 表压缩 财产 价值 系统变量 gtid_executed系统变量 gtid_executed范围 全球 范围 全球会议 动态 否 动态 否 看到的是_ 提示应用 否 看到的是_ 提示应用 否 类型 字符串 当使用全球范围,这个变量包含在服务器和gtids已由执行所有交易集的表现 SETgtid_purged声明。This is the same as the value of the executed_gtid_set 输出中的列 SHOW MASTER STATUS和 SHOW SLAVE STATUS。这个变量的值是一个gtid集,看 gtid集 更多信息 当服务器启动时, @@global.gtid_executed初始化。看到 binlog_gtid_simple_recovery在二进制日志迭代填充更多的信息 gtid_executed。gtids然后添加到设置为执行交易,或任何 SETgtid_purged语句被执行 交易可以在任何时间在二进制日志发现集等于 GTID_SUBTRACT(@@global.gtid_executed, @@global.gtid_purged);即在尚未清除的二进制日志中的所有交易。 发行 RESET MASTER导致全球价值(而不是会话值)这一变量被重置为空字符串。gtids否则从这组比其他组清除由于时 复位大师 在一些较老的版本,这个变量也可以用于会话作用域,它包含的是写在当前会话缓存事务集的表现。现在已经不再使用的会话范围。 gtid_executed_compression_period财产 价值 系统变量 gtid_executed_compression_period范围 全球 动态 是 看到的是_ 提示应用 否 类型 整数 默认值 1000最小值 0最大值 4294967295压缩 mysql.gtid_executed表每次都这样多的交易被处理。0就是,这桌子不压缩。由于没有压缩的表时使用二进制日志时,设置该变量的值没有影响,除非禁用二进制日志。 看到 mysql.gtid_executed表压缩 为更多的信息 控制是否启用基于gtid测井是什么类型的交易记录可以包含。你必须有 SYSTEM_VARIABLES_ADMIN或 SUPER权限设置这个变量 enforce_gtid_consistency你可以设置前必须是真实的 gtid_mode=ON。在修改这个变量,看 第17.1.5,“改变复制模式的在线服务器” 记录的事务可以匿名或使用gtids。匿名交易依靠二进制日志文件和位置来确定具体的交易。gtid交易有一个独特的标识,是指交易。不同的模式: OFF:新复制的事务必须是匿名的。 OFF_PERMISSIVE:新的交易是匿名的。复制的事务可以匿名或gtid交易。 ON_PERMISSIVE:新的交易gtid交易。复制的事务可以匿名或gtid交易。 ON:新复制的事务必须gtid交易。
从一个值与另一个变化,只能一步一个脚印。例如,如果 gtid_mode目前将 off_permissive ,它是可能的变化 OFF或 on_permissive 但不 ON价值观 gtid_purged和 gtid_executed无论是持久的价值 gtid_mode。因此,即使改变的价值 gtid_mode,这些变量包含正确的价值观。 该变量用于指定是否以及如何获得下一gtid。 gtid_next可以采取以下任何值: AUTOMATIC:用下自动生成全局事务ID。 ANONYMOUS:交易没有全局标识符,并确定文件位置。 全局事务ID UUID: NUMBER格式
正是上述哪种选择都是有效取决于设置 gtid_mode,看到 17.1.4.1,“复制模式” 更多信息。设置这个变量没有影响,如果 gtid_mode是 关闭 在这个变量被设置为 UUID: NUMBER,和事务已提交或回滚,显 集gtid_next 声明必须再在任何其他声明。 DROP TABLE或 DROP TEMPORARY TABLE没有明确的错误时使用相结合的非临时表或临时表,临时表和临时表使用事务性存储引擎使用非事务性存储引擎。 财产 价值 系统变量 gtid_owned范围 全球会议 动态 否 看到的是_ 提示应用 否 类型 字符串 这个只读变量保存一个列表的内容取决于其范围。当使用会话范围,列表保存所有gtids是这个客户所有;当使用全球范围内,它拥有一个列表中的所有gtids连同他们的主人。 财产 价值 系统变量 gtid_purged范围 全球 动态 是 看到的是_ 提示应用 否 类型 字符串 所有交易已经从二进制日志清除设置。这是交易的一个子集 gtid_executed。这个变量的值是一个gtid集,看 gtid集 更多信息 当服务器启动时,全球价值 gtid_purged初始化为一组gtids。看到 binlog_gtid_simple_recovery在二进制日志迭代填充更多的信息 gtid_purged。。。。。。。发行 RESET MASTER导致这一变量的值被重置为空字符串。 有两种方式设置 gtid_purged。什么时候 gtid _看到 是一个超集 gtid_purged,和不相交 gtid _ subtract(gtid _ executed - gtid _ purged) 使用 SET @@GLOBAL.GTID_PURGED = 'gtid_set'
结果是, GTID_PURGED等于 gtid _看到 ,和 GTID_EXECUTED成为联盟 gtid _看到 和以前的值 GTID_EXECUTED什么时候 gtid_set不相交 gtid _ executed 使用 SET @@GLOBAL.GTID_PURGED = '+gtid_set'
结果是, gtid_set被添加到 gtid _ executed 和 gtid_purged如果二进制日志从MySQL 5.7.7或更早的存在,这是一个机会, gtid_purged可计算错误 binlog_gtid_simple_recovery=TRUE。看到 binlog_gtid_simple_recovery更多信息 simplified_binlog_gtid_recovery财产 价值 命令行格式 --simplified-binlog-gtid-recovery过时的 是 系统变量 simplified_binlog_gtid_recovery范围 全球 动态 否 看到的是_ 提示应用 否 类型 布尔 默认值 FALSE这个选项是过时的、将在未来的MySQL版本中删除。使用改名 binlog_gtid_simple_recovery控制MySQL如何遍历二进制日志文件之后崩溃。
SHOW SLAVE STATUS
SHOW STATUSSHOW
STATUS
MASTER_HEARTBEAT_PERIODCHANGE MASTER
TOslave_net_timeoutreplication_connection_status
SHOW SLAVE
STATUS
MySQL的> SHOW SLAVE STATUS\G*************************** 1。行*************************** slave_io_state:等待主人送事件master_host:Master1 master_user:根master_port:3306 connect_retry:60 master_log_file:mysql-bin.000004 read_master_log_pos:931 relay_log_file:slave1-relay-bin.000056 relay_log_pos:950 relay_master_log_file:mysql-bin.000004 slave_io_running:是的slave_sql_running:是的replicate_do_db:replicate_ignore_db:replicate_do_table:replicate_ignore_table:replicate_wild_do_table:replicate_wild_ignore_table:last_errno:0 last_error:skip_counter:0 exec_master_log_pos:931:1365:没有relay_log_space until_condition until_log_file:until_log_pos:0 master_ssl_allowed:没有master_ssl_ca_file:master_ssl_ca_path:master_ssl_cert:master_ssl_cipher:master_ssl_key:seconds_behind_master:0master_ssl_verify_server_cert:没有last_io_errno:0 last_io_error:last_sql_errno:0 last_sql_error:replicate_ignore_server_ids:0
Slave_IO_State:奴隶的现状。看到 第8.14.4,“复制从I/O线程状态” ,和 第8.14.5,“SLAVE端状态” 为更多的信息 Slave_IO_Running:是I/O线程读取主人的二进制日志运行。通常情况下,你想这是 是 如果你还没有开始复制或有明确停止它 STOP SLAVESlave_SQL_Running:无论是在继电器执行事件日志的SQL线程正在运行。与I/O线程,这通常应 是 Last_IO_Error, last_sql_error 错误:最后的I / O和SQL线程在处理中继日志注册。最理想的是这些应该是空白的,表示没有错误。 Seconds_Behind_Master:那从SQL线程在处理主二进制日志的秒数。大量(或增加)表明奴隶无法处理及时掌握事件。 值为0 Seconds_Behind_Master通常可以被解释为意味着奴隶已经赶上了主人,但在某些情况下,这是不完全正确。例如,这可以如果主人和奴隶之间的网络连接断开但从I/O线程尚未注意到这是发生, slave_net_timeout尚未逝去 它也有可能是瞬时值 Seconds_Behind_Master可能无法准确反映情况。当从SQL线程已经赶上了I / O, seconds_behind_master 显示0;但当奴隶的I/O线程仍在排队的一个新的事件, Seconds_Behind_Master可以在SQL线程执行完新的事件显示一个大的价值。这是可能的事件时有旧的时间戳;在这种情况下,如果执行 SHOW SLAVE STATUS在一个相对较短的时期内几次,你可能会看到这个值的变化来回反复0个比较大的值之间。
( Master_Log_file, read_master_log_pos ):坐标系在掌握二进制日志显示多远从I/O线程读取事件日志。 ( Relay_Master_Log_File, exec_master_log_pos ):在掌握二进制日志显示多远从SQL线程执行日志接收事件的坐标。 ( Relay_Log_File, relay_log_pos ):指示多远从SQL线程执行中继日志从中继日志坐标。这与前面的坐标,但在奴隶的中继日志表示坐标而不是掌握二进制对数坐标。
SHOW PROCESSLISTCommand
MySQL的> SHOW PROCESSLIST \G;***************************四。行***************************编号:10用户:根主持人:slave1:58371分贝:nullcommand:binlog转储时间:777状态:已发送的所有binlog奴隶;等待binlog要更新信息:空
--report-hostSHOW SLAVE
HOSTS--report-host
MySQL的> SHOW SLAVE HOSTS;----------- -------- ------ ------------------- ----------- | server_id |主机|港口| rpl_recovery_rank | master_id | ----------- -------- ------ ------------------- ----------- | 10 | slave1 | 3306 | 0 | 1 | ----------- -------- ------ ------------------- ----------- 1行集(0秒)
STOP SLAVESTART SLAVE
STOP SLAVE
MySQL的> STOP SLAVE;
mysql>STOP SLAVE IO_THREAD;mysql>STOP SLAVE SQL_THREAD;
START
SLAVE
MySQL的> START SLAVE;
mysql>START SLAVE IO_THREAD;mysql>START SLAVE SQL_THREAD;
SELECT
基于二进制日志语句时,主写SQL语句的二进制日志。对主从复制作品通过执行SQL语句的奴隶。这就是所谓的 基于语句的复制 (可简称为 SBR ),对应的二进制日志格式MySQL语句。 使用基于行的记录时,大师写的 事件 的二进制日志表明每个表行的改变。对主从复制作品抄袭事件代表变化的表行的奴隶。这就是所谓的 基于行的复制 (可简称为 RBR ) 基于行的记录是默认的方法。 您也可以配置MySQL使用两者的混合语句基础和基于行的记录,这是最适当的改变被记录。这就是所谓的 混合格式记录 。采用混合格式记录时,声明是基于日志的默认使用。根据一定的陈述,而且存储引擎被使用,日志自动切换到基于行的特殊情况。采用混合格式复制被称为 混合型复制 或 混合格式的复制 。有关更多信息,参见 第5.4.4.3,“混合二进制日志格式”
MIXED
binlog_format
SYSTEM_VARIABLES_ADMINSUPERbinlog_format
基于语句复制的优势
成熟的技术 较少的数据写入到日志文件。当更新或删除的行数的影响,这样的结果 许多的 日志文件需要的存储空间少。这也意味着,以及从备份恢复可以实现更迅速。 日志文件包含所有报表所做的任何更改,因此可以用来审计数据库。
基于语句复制的缺点
陈述,SBR是不安全的。 不是所有的语句修改数据(如 INSERTDELETE, UPDATE,和 REPLACE语句)可以复制使用基于语句的复制。任何具有不确定性的行为是难以复制的使用基于语句的复制时。这样的数据修改语言实例(DML)语句包括以下: 一个声明,取决于UDF或存储的程序,是不确定的,因为价值的UDF或存储程序或返回取决于为其提供的参数以外的其他因素。(基于行的复制,然而,简单的重复值的UDF或存储程序,返回等表行和数据的影响是对主人和奴隶一样)看 第17.4.1.16”功能,调用“复制 为更多的信息 DELETE和 UPDATE语句的使用 极限 条款没有 ORDER BY是不确定的。欧洲经济区 第17.4.1.18,“复制和限制” 锁定读语句( SELECT ... FOR UPDATE和 SELECT ... FOR SHARE),使用 不等待 或 SKIP LOCKED选项看到 锁定读并发NOWAIT跳过锁定 确定性的UDF必须应用于奴隶。 使用下列功能不可复制的合理使用基于语句的复制语句: 然而,所有其他功能复制正确使用基于语句的复制,包括 NOW()等等 有关更多信息,参见 第17.4.1.14,“复制和系统功能”
语句不能被复制的正确使用基于语句的复制是一个警告,如图中所示的记录: [Warning] Statement is not safe to log in statement format.
