15.1引言InnoDB 15.2 InnoDB和酸模式 15.3 InnoDB的多版本 15.4 .无辜的建筑 15.5 InnoDB锁和事务模型 15.6 InnoDB配置 15.7 InnoDB表空间 15.8 InnoDB表和索引 15.9 InnoDB表和网页压缩 15.10 InnoDB行存储和列格式 15.11 InnoDB的磁盘I/O和文件空间管理 比InnoDB和在线DDL 15.13 InnoDB启动选项和系统变量 15.14 information_schema InnoDB表 15.14.1 InnoDB information_schema表压缩 15.14.2 InnoDB information_schema事务和锁定信息 15.14.3 InnoDB information_schema架构对象表 15.14.4 InnoDB表的架构信息_ fulltext index 15.14.5 InnoDB缓冲池表information_schema 15.14.6 InnoDB information_schema度量表 15.14.7 InnoDB information_schema临时表信息表 15.14.8 InnoDB表空间元数据检索information_schema.files
15.15 InnoDB集成MySQL性能模式 15.16 InnoDB监视器 15.17 InnoDB备份和恢复 15.18 InnoDB和MySQL复制 15 InnoDB Memcached插件 15.20 InnoDB故障排除
InnoDBCREATE
TABLEENGINE=InnoDB
InnoDB的关键优势
它的 DML 操作遵循 酸 模型,用 交易 特色 犯罪 , 回降 ,和 崩溃恢复 为了保护用户数据的能力。看到 15.2节,“InnoDB和酸模式” 更多信息 行级 锁定 和Oracle的风格 一致性读 增加多用户并发性和性能。看到 第15,“InnoDB锁和事务模型” 更多信息 InnoDB表安排磁盘上的数据来优化查询的基础上 主键 。每个 InnoDB表有一个主键索引,称为 聚集索引 组织数据,减少I/O的主键查找。看到 第15.8.2.1,“聚集和二级指标” 更多信息 维护数据 完整性 , InnoDB支持 FOREIGN KEY约束。与国外的钥匙,插入,更新和删除检查,以确保它们不会导致不同的表不一致。看到 第15.8.1.6,“InnoDB和外键约束” 更多信息
InnoDB
InnoDB的增强功能和新功能
InnoDB
这个 InnoDB功能列表 1.4节,“什么是新的MySQL 8” 这个 版本说明
额外的InnoDB的信息和资源
为 InnoDB相关术语和定义,看 MySQL的词汇 一个论坛致力于 InnoDB存储引擎,看 MySQL InnoDB论坛:: InnoDB同样是GNU GPL许可下发布的版本2(月1991)MySQL。在MySQL许可的更多信息,参见 www.mysql.com http:/ / / / / /公司法律事务
InnoDB
如果您的服务器崩溃由于硬件或软件问题,不管当时在数据库中发生了什么,你不需要做任何特殊的后重新启动数据库。 InnoDB崩溃恢复 自动完成,发生撞击的时间之前的任何变化,并不会产生任何变化,在过程中不犯。只是重新启动并继续你离开的地方。 这个 InnoDB存储引擎维护自己 缓冲池 缓存在内存中的表和索引数据为数据访问。常用的数据处理,直接从内存。这种缓存适用于许多类型的信息和加快处理。在专用的数据库服务器,到80的物理内存会被分配至缓冲池。 如果你分手了相关数据的分表,您可以设置 外键 执行 参照完整性 。更新或删除数据,和其他表中的相关数据被更新或删除。尝试将数据插入到一次表没有主表中相应的数据,和坏数据自动被踢出来了。 如果数据是在磁盘或内存中的损坏,一 校验和 机构提醒你伪造的数据之前,你使用它。 当你设计你的数据库和相应的 主键 每个表的列,这些列包含操作自动优化。这是引用的主键列很快 WHERE条款, ORDER BY条款, GROUP BY条款,并 加入 运营 插入,更新,删除,由称为自动机制的优化 变化的缓冲 InnoDB不仅允许并发读写访问相同的表,它缓存更改的数据精简磁盘I / O. 绩效是不限于大表查询时间长。当同一行访问过的从一张桌子,一个功能叫做 自适应哈希索引 在做出这些查找更快,如果他们来到一个哈希表。 你可以压缩表和相关的索引。 您可以创建和删除索引对性能和可用性的影响很小。 你可以通过查询监控存储引擎的内部工作 information_schema 表 你可以通过查询监控存储引擎的性能细节 性能模式 表 你可以自由组合 InnoDB与其他MySQL存储引擎的表表,即使在同一个声明。例如,您可以使用 加入 将数据从操作 InnoDB和 MEMORY在一个单一的查询表 InnoDB设计了CPU的效率和处理大数据量时的最大性能。 InnoDB表可以处理大量的数据,即使在操作系统的文件大小限制为2GB。
InnoDB
InnoDB
指定一个 primary key 使用最频繁查询的列的每个表,或 自增量 Value if there is no obvious主键。 使用 加入 无论数据是基于从这些表中相同的ID值的多个表拉。快速连接性能,定义 外键 对同列,并宣布那些列在每个表中相同的数据类型。添加外键保证引用的列的索引,可以提高性能。外键也传播删除或更新所有受影响的表,如果对应的ID不在父表中提出防止在子表中插入数据。 关闭 自动提交 。犯次把帽子演出数百(由写你的存储设备速度的限制)。 分组组相关 DML 操作 交易 ,包围他们 START TRANSACTION和 承诺 声明.当你不想做太多,你也不想的问题一大堆 INSERT, UPDATE,或 DELETE运行时间没有提交报表。 不使用 LOCK TABLES声明. InnoDB 可以处理多个会话都读到同一张桌子上写作,在不牺牲可靠性和高性能。获得独家写访问的行集,使用 SELECT ... FOR UPDATE语法锁就行你打算更新。 使 innodb_file_per_table选项或使用一般的表空间将数据和索引表放在单独的文件中,而不是在 系统片 这个 innodb_file_per_table选项是默认 评估是否你的数据访问模式受益 InnoDB表或页 压缩 功能特色你可以压缩 InnoDB表不牺牲读/写能力 与选项运行服务器 --sql_mode=NO_ENGINE_SUBSTITUTION为了防止表被创建不同的存储引擎,如果有一个与指定的发动机问题 ENGINE=条款 CREATE TABLE