类似的警告也在这样的情况下,向客户发出。客户端可以显示它的使用 SHOW WARNINGSINSERT ... SELECT需要比基于行的复制更多的行级锁数。 UPDATE声明要求表扫描(因为没有索引中使用 哪里 条款)必须锁比基于行的复制更多的行数。 对于复杂的语句,该语句必须是评估和执行的奴隶在更新或插入行。与基于行的复制,奴隶只需要修改受影响的行,不执行完整的声明。 如果有奴隶在评估错误,特别是当执行复杂的报表,基于语句的复制可能会慢慢增加,误差幅度在受影响的行的时间。看到 第17.4.1.29,“从错误中复制” 存储函数执行同 NOW()值调用语句。然而,这不是真正的存储过程。 确定性的UDF必须应用于奴隶。 表的定义必须相同(近)在主人和奴隶。看到 第17.4.1.9,“复制不同的表定义在大师和Slave” 为更多的信息
基于行复制的优势
所有的变化可以复制。这是最安全的方式复制。 笔记 报表中的信息更新 mysql数据库等 GRANT, REVOKE和触发器的操作,存储程序(包括存储过程),和观点都复制到使用基于语句的复制的奴隶。 对于这样的语句 CREATE TABLE ... SELECT,一个 创造 语句从表定义中生成和复制使用基于语句的格式,而该行插入复制使用基于行的格式。 少行锁在主的要求,从而达到更高的并发性,下列类型的语句: INSERT报表 汽车
基于行复制的缺点
RBR可以产生更多的数据,必须登录。复制一个DML语句(如 UPDATE或 DELETE表),通过复制只写入到二进制日志语句声明。相比之下,基于行的复制写入每个改变行到二进制日志。如果语句修改多行、基于行的复制可能会写更多的数据以二进制日志;这甚至语句回滚是真实的。这也意味着制作和还原备份可能需要更多的时间。此外,二进制日志锁定更长的时间去写数据,这可能会导致并发问题。使用 binlog_row_image=minimal的缺点大大减少 确定性的UDF,产生大 BLOB比基于语句的复制值需要更长的时间才能与基于行的复制复制。这是因为 BLOB记录的列值,而不是语句生成数据。 你不能看到什么语句是从奴隶主和执行接收。然而,你可以看到哪些数据被改变使用 mysqlbinlog 与选择 --base64-output=DECODE-ROWS和 --verbose另外,使用 binlog_rows_query_log_events变量,如果启用添加 rows_query 用语句事件 mysqlbinlog 输出时 -vv选择使用 表格的使用 MyISAM存储引擎,更强的锁需要的奴隶 INSERT当应用它们作为基于行的事件到二进制日志的时候比运用其作为陈述。这意味着并发的插入 MyISAM表不使用基于行的复制时的支持。
基于行的临时表的记录。 正如在 第17.4.1.31,“复制与临时表” ,临时表不复制使用基于行的格式或当(从MySQL 8.0.4)混合格式。有关更多信息,参见 第17.2.1.1,”优势和基础,基于行的复制”语句的缺点 临时表是不可复制的当使用基于行的或混合的格式,因为没有必要。此外,因为临时表只能从它创建线程读,也很少有效益的复制他们,即使采用基于语句的格式。 你可以从表为基础的基于行的二进制日志格式在运行时即使临时表已创建。然而,从MySQL 8.0.4,你不能从基于行的或混合的二进制日志的格式在运行时,报表格式转换,因为任何 CREATE TEMPORARY TABLE报表将已经从以前的模式的二进制日志略。 从MySQL 8,MySQL服务器跟踪日志记录模式是在每个临时表的创建。当一个客户端会话结束时,服务器日志 DROP TEMPORARY TABLE IF EXISTS声明每个临时表仍然存在并时创建基于二进制日志语句使用。如果基于行的或混合格式的二进制日志是在创建表时,该 删除临时表是否存在 声明中没有记录。在MySQL 8的 DROP TEMPORARY TABLE IF EXISTS语句被记录的记录模式,实际上是。 非事务性的临时表的DML语句时允许使用 binlog_format=ROW,只要任何非事务表的语句影响的临时表(bug # 14272672)。 RBL和非事务表同步。 当许多行受到影响,变化集分为几个事件;当声明承诺,所有这些事件都写入二进制日志。当执行的奴隶,一个表锁了所有的表,然后行用于批处理模式。根据用于表的奴隶的复制引擎,这可能会或可能不会有效。 潜伏期和二进制日志大小。 RBL写的每一行的二进制日志等的变化,其大小可以增加很快。这会大大增加需要的奴隶,与那些在主做出改变的时间。你应该意识到这种延迟你的应用的潜力。 读取二进制日志 mysqlbinlog 显示行中的事件使用二进制日志 BINLOG声明(见 第13.7.7.1”binlog语法” )。这一声明显示事件为base 64编码的字符串,其中的意义是不明显的。当调用的 --base64-output=DECODE-ROWS和 --verbose选项, mysqlbinlog 格式的二进制日志的内容是人类可读的。当二进制日志事件编写的基于行的格式,你想阅读或复制或数据库失败,你可以使用此命令来读取二进制日志的内容恢复。有关更多信息,参见 第4.6.8.2,“mysqlbinlog行事件显示” 二进制日志执行错误和slave_exec_mode。 如果 slave_exec_mode是 幂等 ,未能应用更改从RBL由于原行不能找到不触发一个错误或导致复制失败。这意味着,它可能是更新不适用于奴隶,使主人和奴隶不再同步。延迟问题和使用非事务表与RBR的时候 slave_exec_mode是 幂等 能使主人和奴隶的分歧进一步。为更多的信息关于 slave_exec_mode,看到 第5.1.7,服务器“系统变量” 笔记 slave_exec_mode=IDEMPOTENT一般只能用于循环复制或MySQL集群的多主复制,这 幂等 是默认值。其他情况下,设置 slave_exec_mode到 严格 通常是足够的,而且是默认值。 基于服务器ID不支持过滤。 你可以过滤基于服务器ID用 IGNORE_SERVER_IDS选择的 CHANGE MASTER TO声明。此选项与语句基础和基于行的日志格式,但使用时使用 GTID_MODE=ON是集。过滤出的变化对一些奴隶,另一种方法是使用一个 哪里 条款,包括关系 @@server_id <>id_value条款 UPDATE和 DELETE声明.例如, WHERE @@server_id <> 1。然而,这并不是正确的工作与基于行的日志。使用 server_id语句过滤系统变量,使用基于语句的日志。 数据库级的复制选项 的影响 --replicate-do-db, --replicate-ignore-db,和 --replicate-rewrite-db选项有很大不同,根据是否行或基于语句基础测井应用。因此,建议避免数据库级选项,而是使用表级选项如 --replicate-do-table和 --replicate-ignore-table。更多关于这些选项的信息和影响复制的格式对他们如何运作,看 第17.1.6,“复制和二进制日志记录选项和变量” 非事务表,Rb1、停的奴隶。 使用基于行的记录时,如果服务器是当奴隶线程更新非事务表停了下来,从数据库可以达成一致的状态。出于这个原因,建议您使用事务性存储引擎等 InnoDB所有表复制使用的格式的行。使用 STOP SLAVE或 STOP SLAVE SQL_THREAD关闭从MySQL服务器有助于防止问题发生之前,总是推荐的日志格式或存储引擎使用。
binlog_format
使用基于行的记录时,没有区别,在安全和不安全的报表处理。 采用混合格式记录时,声明标记为不安全登录基于格式的行;陈述视为安全登录使用的格式声明。 采用基于语句的记录时,声明标记为不安全产生这种效果的警告。安全报表记录正常。
ER_BINLOG_UNSAFE_STATEMENTNS
包含系统功能,可能会返回不同的值报表的奴隶。 这些功能包括 FOUND_ROWS(), GET_LOCK(), IS_FREE_LOCK(), IS_USED_LOCK(), LOAD_FILE(), MASTER_POS_WAIT(), RAND(), RELEASE_LOCK(), ROW_COUNT(), SESSION_USER(), SLEEP(), SYSDATE(), SYSTEM_USER(), USER(), UUID(),和 UUID_SHORT()不确定性函数不被认为是不安全的。 虽然这些功能是不确定的,他们被视为安全日志和复制的目的: CONNECTION_ID(), CURDATE(), CURRENT_DATE(), CURRENT_TIME(), CURRENT_TIMESTAMP(), CURTIME(),, LAST_INSERT_ID(), LOCALTIME(), LOCALTIMESTAMP(), NOW(), UNIX_TIMESTAMP(), UTC_DATE(), UTC_TIME(),和 UTC_TIMESTAMP()有关更多信息,参见 第17.4.1.14,“复制和系统功能” 系统变量的引用 大多数的系统变量是不可复制的正确使用为基础的格式声明。看到 第17.4.1.39,“复制和变量” 。例外情况,看 第5.4.4.3,“混合二进制日志格式” UDFs 既然我们无法控制什么UDF,我们必须假定它是执行不安全的声明。 全文插件 这个插件可以有不同的行为在不同的MySQL服务器;因此,取决于它的声明可能有不同的结果。因为这个原因,所有的语句都依靠全文插件被视为不安全的MySQL。 触发器或存储程序的更新具有auto_increment列表。 这是因为在不安全的行为可更新的主人与奴隶的区别。 此外,一个 INSERT为表有一个主键包含 汽车 列那不是这个组合键的第一列是不安全的。 有关更多信息,参见 第17.4.1.1,“复制和auto_increment” 插入…在重复的密钥更新报表与多个主键或唯一键的表。 当执行对一个表,包含多个主键或唯一键,这种说法是不安全的,在其中存储引擎检查按键顺序敏感,这是不确定的,在这行的MySQL服务器更新的选择取决于。 一个 INSERT ... ON DUPLICATE KEY UPDATE声明对具有一个以上的唯一或主键被标记为不安全的基于语句的复制表。(错误# 11765650,错误# 58637) 更新使用限制 没有指定哪些行检索顺序,因此被认为是不安全的。看到 第17.4.1.18,“复制和限制” 访问或引用日志表 系统的日志表的内容可能主人和奴隶之间的不同。 非事务性操作在事务性操作。 在一个事务内,允许任何非事务读取或写入任何事务读取或写入后被认为不安全的执行。 有关更多信息,参见 第17.4.1.35,“复制和交易” 访问或引用自记录表 所有的读和写自我记录表被认为是不安全的。在一个事务中,任何语句在读取或写入日志表自我也被认为是不安全的。 LOAD DATA INFILE语句。 LOAD DATA INFILE被视为不安全的,当 binlog_format=mixed声明中记录的基于行的格式。什么时候 binlog_format=statementLOAD DATA INFILE不会产生一个警告,不像其他不安全的声明。 XA事务 如果两XA事务提交并联在主正在对反奴隶的准备,锁定的依赖可以基于语句的复制不能安全地解决发生的,并有可能复制失败对奴隶的僵局。什么时候 binlog_format=STATEMENT是集,DML语句在XA事务被标记为不安全的,产生一个警告。什么时候 binlog_format=MIXED或 binlog_format=ROW是集,DML语句在XA事务记录使用基于行的复制,和潜在的问题是不存在的。
binlog转储线程。 掌握创建一个线程发送二进制日志的内容到一个奴隶当奴隶的连接。该线程可以在输出的确定 SHOW PROCESSLIST在主的 binlog转储 线 二进制日志转储线程获得阅读每个事件被发送到奴隶对主人的二进制日志锁。当事件被读取,锁被释放,甚至在事件发送到奴隶。 从I/O线程 当一个 START SLAVE声明是在从服务器发出的,从创建一个I/O线程,连接到主向它发送记录在其二进制日志的更新。 从I/O线程读取更新的主人 Binlog Dump线程发送(见以前的项目)并将其复制到本地文件,包括奴隶的中继日志。 这个线程的状态显示为 Slave_IO_running在输出 SHOW SLAVE STATUS或为 Slave_running在输出 SHOW STATUS从SQL线程 从创建一个SQL线程读取中继日志,写的是奴隶的I/O线程并执行其中包含的事件。
SHOW PROCESSLIST
SHOW PROCESSLIST
SHOW
PROCESSLIST
MySQL的> SHOW PROCESSLIST\G*************************** 1。行***************************编号:2用户:根主持人:本地:32931分贝:nullcommand:binlog转储时间:94状态:已发送的所有binlog奴隶;等待binlog要更新信息:空
Binlog DumpBinlog Dump
SHOW
PROCESSLIST
MySQL的> SHOW PROCESSLIST\G*************************** 1。行***************************编号:10用户:系统用户主机:数据库:nullcommand:连接时间:11状态:等待主人发送事件信息:空*************************** 2。行***************************编号:11用户:系统用户主机:数据库:nullcommand:连接时间:11状态:已阅读所有中继日志;等待Slave I/O线程更新信息:空
StateSHOW PROCESSLIST
TimeBinlog
Dumpnet_retry_count
SHOW SLAVE STATUS
""
FOR CHANNEL
channel
channel
group_replication_recovery
FOR
CHANNEL channel
START SLAVE开始为所有通道复制线程,除了 group_replication_recovery 频道 STOP SLAVE停止复制线程的所有渠道,除了 group_replication_recovery 频道 SHOW SLAVE STATUS报告所有通道的状态 FLUSH RELAY LOGS将中继日志的所有通道。 RESET SLAVE重置所有渠道
RESET SLAVE
FOR CHANNEL channel
这必须设置 TABLE。如果此选项设置为 文件 ,尝试添加更多的资源从失败 ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。这个 文件 设置现在已经过时,而 TABLE是默认的 --master-info-repository这必须设置 TABLE。如果此选项设置为 文件 ,尝试添加更多的资源从失败 ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。这个 文件 设置现在已经过时,而 TABLE是默认的
由从收到的所有交易(甚至从多个来源)是用二进制日志。 当设置,每个通道的中继日志自动清洗。 应用线程的所有通道重试交易。 没有复制线程开始在任何渠道。 继续执行和错误是跳过所有通道。
--max-relay-log-size=size每个通道的单独的中继日志文件的最大大小;达到此限制后,文件旋转。 --relay-log-space-limit=size为所有中继日志组合总规模上限,每个通道。为 N渠道,这些日志的大小是有限的 relay_log_space_limit *N--slave-parallel-workers=value从平行的工人每通道数。 --slave-checkpoint-group等待的时间由一个I/O线程为每个源。 --relay-log-index=filename每个通道的中继日志索引文件的基名称。看到 第17.2.3.4,“复制通道命名约定” --relay-log=filename是指每个通道的中继日志文件的基名称。看到 第17.2.3.4,“复制通道命名约定” --slave_net-timeout=N这个值设置每个通道,使每个通道等待 N秒检查断开的连接 --slave-skip-counter=N这个值设置每个通道,使每个通道跳过 N从主事件
group_replication_appliergroup_replication_recovery
relay_log_basename-channel.xxxxxxrelay_log_basename--relay-logchannel--relay-log
这个 中继日志 由主人的二进制日志读写的事件,从I/O线程。在中继日志事件执行的奴隶为SQL线程的一部分。 这个 掌握信息日志 包含奴隶的连接到主状态和当前配置信息。此日志保存在主域名,信息的登录凭据,和坐标显示多远的奴隶从主人的二进制日志读取。船长日志写入 mysql.slave_master_info表 这个 中继日志信息的日志 保存状态信息的执行点在奴隶的中继日志。中继日志写入 mysql.slave_relay_log_info表
slave_master_info
slave_master_info
mysql.slave_master_infoInnoDB--relay-log-recovery
host_name-relay-bin.nnnnnnhost_namennnnnnhost_name-relay-bin-channelchannel
host_name-relay-bin.indexhost_namechannel
--relay-log--relay-log-index
--relay-log--relay-log-index
shell>catshell>new_relay_log_name.index >>old_relay_log_name.indexmvold_relay_log_name.indexnew_relay_log_name.index
每一次I/O线程开始。 当日志刷新;例如,用 FLUSH LOGS或 mysqladmin刷新日志 当电流继电器的日志文件的大小变得太大,这是确定如下: 如果价值 max_relay_log_size大于0,即最大中继日志文件大小。 如果价值 max_relay_log_size0, max_binlog_size确定最大中继日志文件大小。
FLUSH LOGS
InnoDBslave_master_info
SHOW SLAVE
STATUS
--master-info-repository=TABLE--relay-log-info-repository=TABLErelay-log.info--master-info-file--relay-log-info-file
mysql.slave_master_infoInnoDB--relay-log-recovery
mysql.slave_worker_inforeplication_applier_status_by_worker
mysql.slave_master_infoSHOW SLAVE STATUS
slave_master_info | SHOW SLAVE STATUS | master.info | |
|---|---|---|---|
Number_of_lines | |||
Master_log_name | Master_Log_File | ||
Master_log_pos | Read_Master_Log_Pos | ||
Host | Master_Host | ||
User_name | Master_User | ||
User_password | SHOW SLAVE STATUS | ||
Port | Master_Port | ||
Connect_retry | Connect_Retry | ||
Enabled_ssl | Master_SSL_Allowed | ||
Ssl_ca | Master_SSL_CA_File | ||
Ssl_capath | Master_SSL_CA_Path | ||
Ssl_cert | Master_SSL_Cert | ||
Ssl_cipher | Master_SSL_Cipher | ||
Ssl_key | Master_SSL_Key | ||
Ssl_verify_server_cert | Master_SSL_Verify_Server_Cert | ||
Heartbeat | |||
Bind | Master_Bind | ||
Ignored_server_ids | Replicate_Ignore_Server_Ids | Ignored_server_ids | |
Uuid | Master_UUID | ||
Retry_count | Master_Retry_Count | ||
Ssl_crl | |||
Ssl_crl_path | |||
Enabled_auto_position | Auto_position | ||
Channel_name | Channel_name | ||
Tls_Version | Master_TLS_Version | ||
Master_public_key_path | Master_public_key_path | ||
Get_master_public_key | Get_master_public_key |
mysql.slave_relay_log_infoSHOW SLAVE
STATUS
slave_relay_log_info | SHOW SLAVE STATUS | relay-log.info | |
|---|---|---|---|
Number_of_lines | |||
Relay_log_name | Relay_Log_File | ||
Relay_log_pos | Relay_Log_Pos | ||
Master_log_name | Relay_Master_Log_File | ||
Master_log_pos | Exec_Master_Log_Pos | ||
Sql_delay | SQL_Delay | ||
Number_of_workers | |||
Id | |||
Channel_name |
mysql.slave_master_infoCHANGE MASTER TOMASTER_LOG_POS
--binlog-do-db--binlog-ignore-db
--replicate-*CHANGE REPLICATION FILTERCHANGE REPLICATION
FILTER
--replicate-*
--replicate-do-db--replicate-ignore-db
CREATE DATABASEDROP DATABASEALTER DATABASE--replicate-wild-do-table--replicate-wild-do-table
--replicate-rewrite-db
lower_case_table_names
--replicate-do-db--replicate-ignore-db--binlog-do-db--binlog-ignore-db
USE
binlog_format=ROWUSE
日志格式的使用? 声明 默认的数据库测试 行 受变更影响的数据库测试。
有什么 --replicate-do-db选择? 是 数据库是否匹配吗? 是 继续前进 否 忽视更新和退出
否 继续前进
有什么 --replicate-ignore-db选择? 是 数据库是否匹配吗? 是 忽视更新和退出 否 继续前进
否 继续前进
继续检查表级复制选项,如果有任何。为说明这些选项进行检查,看 第17.2.5.2,“评价表级复制选项” 重要 声明还允许在这个阶段还没有真正执行。声明是直到所有表级别选项执行(如果有的话)也进行了检查,并对过程结果的语句执行许可证。
有什么 --binlog-do-db或 --binlog-ignore-db选择? 是 continue to 2步。 否 日志声明退出
有一个默认的数据库(有数据库的选择 USE)? 是 继续前进 否 忽略声明退出
有一个默认的数据库。有什么 --binlog-do-db选择? 是 做任何匹配的数据库? 是 日志声明退出 否 忽略声明退出
否 继续前进
做任何的 --binlog-ignore-db选项匹配的数据库? 是 忽略声明退出 否 日志声明退出
CREATE
DATABASEALTER
DATABASEDROP
DATABASE
--binlog-do-db--binlog-do-db=salessales
没有匹配的数据库选项被发现。 一个或多个数据库选项被发现,并进行了评估,得出一个 “ 执行 “ 根据前一节中描述的规则条件(见 第17.2.5.1,“数据库级的复制和二进制日志记录选项”的评价 )
UPDATE mytable SET mycol =
1
--replicate-do-table--replicate-wild-do-table--replicate-ignore-table--replicate-wild-ignore-table
有表的复制选项? 是 continue to 2步。 否 执行更新和退出
日志格式的使用? 声明 进行其余步骤每个语句执行更新。 行 进行其余步骤每更新一个表的行。
有什么 --replicate-do-table选择? 是 不表匹配吗? 是 执行更新和退出 否 继续前进
否 继续前进
有什么 --replicate-ignore-table选择? 是 不表匹配吗? 是 忽视更新和退出 否 继续前进
否 继续前进
有什么 --replicate-wild-do-table选择? 是 不表匹配吗? 是 执行更新和退出 否 继续下去
否 继续下去
有什么 --replicate-wild-ignore-table选择? 是 不表匹配吗? 是 忽视更新和退出 否 继续前进
否 继续前进
还有另一个表进行测试? 是 回到步骤3 否 继续前进
有什么 --replicate-do-table或 --replicate-wild-do-table选择? 是 忽视更新和退出 否 执行更新和退出
--replicate-do-table--replicate-wild-do-table--replicate-ignore-table--replicate-wild-ignore-tablebinlog_format=ROW
--replicate-* | |
--replicate-*-db | |
--replicate-*-table | |
mytbl1mytbl2
replicate-ignore-db = db1 replicate-do-table = db2.tbl2
USE db1; INSERT INTO db2.tbl2 VALUES (1);
USE--replicate-ignore-dbINSERT
USE--replicate-ignore-dbINSERT--replicate-do-table
group_replication_applier
任何全球复制筛选器指定添加到过滤式过滤器(全球复制 do_db, do_ignore_table ,等等) 任何特定渠道复制滤镜增加过滤器指定通道的复制指定的过滤式过滤器。 每个从复制通道副本复制的通道滤波器全球特定复制过滤器如果这类没有特定渠道复制过滤器配置。 每个通道使用其特定渠道复制滤镜复制流。
CHANGE REPLICATION FILTER--replicate-*filter_type=channel_namefilter_detailschannel_2--replicate-do-db=db1--replicate-do-db=channel_1:db2--replicate-do-db=db3--replicate-ignore-db=db4--replicate-ignore-db=channel_2:db5
全球复制过滤器 : do_db=db1,db3, ignore_db=db4通道特定的过滤器channel_1 : do_db=db2 ignore_db=db4通道特定的过滤器channel_2 : do_db=db1,db3 ignore_db=db5
replication_applier_global_filtersreplication_applier_filters
channel
--replicate-do-db=channel:database_id--replicate-ignore-db=channel:database_id--replicate-do-table=channel:table_id--replicate-ignore-table=channel:table_id--replicate-rewrite-db=channel:db1-db2--replicate-wild-do-table=channel:table regexid--replicate-wild-ignore-table=channel:table regexid
channel--replicate-do-db=:database_idchannel--replicate-do-db=database_id--replicate-do-db
rewrite-db=from_name->to_namefrom_name
--replicate-*CHANGE REPLICATION FILTERchannel
CHANGE REPLICATION FILTER REPLICATE_DO_DB=(db1) FOR CHANNEL channel_1;
FOR CHANNELdo_ignore_tableFOR
CHANNEL
REPLICATE_REWRITE_DB
CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB=() FOR CHANNEL channel_1;
REPLICATE_REWRITE_DBCHANGE REPLICATION FILTER
RESET SLAVE
ALL
如果你使用复制作为一种解决方案使您能够将数据备份在主,和你的数据库的规模不太大,这 mysqldump 可能是合适的工具。See 第17.3.1.1,“支持奴隶使用mysqldump” 对于较大的数据库,在 mysqldump 是不切实际的或低效的,您可以备份原始数据文件。使用原始数据文件选项也意味着你可以备份二进制和中继日志,会使你在从失败的事件重现的奴隶。有关更多信息,参见 第17.3.1.2,“备份原始数据从一个奴隶”
停止从加工要求。你可以完全停止复制使用的奴隶 mysqladmin : shell>
mysqladmin stop-slave或者,你可以停下来只从SQL线程暂停活动执行: shell>
mysql -e 'STOP SLAVE SQL_THREAD;'这使奴隶继续接收数据更改事件从主人的二进制日志存放在中继日志使用I/O线程,但防止奴隶执行这些事件和变化的数据。在忙碌的复制环境,允许I/O线程运行备份时可以加快追赶的过程当你重新启动SQL线程的奴隶。 运行 mysqldump 把你的数据库。你可以把数据库或数据库被选择。例如,把所有的数据库: shell>
mysqldump --all-databases > fulldb.dump当垃圾已经完成,开始从业务: shell>
mysqladmin start-slave
InnoDB
关闭从MySQL服务器: shell>
mysqladmin shutdown复制数据文件。你可以使用任何合适的复制或档案事业,包括 内容提供商 , 焦油 或 WinZip 。例如,假设数据目录位于当前目录下,你可以存档的整个目录如下: shell>
tar cf /tmp/dbbackup.tar ./data再次启动MySQL服务器。UNIX下: shell>
mysqld_safe &在Windows: C:\>
"C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld"
relay-log.infoCHANGE MASTER
TOMASTER_LOG_POS
LOAD DATA
INFILELOAD DATA
INFILE--slave-load-tmpdirtmpdir
read_only
使服务器的只读,因此它只能处理检索和街区更新。 执行备份 更改服务器恢复正常的读/写状态。
主服务器M1 一个从服务器,S1,M1作为它的主人 客户端连接到M1 C1 客户端连接到S1 C2
read_only
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
所发的C1 M1更新请求将块因为服务器在只读模式。 查询结果发送C1 M1请求将成功。 对M1进行备份是安全的。 S1进行备份是不安全的。该服务器仍在运行,可以处理的二进制日志或更新请求来自客户端的C2。
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
主M1将继续运作,因此在主备份是不安全的。 从S1停止,因此从S1备份是安全的。
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
InnoDB
relay_log_info_repositorymaster_info_repositorymysql.slave_master_infoFILE
应用事务对数据库 在复制的位置更新 mysql.slave_relay_log_info表 更新在mysql.gtid_executed表gtid(当GTIDs被启用和二进制日志服务器上禁用)。
mysql.slave_relay_log_info
relay_log_recovery
当使用gtids和 MASTER_AUTO_POSITION,集 relay_log_recovery=1。与此配置设置 relay_log_info_repository和其他变量不影响恢复。注意要保证恢复, sync_binlog=1(这是默认的)也必须建立在奴隶,让奴隶的二进制日志同步到磁盘每次写。否则,提交的事务可能不是奴隶的二进制日志本。 基于复制文件位置时,集 relay_log_recovery=1和 relay_log_info_repository=TABLE笔记 复苏的中继日志中丢失。
| |||||||
|---|---|---|---|---|---|---|---|
当使用gtids和 MASTER_AUTO_POSITION,集 relay_log_recovery=1。与此配置设置 relay_log_info_repository和其他变量不影响恢复。 基于复制文件位置时,集 relay_log_recovery=1, sync_relay_log=1,和 relay_log_info_repository=TABLE笔记 复苏的中继日志中丢失。
sync_relay_log=1sync_relay_log=1relay_log_recovery=0
relay_log_recovery=1
events_stages_current
使3表现图式阶段发行: mysql>
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'->WHERE NAME LIKE 'stage/sql/Applying batch of row changes%';等待某一事件被复制应用线程处理然后检查进展的展望 events_stages_current表例如获得进展 更新 事件的问题: mysql>
SELECT WORK_COMPLETED, WORK_ESTIMATED FROM performance_schema.events_stages_current->WHERE EVENT_NAME LIKE 'stage/sql/Applying batch of row changes (update)'如果 binlog_rows_query_log_events启用,查询有关的信息存储在二进制日志和暴露在 processlist_info 场。看到触发此事件的原始查询: mysql>
SELECT db, processlist_state, processlist_info FROM performance_schema.threads->WHERE processlist_state LIKE 'stage/sql/Applying batch of row changes%' AND thread_id = N;
default_storage_engine
InnoDBArchive
如果你使用 mysqldump 创建你的数据库快照,您可以编辑转储文件文本更改用于每台发动机的类型。 另一个选择 mysqldump 是禁用您不想使用奴隶在使用转储建立数据从发动机类型。例如,你可以添加 --skip-federated选择你的奴隶禁用 联邦 引擎如果一个特定的引擎不一表被创造的存在,MySQL将使用默认的发动机类型,通常 MyISAM。(这需要, NO_ENGINE_SUBSTITUTIONSQL模式不启用。)如果你想禁用额外的引擎,这样,你可能要考虑建立一个特殊的二进制用于只支持你想要的引擎的奴隶。 如果您使用的是原始数据文件(二进制备份)建立的奴隶,你将无法改变最初的表格式。相反,使用 ALTER TABLE更改表的类型后,奴隶已经开始。 新的主从复制设置,目前在主没有桌子,避免指定的发动机类型创建新表时。
停止从运行复制更新: mysql>
STOP SLAVE;这将使你能够改变发动机类型不中断。 执行一个 ALTER TABLE ... ENGINE='engine_type'每个表被改变 又开始从复制过程: mysql>
START SLAVE;
default_storage_engineCREATE
TABLEALTER TABLE
MySQL的> ALTER TABLE csvtable Engine='MyISAM';
MyISAMdefault_storage_engine
MySQL的> CREATE TABLE tablea (columna int) Engine=MyISAM;
mysql>SET default_storage_engine=MyISAM;mysql>CREATE TABLE tablea (columna int);
default_storage_engineCREATE
TABLE
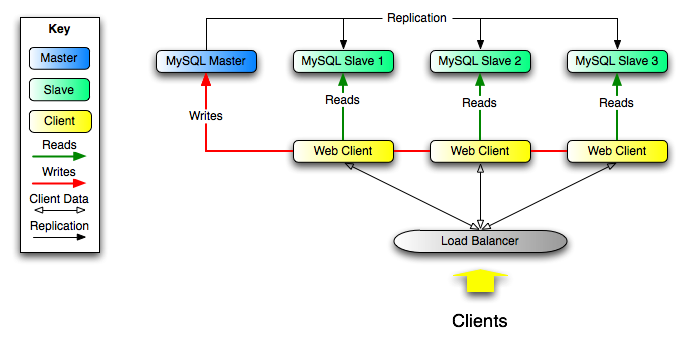
safe_writer_connect()safe_reader_connect()safe_reader_statement()safe_writer_statement()
safe_
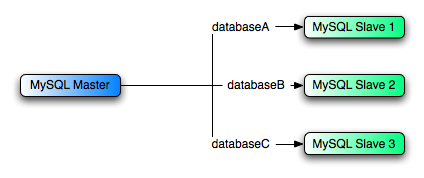
--replicate-wild-do-table
--replicate-do-db
--replicate-do-db
START SLAVE
复制从1应该使用 --replicate-wild-do-table=databaseA.%2应使用复制的奴隶 --replicate-wild-do-table=databaseB.%复制从三应该使用 --replicate-wild-do-table=databaseC.%
--replicate-wild-do-table
同步所有数据到每个奴隶,并删除数据库,表,或是你不想继续。 使用 mysqldump 为每个数据库创建一个单独的转储文件并加载适当的转储文件在每个奴隶。 使用原始数据文件转储和只包含特定的文件和数据库,你需要为每一个奴隶。 笔记 这不工作 InnoDB除非你使用的数据库 innodb_file_per_table
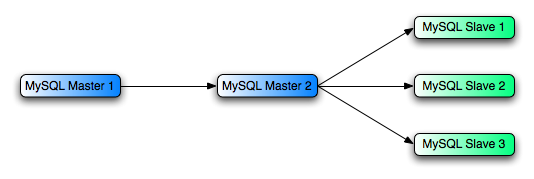
掌握1是主,所有的变化和更新写入数据库。二进制日志是对主人的启用,这是默认的。 主人是奴隶主,提供复制功能的奴隶,其余的在复制结构。掌握2是允许连接到主1唯一的机。2有主 --log-slave-updates启用选项(默认值)。使用此选项,从掌握1复制指令还掌握2的二进制日志,然后将它们复制到真正的奴隶。 从1,2和3的奴隶,奴隶作为奴隶主2,复制信息从主2,这实际上是由升级登录大师1。
如果可能的话,把中继日志和数据文件放在不同的物理驱动器。为此,使用 --relay-log选项来指定中继日志的位置。 如果重磁盘I/O活动读取二进制日志文件和中继日志文件是一个问题,考虑增加的价值 rpl_read_size系统变量。本系统变量控制从日志文件中读取数据的最低金额,并增加可能减少文件的读取和I / O档当文件数据不被操作系统缓存。注意,这个值的大小的缓冲区分配给每个线程读取二进制日志和中继日志文件,包括转储线程对奴隶主人和协调线程。设置较大的值,因此可能有对于服务器内存消耗的影响。 如果奴隶比主人明显变慢,你可能想将复制数据库不同,不同的奴隶的责任。看到 第17.3.6“复制不同的数据库,不同的奴隶” 如果你的主人利用交易和你不关心的事务支持你的奴隶,使用 MyISAM或在奴隶的另一个非事务性的引擎。看到 本节,“使用复制不同的主从存储引擎” 如果你的奴隶是不作为的主人,和你有一个潜在的解决方案,以确保你可以把故障的事件中的高手,那么你可以关掉 --log-slave-updateson the斯拉夫人。This prevents “ 哑的 “ 奴隶也记录他们执行到自己的二进制日志事件。
CHANGE MASTER TO
--log-bin--skip-log-slave-updates

MySQL MasterWeb Client
Slave 1Slave 3--skip-log-slave-updates--skip-log-slave-updatesSlave 1Slave 1Slave 3
--skip-log-slave-updates--log-slave-updatesSlave 2Slave 1Master
STOP SLAVE
IO_THREADSHOW PROCESSLISTSlave 1STOP SLAVERESET MASTER
Slave 2STOP SLAVECHANGE MASTER TO MASTER_HOST='Slave1''Slave1'CHANGE MASTER
TOSlave 2userpasswordportSlave 1START SLAVESlave 3
Web ClientWeb ClientSlave
1Master
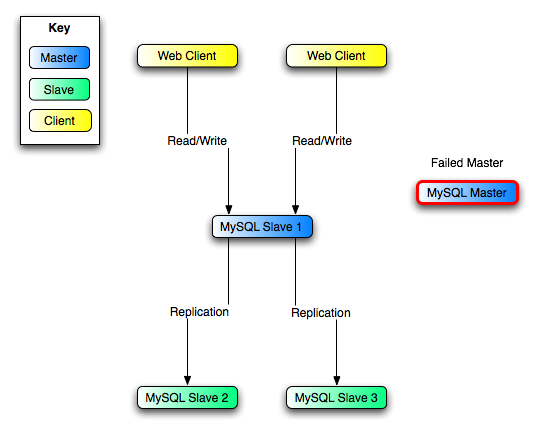
MasterMasterCHANGE
MASTER TOSlave 3S1ave
1
MasterMasterRESET MASTERSlave
1Slave
3Web
Client
bind
[mysqld]
[mysqld] ssl-ca=cacert.pem ssl-cert=server-cert.pem ssl-key=server-key.pem
--ssl-ca:证书的权威证书文件的路径名(CA)。( ——SSL capath 类似但指定目录路径名的CA证书文件。) --ssl-cert:服务器的公钥证书的文件的路径名。这可以被发送到客户端和认证针对的CA证书,具有。 --ssl-key:私钥文件服务器的路径名。
CHANGE MASTER TOmy.cnfCHANGE MASTER
TOCHANGE MASTER TO
名奴隶证书和密钥文件使用一个选项文件,添加以下的线 [client]对奴隶的部分 my.cnf 文件,改变文件的名字是必要的: [client] ssl-ca=cacert.pem ssl-cert=client-cert.pem ssl-key=client-key.pem
重新启动服务器,使用 --skip-slave-start选项来防止从连接到主。使用 CHANGE MASTER TO指定主配置,加 master_ssl 选择连接使用加密: mysql>
CHANGE MASTER TO->MASTER_HOST='master_hostname',->MASTER_USER='repl',->MASTER_PASSWORD='->password',MASTER_SSL=1;设置 MASTER_SSL=1一个复制连接,然后设置没有进一步 master_ssl_ xxx选择对应的设置 --ssl-mode=REQUIRED对于客户端,如 第6.4.2,“加密连接”命令选项 。与 MASTER_SSL=1连接尝试才能成功,如果一个加密的连接可以建立。复制连接不回落到一个加密的连接,所以没有设置相应的 --ssl-mode=PREFERREDSetting for复制。如果 MASTER_SSL=0是集,这相当于 --ssl-mode=DISABLED名奴隶证书和SSL私钥文件使用 CHANGE MASTER TO声明,如果你没有在奴隶的这样做 my.cnf 文件,添加适当的 MASTER_SSL_xxx备选办法: -> MASTER_SSL_CA = 'ca_file_name',-> MASTER_SSL_CAPATH = 'ca_directory_name',-> MASTER_SSL_CERT = 'cert_file_name',-> MASTER_SSL_KEY = 'key_file_name',这些选项对应的 --ssl-xxx具有相同名称的选项,如 第6.4.2,“加密连接”命令选项 。这些选项生效, MASTER_SSL=1还必须设置。一个复制连接,指定的值 _ SSL _交流硕士 或 MASTER_SSL_CAPATH,或指定这些选项在奴隶的 my.cnf 文件,对应设置 --ssl-mode=VERIFY_CA。连接尝试才能成功如果有效匹配的证书颁发机构(CA)证书是使用指定的信息发现。 激活主机名称身份验证、添加 MASTER_SSL_VERIFY_SERVER_CERT选项: -> MASTER_SSL_VERIFY_SERVER_CERT=1,这个选项对应的 --ssl-verify-server-cert选项,这是过时的MySQL 5.7和MySQL 8中删除。一个复制连接,指定 MASTER_SSL_VERIFY_SERVER_CERT=1对应设置 --ssl-mode=VERIFY_IDENTITY,如 第6.4.2,“加密连接”命令选项 。这个选项生效, MASTER_SSL=1还必须设置。主机名的身份验证不使用自签名证书的工作。 激活证书撤销列表(CRL)检查,加 MASTER_SSL_CRL或 master_ssl_crlpath 选项: ->
MASTER_SSL_CRL = 'crl_file_name',->MASTER_SSL_CRLPATH = 'crl_directory_name',这些选项对应的 --ssl-xxx具有相同名称的选项,如 第6.4.2,“加密连接”命令选项 。如果没有指定,没有CRL检查发生。 指定的复制连接允许密码和加密协议的列表,添加 MASTER_SSL_CIPHER和 master_tls_version 备选办法: ->
MASTER_SSL_CIPHER = 'cipher_list',->MASTER_TLS_VERSION = 'protocol_list',这个 MASTER_TLS_VERSION选项指定的加密协议允许的复制连接。格式是这样的 tls_version系统变量与一个或多个协议名称以逗号分隔。这个 硕士_ SSL _ cipher 选项指定的复制连接允许的密码列表,与一个或多个密码名字冒号分隔。协议和密码,你可以使用这些列表取决于用来编译MySQL的SSL库。有关如何指定这些选项,看 第6.4.6,“加密连接协议和密码” 在掌握的信息已经更新,开始从复制过程: mysql>
START SLAVE;你可以使用 SHOW SLAVE STATUS声明确认加密连接建立成功。 加密连接在奴隶的要求并不能保证主需要加密连接的奴隶。如果你想确保主只接受复制的奴隶,连接使用加密连接,创建一个复制的用户帐户在主用 REQUIRE SSL选项,然后让用户 REPLICATION SLAVE特权。例如: MySQL的> CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password'-> REQUIRE SSL;MySQL的> GRANT REPLICATION SLAVE ON *.*-> TO 'repl'@'%.example.com';如果你对主有一个现有的复制的用户帐户,您可以添加 REQUIRE SSL它与本声明: MySQL的> ALTER USER 'repl'@'%.example.com' REQUIRE SSL;
一个奴隶表明无论是半同步时连接到主的能力。 如果半同步复制在主人身边启用并至少有一个半同步的奴隶,一个线程执行一个事务提交的主块和等待至少一个半同步奴隶承认已为交易收到的所有事件,直到发生超时。 奴隶承认交易的事件后,事件被写入中继日志和刷新到磁盘的收据。 如果发生超时不承认任何奴隶交易,主机恢复到异步复制。当至少一个半同步奴隶赶,主人回到半同步复制。 半同步复制必须启用对主站和从站侧。如果半同步复制是在主残疾,或启用主但没有奴隶主使用异步复制。
rpl_semi_sync_master_wait_for_slave_count
START
TRANSACTIONSET autocommit =
0
异步复制,主写事件的二进制日志和奴隶要求他们当他们准备好了。有没有保证,任何事件都有奴隶。 完全同步复制,当主提交一个事务,所有的奴隶都提交了交易前的大师返回会话进行交易。这样做的缺点是,可能会有很多的延迟来完成交易。 半同步复制是异步和同步复制之间。主等待,直到至少一个奴隶已经收到并记录的事件。它不会等待所有的奴隶都承认收据,它只需要收据,不是事件已充分执行和从站侧犯。
rpl_semi_sync_master_wait_for_slave_count
rpl_semi_sync_master_wait_point
AFTER_SYNC(默认):大师写的每一笔交易的二进制日志和奴隶,并同步二进制日志到磁盘。主等待收到确认后同步奴隶交易。在收到确认,主提交事务的存储引擎并返回结果给客户端,然后才能进行。 AFTER_COMMIT:主写每个事务的二进制日志和奴隶,同步二进制日志,并提交事务的存储引擎。主等待交易收据确认提交后的奴隶。在收到确认,主人将结果返回给客户端,然后才能进行。
与 AFTER_SYNC看,所有客户承诺同时交易:在它被承认的奴隶和致力于存储引擎在主。因此,所有的客户看到主人相同的数据。 在主失败的事件,在主所犯下的所有交易都复制到奴隶(保存到其中继日志)。一个崩溃的奴隶主和故障转移是无损因为奴隶是最新的。 与 AFTER_COMMIT,客户发行交易只在服务器向存储引擎和接收从确认得到的返回状态。提交之前,从确认后,客户可以在客户端看到的已提交的事务提交。 如果做错了事情,奴隶不处理事务,然后在主碰撞和故障转移事件的奴隶,这是可能的,这样的客户将看到的损失相对于他们所看到的在主数据。
两个插件实现半同步能力。这是主侧和一个奴隶的一面一个插件。 系统变量控制插件的行为。一些例子: 控制半同步复制是否在主机启用。启用或禁用插件,这个变量设置为1或0,分别。默认值是0(下)。 以毫秒为单位控制多久主机等待一个提交从奴隶确认超时并恢复异步复制前一个值。默认值是10000(10秒)。 类似 rpl_semi_sync_master_enabled,但控制奴隶的插件
全部 rpl_semi_sync_xxx系统变量的描述 第5.1.7,服务器“系统变量” 状态变量使半同步复制的监测。一些例子: 半同步复制的Slave数量。 无论是半同步复制目前运行在主。该值是1如果插件已经启用并提交确认没有发生。如果插件没有启用或主落回异步复制由于提交确认超时是0。 提交数不是由奴隶成功确认。 提交数被Slave确认成功。 无论是半同步复制目前运行的奴隶。这是1插件是否已启用和从I/O线程正在运行,否则为0。
全部 Rpl_semi_sync_xxx状态变量描述 第5.1.9,“服务器状态变量”
INSTALL PLUGIN
mysql 5.5以上必须安装。 安装插件的能力需要支持动态加载MySQL服务器。为了验证这一点,检查的价值 have_dynamic_loading系统变量 对 。二元分布应支持动态加载。 复制必须已经工作,看 17.1节,“复制配置” 不能有多个复制通道配置。半同步复制是默认的复制通道兼容。看到 第17.2.3,“复制通道”
INSTALL PLUGINSET
GLOBALSTOP SLAVESTART SLAVEREPLICATION_SLAVE_ADMINSUPER
plugin_dirplugin_dir
semisync_master.so
INSTALL
PLUGIN
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
libimf
MySQL的> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';错误1126(hy000):不能打开共享库的/usr/local MySQL / lib /插件/ semisync_master。所以(errno:22 libimf.so:不能打开共享对象文件:没有这样的文件或目录)
libimf
SHOW PLUGINSINFORMATION_SCHEMA.PLUGINS
INFORMATION_SCHEMA.PLUGINSSHOW PLUGINS
mysql>SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE '%semi%';+----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +----------------------+---------------+ | rpl_semi_sync_master | ACTIVE | +----------------------+---------------+
SET
GLOBAL
SET GLOBAL rpl_semi_sync_master_enabled = {0|1};
SET GLOBAL rpl_semi_sync_master_timeout = N;
SET GLOBAL rpl_semi_sync_slave_enabled = {0|1};
rpl_semi_sync_master_enabledrpl_semi_sync_slave_enabled
rpl_semi_sync_master_timeoutN
STOP SLAVE IO_THREAD; START SLAVE IO_THREAD;
my.cnf
[mysqld] rpl_semi_sync_master_enabled=1 rpl_semi_sync_master_timeout=1000 # 1 second
[mysqld] rpl_semi_sync_slave_enabled=1
SHOW
VARIABLES
MySQL的> SHOW VARIABLES LIKE 'rpl_semi_sync%';
SHOW STATUS
MySQL的> SHOW STATUS LIKE 'Rpl_semi_sync%';
Rpl_semi_sync_master_statusrpl_semi_sync_master_enabledRpl_semi_sync_master_status
Rpl_semi_sync_master_clients
Rpl_semi_sync_master_yes_txRpl_semi_sync_master_no_tx
Rpl_semi_sync_slave_status
immediate_commit_timestamp
CHANGE MASTER TO MASTER_DELAY=NNNanonymous_gtid_log_event
START SLAVESTOP SLAVERESET
SLAVE
replication_applier_configurationMASTER_DELAYreplication_applier_status
为了防止用户错误的主人。有延迟可以回滚一个延迟时间的奴隶之前的错误。 测试系统的行为的时候,有一个滞后。例如,在应用程序中,一个滞后可能在重负载引起的奴隶。然而,很难产生这种负荷水平。延迟复制可以模拟滞而不必模拟负载。它也可以用来调试一个滞后的奴隶相关的条件。 检查一下数据库看起来像在过去,而不必重新备份。例如,用一个星期的延迟配置的奴隶,如果你需要知道数据库以前的样子值得最后几天的发展,延迟的奴隶可以检查。
original_commit_timestamp:数微秒纪元以来交易时写的(承诺)对原主人的二进制日志。 immediate_commit_timestamp:数微秒纪元以来交易时写的(承诺)的即时掌握二进制日志。
TIMESTAMP
#170404 10:48:05 server id 1 end_log_pos 233 CRC32 0x016ce647 GTID last_committed=0 \ sequence_number=1 original_committed_timestamp=1491299285661130 immediate_commit_timestamp=1491299285843771# original_commit_timestamp=1491299285661130 (2017-04-04 10:48:05.661130 WEST)# immediate_commit_timestamp=1491299285843771 (2017-04-04 10:48:05.843771 WEST) /*!80001 SET @@session.original_commit_timestamp=1491299285661130*//*!*/; SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1'/*!*/;# at 233
original_commit_timestampimmediate_commit_timestampimmediate_commit_timestamp
original_commit_timestampimmediate_commit_timestamp
original_commit_timestamp
Seconds_Behind_Masterimmediate_commit_timestamp
replication_connection_status:连接的当前状态的主人,提供过去和当前事务的连接线程排队进入中继日志。 replication_applier_status_by_coordinator:协调员的线程,只显示信息,使用多线程的奴隶当现状,提供的信息在最后交易缓冲协调线程一个工人的队列,以及交易目前缓冲。 replication_applier_status_by_worker:线程的当前状态(S)将从主接收交易,提供有关通过敷贴线应用的交易信息,或者通过使用多线程时,每个工人的奴隶。
交易的gtid 交易的 original_commit_timestamp和 immediate_commit_timestamp ,从奴隶的中继日志检索 时间线开始处理事务 在最后处理的事务,时间线程处理完它
SHOW SLAVE STATUS
SQL_Delay:一个非负整数表示配置使用的复制延迟 CHANGE MASTER TO MASTER_DELAY=N,以秒为单位 SQL_Remaining_Delay:当 slave_sql_running_state 是 Waiting until MASTER_DELAY seconds after master executed event本字段包含一个整数,表示左边的延迟秒数。在其他时候,这场 无效的 Slave_SQL_Running_State:一个字符串表示的SQL线程的状态(类似于 slave_io_state )。价值是相同的 State值的SQL线程显示 SHOW PROCESSLIST
SHOW
PROCESSLISTWaiting until MASTER_DELAY seconds after
master executed event
17.4.1.1复制和自我维持 17.4.1.2复制和黑洞的表 17.4.1.3复制和字符集 17.4.1.4复制和校验表 17.4.1.5复制创建服务器,修改服务器,并将服务器 17.4.1.6复制创建…如果不存在报表 17.4.1.7复制创建表…SELECT语句 17.4.1.8复制current_user() 17.4.1.9复制不同的表定义在大师和Slave 17.4.1.10复制目录选项 17.4.1.11复制滴…如果存在语句 17.4.1.12复制和浮点值 17.4.1.13复制和冲洗 17.4.1.14复制和系统功能 17.4.1.15复制和秒的小数部分的支持 17.4.1.16复制调用功能 17.4.1.17 JSON文件复制 17.4.1.18 replication和限制 17.4.1.19复制和负载数据的导入导出 17.4.1.20复制和max_allowed_packet 17.4.1.21复制记忆表 17.4.1.22复制MySQL数据库系统 17.4.1.23复制和查询优化器 17.4.1.24复制和分区 17.4.1.25复制和修复表 17.4.1.26复制和保留字 17.4.1.27复制服务器端的帮助表 17.4.1.28复制和主从停工 17.4.1.29奴隶在复制过程中的错误 17.4.1.30复制服务器的SQL模式 17.4.1.31复制与临时表 17.4.1.32复制重试和超时 17.4.1.33复制和时区 17.4.1.34复制和事务一致性 17.4.1.35复制和交易 17.4.1.36复制触发器 17.4.1.37复制TRUNCATETABLE 17.4.1.38复制和用户名长度 17.4.1.39复制和变量 17.4.1.40复制视图
InnoDB
AUTO_INCREMENTLAST_INSERT_ID()TIMESTAMP
一个语句调用触发器或功能更新的原因 AUTO_INCREMENT柱是不可复制的正确使用基于语句的复制。这些陈述是标记为不安全。(错误# 45677) 一个 INSERT为表有一个主键,包括 汽车 列那不是这个组合键的第一列是不是安全的日志记录或复制的声明。这些陈述是标记为不安全。(错误# 11754117,错误# 45670) 这个问题不影响表的使用 InnoDB存储引擎,因为 InnoDB 表一 汽车 柱至少需要一个关键的地方自动递增列是唯一的或最左边的列。 添加一个 AUTO_INCREMENT列一个表 ALTER TABLE不可能产生在奴隶和主人的相同行排序。这是因为在这行编号的顺序取决于特定的存储引擎用于表和订单中的行插入。如果是对主人和奴隶的重要次序,行粘贴前必须在指定 汽车 数。假设你想要添加一个 AUTO_INCREMENT列一个表 T1 有柱 col1和 COL2 ,下面的语句产生一个新的表 t2相同 T1 但是有一个 AUTO_INCREMENT专栏 创建表T2像T1 T2;修改表添加ID int auto_increment主键;插入T2 SELECT * FROM T1的col1,col2; 重要 为了保证对主人和奴隶一样的排序, ORDER BY条款必须命名 全部 柱 t1给的指令是受限制的 CREATE TABLE ... LIKE:外键定义被忽略,因为是 数据目录 和 INDEX DIRECTORY表选项。如果一个表的定义包括任何的这些特点,创造 T2 使用 CREATE TABLE声明是一个用于创建相同 T1 ,但增加了 AUTO_INCREMENT专栏 无论方法用来创建和填充的内容有 AUTO_INCREMENT柱,最后一步是把原来的表,然后重命名该副本: 降T1;表重命名T1 T2;
BLACKHOLE
BLACKHOLEbinlog_formatROW
如果主人有一个字符集不同于全局数据库 character_set_server价值,你应该设计你的 CREATE TABLE语句使他们不隐式依赖于数据库的默认字符集。一个好的解决方法是国家字符集和整理,明确 CREATE TABLE声明.
CREATE SERVERALTER SERVERDROP SERVER
CREATE ... IF
NOT EXISTS
每一个 CREATE DATABASE IF NOT EXISTS声明是复制的,是否已经存在在主数据库。 同样,每一个 CREATE TABLE IF NOT EXISTS声明没有 SELECT是复制的,表是否在主已经存在。这包括 CREATE TABLE IF NOT EXISTS ... LIKE。复制 CREATE TABLE IF NOT EXISTS ... SELECT遵循的规则有所不同;看 第17.4.1.7,“复制创建表…选择“报表” 为更多的信息 CREATE EVENT IF NOT EXISTS总是复制,事件是否命名上的声明中已经存在的主。
CREATE
TABLE ... SELECT
如果目标表不存在,记录发生如下。不管 IF NOT EXISTS是存在的 STATEMENT或 混合的 格式:表记录为书面 ROW格式:声明将作为 CREATE TABLE声明,然后通过一系列的插入行事件。
如果 CREATE TABLE ... SELECT语句失败,记录什么。这包括的情况下,目标表存在 如果不存在 不给 如果目标表存在 IF NOT EXISTS给出了MySQL 8忽略声明完全没有插入或记录。
CREATE
TABLE ... SELECTCREATE TABLECREATE
TABLE ... SELECT
CURRENT_USER()
CURRENT_USER()CURRENT_USER
列常见的表的两个版本必须定义在相同的顺序在主人与奴隶。 (即使两个表的列数相同,这是真的) 列常见的表的两个版本必须在任何额外的列定义。 这意味着执行 ALTER TABLE在一个新的柱插入表内的列常见的范围表导致复制失败的奴隶的声明,如下面的示例所示: 假设一个表 t,在主人与奴隶的存在,是由以下定义 CREATE TABLE声明: 创建表(C1 C2 C3 int,int,int); 假设 ALTER TABLE声明所示是奴隶执行: 修改表添加列在C3 cnew1 int; 以前的 ALTER TABLE允许在奴隶因为列 C1 , c2,和 C3 这是两个版本的常见表 t保持集中在表的两个版本,之前的任何列不同。 然而,以下 ALTER TABLE语句不能执行的奴隶而不引起复制打破: 修改表添加列在C2 cnew2 int; 复制的奴隶执行失败后 ALTER TABLE声明显示,因为新的列 cnew2 是柱间共同的版本 t每个 “ 额外 “ 在桌子上有多个列的版本列必须有一个默认值。 列的默认值是由许多因素决定,包括它的类型,它是否有一个 DEFAULT选择,无论是声明为 无效的 ,和服务器的SQL模式的影响在其创作时间;有关更多信息,参见 11.7节,“数据类型的默认值” )
master>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT);
master>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);slave>CREATE TABLE t1 (c2 INT, c1 INT);
master>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT);
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c2 INT, c1 INT, c3 INT);
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);
c2
硕士 CREATE TABLE t1 (c1 INT, c2 BIGINT);奴隶 CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
CHAR(10)CHAR(10)
TINYINTTINYINTTINYINT
slave_type_conversions
所有_ lossy 在这种模式中,类型转换意味着信息的丢失是允许的。 这并不意味着非有损转换是允许的,仅仅只有案件需要有损转换或没有在所有的转换都是允许的;例如,使 只有 这种模式允许 INT柱被转换为 TINYINT (一种有损转换),但不是一个 TINYINT列一个 国际的 柱(无损耗)。在后者的转换在这种情况下会导致复制停止错误的奴隶。 所有非lossy _ _ 这种模式允许转换不需要源值截断或其他特殊处理;即,它允许转换的目标类型具有比源类型广泛。 设置该模式是否有损转换是不允许轴承;这是可控的 ALL_LOSSY模式。只要 所有非lossy _ _ 是集,但不 ALL_LOSSY,然后尝试转换会导致数据丢失(如 国际的 到 TINYINT,或 char(25) 到 VARCHAR(20))使奴隶停止错误 所有_ lossy,所有非lossy _ _ 在该模式下,所有支持的类型转换是允许的,无论是否有损转换。 all_signed 对提升整数类型的值(默认行为)签署。 all_unsigned 对提升整数类型为无符号值。 all_signed,all_unsigned 对提升整数类型签署,如果可能的话,否则为无符号。 【 空的 ] 什么时候 slave_type_conversions没有设定,没有属性升级或降级是允许的;这意味着在源和目标表的所有列必须是同一类型。 这种模式是默认的
ALL_SIGNEDALL_SIGNEDALL_SIGNEDALL_LOSSY
slave_type_conversions
任何整数类型之间 TINYINT, SMALLINT, MEDIUMINT, INT,和 BIGINT这包括在签署这些类型unsigned版本转换。 有损转换是通过截断源值最大(或最小)制成的目标列允许。为确保无损转换,从符号到符号类型、目标列必须足够大以容纳源列中的值的范围。例如,你可以降级 TINYINT UNSIGNED非有损于 smallint ,但不 TINYINT任何十进制类型之间 DECIMAL, FLOAT, DOUBLE,和 NUMERICFLOAT到 双 是一种无损转换; DOUBLE到 浮 只能处理有损。从转换 DECIMAL(M,D)到 (小数点 M', D') 哪里 D'>=D和 ( M'— D') >= (M— D)是非有损;任何情况下 M'<M, D'<D,或两者兼而有之,不仅有损转换可。 任何的十进制类型,如果要存储不适合目标类型的值,该值是根据圆形向下舍入规则文档中的其他服务器定义。看到 第12.23.4,“舍入行为” ,有关这是十进制类型。 任何字符串类型之间 CHAR, VARCHAR,和 TEXT之间的转换,包括不同的宽度。 转化的研究 CHAR, varchar ,或 TEXT一个 烧焦 , VARCHAR,或 文本 柱大小相同或更大的不失真。有损转换是通过插入只有前处理 N对奴隶的字符串中的字符,在 N是目标列的宽度 重要 使用不同的字符集的列之间的复制是不支持的。 任意二进制数据类型之间的 BINARY, VARBINARY,和 BLOB之间的转换,包括不同的宽度。 转化的研究 BINARY, varbinary ,或 BLOB一个 二元的 , VARBINARY,或 斑点 柱大小相同或更大的不失真。有损转换是通过插入只有前处理 N对奴隶的字符串的字节,其中 N是目标列的宽度 之间的任何2 BIT任何两尺寸柱 当插入一个值从 BIT(M)列为 位( M') 列,其中 M'> M,在最重要的位 位( M') 列被清除(设置为0)和 M位的 位( M) 价值设定的最低有效位 位( M') 专栏 当插入一个值从源 BIT(M)列为目标 位( M') 列,其中 M'<M最大值的最大值 位( M') 为列分配;换句话说,一个 “ 所有的设置 “ 值赋给目标列
DATA DIRECTORYCREATE TABLENO_DIR_IN_CREATEINDEX
DIRECTORYCREATE TABLE
DROP DATABASE
IF EXISTSDROP TABLE IF
EXISTSDROP VIEW IF
EXISTS
DROP ... IF EXISTS
FLUSHFLUSH LOGSFLUSH TABLES WITH READ LOCKFLUSH TABLESANALYZE TABLEOPTIMIZE TABLEREPAIR TABLE
mysqlGRANTFLUSH PRIVILEGESFLUSH TABLESMERGEFLUSH TABLESLOCAL
这个 USER(), CURRENT_USER()(或 CURRENT_USER), UUID(), VERSION(),和 LOAD_FILE()功能是复制不改变因此不能可靠地工作在奴隶除非基于行的复制启用。(见 17.2.1,“复制格式” 。) USER()和 CURRENT_USER()自动复制使用时,使用基于行的复制 混合的 模式,并生成一个警告 STATEMENT模式。(参见 第17.4.1.8,“current_user()”复制 This is also true for VERSION()和 RAND()为 NOW()二进制日志包含时间戳。这意味着价值 返回的调用这个函数在主 复制到奴隶。为了避免意外的结果复制时在MySQL服务器在不同的时区,设置时区对主人和奴隶。参见 第17.4.1.33,“复制和时区” 说明潜在的问题复制时,在不同的时区服务器之间,假设主位于纽约,从位于斯德哥尔摩和服务器使用本地时间。进一步假设,在主,你创建一个表 mytable,执行 INSERT在这个表的语句,然后选择从表,如下所示: MySQL的> CREATE TABLE mytable (mycol TEXT);查询行,0行受影响(0.06秒)MySQL > INSERT INTO mytable VALUES ( NOW() );查询行,1行的影响(0秒)MySQL > SELECT * FROM mytable;| mycol |,意图,意图| 2009年09月01 | 12:00:00,意图在1行集(0秒) 斯德哥尔摩当地时间比纽约晚6小时;所以,如果你的问题 SELECT NOW()在同一瞬间的奴隶,价值 2009-09-01 18:00:00 返回。因此,如果从奴隶的副本选择你 mytable后 CREATE TABLE和 INSERT报表只显示已复制,你可能期望 论文 包含的价值 2009-09-01 18:00:00。然而,这是没有的情况下;当你选择从奴隶的份 空白表 ,你得到完全相同的结果作为主人: mysql>
SELECT * FROM mytable;+---------------------+ | mycol | +---------------------+ | 2009-09-01 12:00:00 | +---------------------+ 1 row in set (0.00 sec)不像 NOW(),的 SYSDATE()功能的复制是不安全的因为它是不受影响 设置时间戳 如果报表基于测井中使用的二进制日志报表和不确定性。这不是一个问题,如果使用基于行的日志。 一种选择是使用 --sysdate-is-now选择的原因 SYSDATE()是一个别名 NOW()。这必须是在主人与奴隶的正确工作做。在这种情况下,警告仍通过此功能发布,但可以安全地忽略只要 --sysdate-is-now是用在主人与奴隶 SYSDATE()自动复制使用时,使用基于行的复制 混合的 模式,并生成一个警告 STATEMENT模式 以下限制适用于基于语句的复制,而不是基于行的复制。 这个 GET_LOCK(), RELEASE_LOCK(), IS_FREE_LOCK(),和 IS_USED_LOCK()处理用户级锁的复制没有奴隶了解并发上下文在主函数。因此,这些功能不应该被用来插入主表因为奴隶的内容也会有所不同。例如,不发表声明,如 插入表值(get_lock(…)) 这些功能是自动复制使用行时,使用基于复制 MIXED模式,并生成一个警告 声明 模式
INSERTUUID()
插入T值(uuid());
SET @my_uuid = UUID(); INSERT INTO t VALUES(@my_uuid);
@my_uuidINSERTINSERT
SET @my_uuid1 = UUID(); @my_uuid2 = UUID(); INSERT INTO t VALUES(@my_uuid1),(@my_uuid2);
INSERT INTO t2 SELECT UUID(), * FROM t1;
RAND()
FOUND_ROWS()ROW_COUNT()INSERT
SELECT SQL_CALC_FOUND_ROWS FROM mytable LIMIT 1; INSERT INTO mytable VALUES( FOUND_ROWS() );
mytableSELECT
... INTO
从表1 sql_calc_found_rows选择限制为“found_rows;插入表值(@ found_rows);
MIXED
TIMEDATETIMETIMESTAMP
CREATE TABLEfspfsp
该功能的作用是复制 下面的陈述是基于语句的复制复制使用: 然而,这 功效 特色创建,修改,或删除使用这些语句复制使用基于行的复制。 笔记 试图复制调用功能使用基于语句的复制产生的警告 声明是不安全的登录表格式 。例如,试图用以复制生成此警告因为它目前无法通过MySQL服务器是否是确定性的决定声明UDF复制一个UDF。如果你是绝对肯定的是,调用功能的影响是决定性的,你可以安全地忽略这些警告。 在的情况下 CREATE EVENT和 ALTER EVENT: 事件的状态设置为 SLAVESIDE_DISABLED在奴隶无论国家指定的(这不适用于 DROP EVENT) 总体上该事件是确定对奴隶的服务器ID。 ORIGINATOR柱 INFORMATION_SCHEMA.EVENTS和 鼻祖 柱 mysql.event此信息存储。看到 24.8节,“information_schema事件表” ,和 第13.7.6.18,“显示事件的语法” 为更多的信息
该功能的实现,居住在再生状态的奴隶,如果主失败,奴隶可以作为无主事件处理损失。
INFORMATION_SCHEMA.EVENTS
SELECT EVENT_SCHEMA, EVENT_NAME FROM INFORMATION_SCHEMA.EVENTS WHERE STATUS = 'SLAVESIDE_DISABLED';
SHOW
EVENTS
SHOW EVENTS WHERE STATUS = 'SLAVESIDE_DISABLED';
ALTER EVENT
event_name ENABLEevent_name
master_idEVENTS
SELECT EVENT_SCHEMA, EVENT_NAME, ORIGINATOR
FROM INFORMATION_SCHEMA.EVENTS
WHERE STATUS = 'SLAVESIDE_DISABLED'
AND ORIGINATOR = 'master_id'
ORIGINATORSHOW EVENTS
SHOW EVENTS WHERE STATUS = 'SLAVESIDE_DISABLED' AND ORIGINATOR = 'master_id'
SET GLOBAL event_scheduler =
OFF;ALTER
EVENTSET GLOBAL event_scheduler = ON;
ALTER EVENTSELECTALTER EVENT
EVENTS
SELECT CONCAT(EVENT_SCHEMA, '.', EVENT_NAME) AS 'Db.Event' FROM INFORMATION_SCHEMA.EVENTS WHERE INSTR(EVENT_NAME, 'replicated_') = 1;
binlog_row_value_options=PARTIAL_JSON
binlog_row_value_options
LIMITDELETEUPDATEINSERT ...
SELECT
当使用 STATEMENT模式,一个警告,声明是不安全的基于语句的复制已发布。 当使用 STATEMENT模式,是DML语句包含发出警告 极限 即使他们也有一个 ORDER BY条款(因此是确定的)。这是一个已知的问题。(错误# 42851) 当使用 MIXED模式,现在语句自动复制使用基于行的模式。
LOAD DATA
INFILEbinlog_format=MIXEDbinlog_format=STATEMENTLOAD DATA
INFILE
LOAD DATA
INFILELOAD DATA
INFILE
max_allowed_packetTEXTBLOBmax_allowed_packetmax_allowed_packet
max_allowed_packet
slave_parallel_workers > 0slave_pending_jobs_size_maxmax_allowed_packetslave_pending_jobs_size_maxmax_allowed_packetmax_allowed_packetmax_allowed_packetmax_allowed_packet
slave_max_allowed_packetslave_pending_jobs_size_max
slave_pending_jobs_size_maxslave_pending_jobs_size_maxslave_pending_jobs_size_max
MEMORYMEMORYDELETE
MEMORY
行格式更新和删除从主接受可能会失败 Can't find record in 'memory_table'这样的语句 INSERT INTO ... SELECT FROMmemory_table可以插入不同的行集的主人和奴隶。
MEMORYMEMORY
binlog_format=ROWslave_exec_mode=IDEMPOTENTMEMORYMEMORYMEMORYslave_exec_mode=IDEMPOTENTMEMORY
MEMORYmax_heap_table_sizemax_heap_table_sizeALTER TABLE
... ENGINE = MEMORYTRUNCATE
TABLEMEMORYmax_heap_table_size
MEMORY
mysqlbinlog_formatGRANTREVOKE
DELETEUPDATEORDER BY
ALTER
TABLE ... DROP PARTITION
REPAIR TABLEREPAIR TABLEREPAIR TABLE
rank
--replicate-do-db--replicate-do-table--replicate-ignore-db--replicate-ignore-table
使用一个或多个 ALTER TABLE陈述大师改名字任何数据库对象,这些名称是保留字的奴隶,和改变任何使用旧名称,而不是使用新名称的SQL语句。 在任何SQL语句中使用这些数据库对象的名字,写的名字引用标识符使用那些字符( `)
mysqlHELP
fill_help_tables.sqlshare/mysql
root
通过运行你的服务器升级 mysql_upgrade 第一个奴隶,然后在主。这是第一次升级奴隶的一般原理。 决定是否要复制表的内容,从帮助主人的奴隶。如果没有,加载内容的掌握和每个从单独。否则,检查并解决任何不兼容的帮助表结构之间的主人和奴隶,然后加载内容为主,让它复制到奴隶。 关于这两种加载方法帮助表格内容详细如下。
加载帮助表内容没有复制的奴隶
fill_help_tables.sql
mysql mysql < fill_help_tables.sql
与复制到奴隶加载帮助表格内容
urlhelp_topicTEXT
SELECT TABLE_NAME, COLUMN_NAME, COLUMN_TYPEFROM INFORMATION_SCHEMA.COLUMNSWHERE TABLE_SCHEMA = 'mysql'AND COLUMN_NAME = 'url';
+---------------+-------------+-------------+ | TABLE_NAME | COLUMN_NAME | COLUMN_TYPE | +---------------+-------------+-------------+ | help_category | url | char(128) | | help_topic | url | char(128) | +---------------+-------------+-------------+
+---------------+-------------+-------------+ | TABLE_NAME | COLUMN_NAME | COLUMN_TYPE | +---------------+-------------+-------------+ | help_category | url | text | | help_topic | url | text | +---------------+-------------+-------------+
mysql mysql < fill_help_tables.sql
如果你决定不复制内容毕竟升级主和奴隶单独使用 MySQL 与 --init-command选项,如前所述 如果你决定让表结构兼容,升级,旧服务器的表结构。假设你的主服务器有旧表结构。升级表手动执行这些语句的新结构(二进制日志是残疾人来防止对已经有新结构的奴隶,改变复制): SET sql_log_bin=0; ALTER TABLE mysql.help_category ALTER COLUMN url TEXT; ALTER TABLE mysql.help_topic ALTER COLUMN url TEXT;
然后运行这个命令在主: mysql mysql < fill_help_tables.sql
表格内容加载到主,然后复制到奴隶。
CHANGE MASTER TOslave_net_timeoutslave_net_timeout
sync_binlog=1InnoDBinnodb_flush_log_at_trx_commit=1
进行交易,从提交和更新 relay-log.info。如果出现大跌,这两个操作之间,中继日志处理将继续比信息文件指示和奴隶将重新执行的事件在中继日志的最后交易后已重新启动,进一步。 如果从更新可以发生类似的问题 relay-log.info但是服务器主机崩溃之前写的已经刷新到磁盘。为了减少这种发生的几率,集 sync_relay_log_info=1在奴隶 my.cnf 文件设置 sync_relay_log_info0的原因没有写被迫磁盘和服务器依赖于操作系统将文件时间。
SHOW SLAVE STATUSSTART
SLAVE
--slave-skip-errors
MyISAM
MyISAMINSERTUPDATEMyISAM
INSERT
binlog_formatMIXED
binlog_format
问题 STOP SLAVE SQL_THREAD声明 使用 SHOW STATUS检查的价值 Slave_open_temp_tables变量 如果值不是0,重新从SQL线程 START SLAVE SQL_THREAD重复该过程后 当该值为0,问题 关闭 命令停止奴隶
--replicate-do-db--replicate-do-table--replicate-wild-do-table--replicate-ignore-table--replicate-wild-ignore-table
--replicate-wild-ignore-tablenorepmytable--replicate-wild-ignore-table=norep%
slave_transaction_retriesInnoDBinnodb_lock_wait_timeoutNDBTransactionInactiveTimeoutslave_transaction_retriesSHOW STATUS
NOW()FROM_UNIXTIME()--timezone=timezone_nameTZ
应用交易的一半 。一个事务更新非事务表应用了一些但不是所有的变化。 空白 。间隙是交易尚未(完全)的应用,尽管后来的一些交易已经应用。缺口只能使用多线程时出现的奴隶。避免断裂发生,集 slave_preserve_commit_order=1,这就要求 slave_parallel_type=LOGICAL_CLOCK,和二进制日志(的 log_bin系统变量)和奴隶的更新日志( --log-slave-updates)也启用 无隙低水印的位置 。即使在空白的情况下,它是可能的,交易后 Exec_master_log_pos已应用。那就是,所有的交易点上 N 已被应用,没有交易后 N已应用,但 exec_master_log_pos 有一个值小于 N.这只会发生在多线程的奴隶。有可能 slave_preserve_commit_order做 不 防止无间隙低水印位置。
而从线程正在运行,有可能是一半的交易。 mysqld 关闭。无论是洁净的和不洁净的关机中止正在进行的交易和可能留下的空白和一半的交易。 KILL复制线程(SQL线程使用单线程的奴隶,当使用多线程的奴隶当协调者线程)。这正在进行的交易可能中止留下缝隙,应用交易的一半。 在应用线程错误。这可能会留下空白。如果错误是在混合交易,交易是一半的应用。使用多线程的奴隶时,并没有收到一个错误完成队列的工人,所以它可能需要一段时间停止所有线程。 STOP SLAVE使用多线程的奴隶时。发行后的 STOP SLAVE、奴隶等任何空白需要填补,然后更新 exec_master_log_pos 。这将确保它不会留下空白或无间隙低水印位置,除非上述情况适用(换句话说,前 STOP SLAVE完成的,任何一个错误发生,或者另一个线程的问题 KILL,或重新启动服务器。在这些情况下, STOP SLAVE成功返回。) 如果在中继日志最后交易只有一半接受和多线程从协调员已经开始计划交易的一个工人,然后 STOP SLAVE该交易将获得最多等待60秒。这之后超时,协调员放弃和中止交易。如果交易是混合的,它可能是左半完成。 STOP SLAVE使用单线程的奴隶时。如果正在进行的交易只更新事务表,它是回滚, STOP SLAVE立即停止。如果正在进行的交易是混合, STOP SLAVE交易的完成等多达60秒。这之后暂停,中止事务,所以它可能是左半完成。
rpl_stop_slave_timeoutSTOP
SLAVE
从数据库中的状态可能不会在主的存在。 现场 Exec_master_log_pos进入 SHOW SLAVE STATUS只有一个“低水印”。换句话说,交易出现在位置保证承诺,但交易后的位置可能已犯或不。 CHANGE MASTER TO该频道的失败与错误陈述,除非申请人线程正在运行, CHANGE MASTER TO只有一种选择 如果 mysqld 开始 --relay-log-recovery,没有恢复的那个通道完成,并打印警告。 如果 mysqldump 使用 --dump-slave,它不记录存在差距;因此它打印 CHANGE MASTER TO与 relay_log_pos 设置为低水印位置 Exec_master_log_pos应用自另一个服务器后,启动复制线程,后的位置出现交易再复制。注意,如果gtids启用这是无害的(但是,在这种情况下,不建议使用 --dump-slave)
mysql.slave_worker_infoSTART SLAVE
[SQL_THREAD]slave_parallel_workersSTART
SLAVESTART
SLAVESTART SLAVE UNTIL
SQL_AFTER_MTS_GAPSSTART SLAVE
RESET SLAVERESET SLAVE
slave-preserve-commit-orderExec_master_log_posslave-preserve-commit-order
如果在一个交易的初始陈述是非事务性的,它们的二进制日志直接写入。在交易中剩余的语句缓存而不是写入二进制日志提交事务之前。(如果事务被回滚,缓存的语句如果他们让非事务性的变化不能回滚到二进制日志写入。否则,他们将被丢弃。) 对于基于语句的日志,日志语句的非事务性的影响 binlog_direct_non_transactional_updates系统变量。这个变量是当 关闭 (默认),日志只是描述。这个变量是当 ON对于非事务语句立即发生,记录发生在交易的任何地方(不只是初始非事务语句)。其他报表保存在事务缓存和记录事务提交时。 binlog_direct_non_transactional_updates有没有影响行格式或混合格式的二进制日志。
更新或读取临时表 读取一个非事务表和事务隔离级别小于repeatable_read
更新任何表和读取任何临时表 更新非事务表 binlog_direct_non_transactional_updates是关闭的
ROLLBACK
InnoDBBEGINCOMMITBEGIN
MyISAMInnoDBAUTOCOMMIT=1
binlog_formatbinlog_checksum
autocommitBEGINCOMMITROLLBACKMyISAM
AUTO_INCREMENT
INSERTUPDATEDELETEAFTER
对于每个表,触发器,触发器的定义中的所有 .TRG为表文件。然而,如果有相同的触发事件和动作时间的多个触发器,服务器只执行其中一个触发事件发生时。有关 教研组 文件,看 表触发器存储 如果表的触发器添加或降级后下降,服务器将表 .TRG文件改写的文件保留的触发事件和动作时间的组合只有一个触发器;其他人都失去了。
每个触发器,创建一个存储程序在触发包含所有代码。值来使用 NEW和 旧版 可以通过常规的使用参数。如果触发需要从代码的一个结果值,你可以把代码放在存储函数和函数返回值。如果触发需要多个结果值的代码,你可以把代码放在一个存储过程返回的值 OUT参数. 把所有的三明治都放在桌子上。 创建表,调用存储程序只是创造了一个新的触发器。这个触发效果从而为多重触发它取代一样。
TRUNCATE TABLEMIXEDMIXEDInnoDBREAD UNCOMMITTED
TRUNCATE TABLEInnoDB
STATEMENT
MIXED
sql_modeNO_DIR_IN_CREATENO_DIR_IN_CREATE
SET @@sql_mode =
modemodeNO_DIR_IN_CREATE
default_storage_engine
read_onlySET PASSWORD
max_heap_table_sizeINSERTMEMORY
SET max_join_size=1000; INSERT INTO mytable VALUES(@@max_join_size);
SET time_zone=...; INSERT INTO mytable VALUES(CONVERT_TZ(..., ..., @@time_zone));
lower_case_table_nameslower_case_table_names
二进制日志格式的变化。 二进制日志格式可以主要版本间的变化。当我们试图保持向后兼容,这是不可能的。 这也为复制服务器升级意义重大;看 第17.4.3,升级复制设置” 为更多的信息 为更多的信息以复制行,看 17.2.1,“复制格式” incompatibilities SQL。 你不能复制,从一个较新的主人老奴隶使用基于语句的复制如果被复制使用SQL功能可在主而不是奴隶的陈述。 然而,如果主人和奴隶的支持基于复制的行,并且没有数据定义语句被复制依赖于SQL功能找到主人而不是奴隶,你可以使用基于行的复制复制数据修改语句的影响即使在掌握DDL运行不支持在奴隶。
STRICT_TRANS_TABLESSTRICT_ALL_TABLESbinlog_format=STATEMENTbinlog_format=ROW
utf8mb4my.cnf
[mysqld]character_set_server=latin1collation_server=latin1_swedish_ci
停止所有的奴隶和升级。重新启动他们的 --skip-slave-start选择让他们不连接到主。执行任何表修复或重建需要重新创建数据库对象的操作,如使用 修表 或 ALTER TABLE,或倾销和重装表或触发器。 禁用二进制日志的主人。不用重新启动主、执行 SET sql_log_bin = 0声明。另外,停止并重新启动它的主人 --skip-log-bin选项如果你重启的主人,你也要允许客户端连接。例如,如果所有的客户端连接使用TCP / IP,使用 --skip-networking当你恢复了硕士学位的时候。 与二进制日志禁用,执行任何表修复或重建需要重新创建数据库对象的操作。二进制日志必须被禁止在这一步防止这些操作被记录并发送到奴隶后。 重新启用在掌握二进制日志。如果你设置 sql_log_bin到0年初,执行 SET sql_log_bin = 1声明。如果你的主人禁用二进制日志重启,重启无 --skip-log-bin,无 --skip-networking这样客户和奴隶可以连接。 重新启动的奴隶,这一次没有 --skip-slave-start选项
gtid_mode=ON
gtid_mode=ON
确认主人发出启用二进制日志 SHOW MASTER STATUS声明。二进制日志是默认启用。如果启用了二进制日志, 位置 不为零。如果没有启用二进制日志,确认没有任何设置,禁用二进制日志记录的大师,如 --skip-log-bin选项 验证:主人和奴隶都开始与 --server-id选择,ID值是唯一的每个服务器上的。 验证从运行。使用 SHOW SLAVE STATUS检查是否 slave_io_running 和 Slave_SQL_Running值都是 是 。如果不是,验证用于启动从服务器时,选择。例如, --skip-slave-start防止从线程从开始直到你的问题 START SLAVE声明 如果从运行,检查是否建立了一个连接到主。使用 SHOW PROCESSLIST,发现I/O和SQL线程和检查 状态 看看他们显示列。看到 第17.2.2,“复制的实施细则》 。如果I/O线程状态说 Connecting to master下面,检查: 验证用户用于在主复制的特权。 检查主的主机名是正确的,你使用了正确的端口连接到主。用于复制的端口是用于客户端的网络通信相同(默认是 3306)。为主机名,确保名称解析为正确的IP地址。 检查网络上没有主从残疾人。寻找 skip-networking在配置文件选项。如果存在,评论它或删除它。 如果主人有防火墙或IP过滤配置,确保网络端口用于MySQL不被过滤。 检查可以通过使用达到掌握 ping或 traceroute / tracert到达主机
如果从运行以前,但已经停止,原因通常是一些声明,成功在主对奴隶失败。这不应该如果你已经掌握一个适当的快照发生,不修改数据的线程以外的奴隶的奴隶。如果从意外停止,这是一个错误,或者你遇到了一个已知的复制缺陷描述 17.4.1节,“复制的特点和问题” 。如果这是一个错误,看 第17.4.5,“如何报告复制错误或问题” ,说明如何报告 如果一个语句,成功在主拒绝运行在奴隶,尝试以下步骤如果通过删除从数据库和复制一个新的快照从主做一个完整的数据库同步是不可行的: 确定是否受影响的表的奴隶并不同于主表。试着去理解这一切是怎么发生的。然后让奴隶的表主人相同的运行 START SLAVE如果前面的步骤不工作或不适用,试着了解它是否会使手动更新安全(如果需要)然后忽略下一语句从主。 如果你认为奴隶可以跳过下面的语句从主,发出以下声明: mysql>
SET GLOBAL sql_slave_skip_counter =mysql>N;START SLAVE;价值 N应该是1,如果从主的下一个语句不使用 汽车 或 LAST_INSERT_ID()。否则,该值应该是2。使用报表,请使用2值的原因 汽车 或 LAST_INSERT_ID()他们认为在大师的二进制日志事件。 如果你确信奴隶开始了与主完全同步,并且没有一个更新了涉及从线程以外的表,然后大概的差异是一个错误的结果。如果您运行的是MySQL的最新版本,请报告问题。如果您运行的是旧版本,要升级到最新的确定问题是否存在产能释放。
确认没有用户错误的参与。例如,如果你更新的奴隶的奴隶的线程以外,数据超出同步,你可以在更新有独特的重点违法行为。在这种情况下,从属线程停止并等待你去清理表手动使其同步性。 这不是一个复制的问题。这是一个外界干扰导致复制失败的问题。 确保奴隶与二进制日志记录的功能( log_bin系统变量),并与 --log-slave-updates启用选项,使奴隶记录它接收从主到自己的二进制日志的更新。这些设置的默认值。 在重新设置复制状态保存所有的证据。如果我们没有信息或只有粗略的信息,成为我们追查问题困难的或不可能的。你应该收集证据: 所有的二进制日志文件从主 所有的二进制日志文件从 输出 SHOW MASTER STATUS从主的时候,你发现了问题 输出 SHOW SLAVE STATUS在你发现问题的奴隶 错误日志的主人和奴隶
使用 mysqlbinlog 检查二进制日志。以下有助于发现问题的声明。 log_file和 log_pos是的 master_log_file 和 Read_Master_Log_Pos值 SHOW SLAVE STATUS内核> mysqlbinlog --start-position=log_poslog_file| head