SHOW ENGINESInnoDB
MySQL >显示引擎;
INFORMATION_SCHEMA.ENGINES
MySQL SELECT * FROM information_schema.engines >;
InnoDB--default-storage-engine=InnoDBdefault-storage-engine=innodb
ENGINE=other_engine_nameCREATE TABLE
InnoDBALTER TABLE
table_name ENGINE=InnoDB;
CREATE TABLE InnoDB_Table (...) ENGINE=InnoDB AS SELECT * FROMother_engine_table;
InnoDB
InnoDB
一 原子性: C 一致性: I :绝缘 D durability:。
原子性
InnoDB
一致性
InnoDB
InnoDBdoublewrite缓冲 InnoDB崩溃恢复
隔离
InnoDB
耐久性
InnoDBdoublewrite缓冲 ,打开和关闭的 innodb_doublewrite配置选项 配置选项 sync_binlog写在一个存储设备的缓冲区,如磁盘驱动器、SSD、或RAID阵列。 在存储设备中的电池支持的高速缓存。 操作系统运行使用MySQL,特别是对其支持 fsync()系统调用 不间断电源(UPS)保护电力所有的计算机服务器和存储设备,运行MySQL服务器和存储MySQL数据。 您的备份策略,如频率和类型的备份,备份保留期。 分布式或托管的数据应用,特殊特性的数据中心在MySQL服务器的硬件设置,以及数据中心之间的网络连接。
InnoDBInnoDB
InnoDBDB_ROLL_PTRInnoDB
InnoDB
InnoDB
InnoDB
innodb_max_purge_lag
InnoDB
InnoDB
InnoDB
WHEREInnoDB
InnoDB
InnoDB
INSERTUPDATEDELETE
InnoDB
innodb_change_buffering
InnoDB标准监视器输出包括改变缓冲区状态信息。查看监控数据,问题 显示引擎INNODB STATUS 命令 mysql>
SHOW ENGINE INNODB STATUS\G改变缓冲区的状态信息是位于 INSERT BUFFER AND ADAPTIVE HASH INDEX标题,出现类似下面的: -------------------------------------插入缓冲和自适应哈希索引------------------------------------- IBUF:大小1,自由列表Len 0,赛格2号,0 mergesmerged操作:插入0,删除标记0,删除0discarded操作:插入0,删除标记0,删除0hash表大小4425293,用细胞32,结堆缓冲区1(S)13577.57哈希搜索/ s,202.47非哈希搜索/ 有关更多信息,参见 第15.16.3,“InnoDB标准监控锁监视器输出” 这个 INFORMATION_SCHEMA.INNODB_METRICS表提供了大部分数据点发现 InnoDB 标准监视器输出,加上其他数据点。查看改变缓冲度量和描述每一个,发出以下查询: mysql>
SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%'\G为 INNODB_METRICS表的使用信息,看 第15.14.6,“InnoDB information_schema度量表” 这个 INFORMATION_SCHEMA.INNODB_BUFFER_PAGE表提供的缓冲池中的每个网页的元数据,包括改变缓冲指数改变缓冲区位图页。改变缓冲页面是确定的 网页类型 IBUF_INDEX是改变缓冲索引页的页面类型,和 ibuf _位图 是改变缓冲区位图页的页面类型。 警告 查询 INNODB_BUFFER_PAGE表格可以引入显着的性能开销。为了避免影响性能,再现你想探讨的一个测试实例并运行您的查询测试实例的问题。 例如,你可以查询 INNODB_BUFFER_PAGE表来确定近似数 ibuf_index 和 IBUF_BITMAP页面缓冲池页面总数的百分比。 MySQL的> SELECT (SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE PAGE_TYPE LIKE 'IBUF%') AS change_buffer_pages,(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ((change_buffer_pages/total_pages)*100))AS change_buffer_page_percentage;--------------------- ------------- ------------------------------- | change_buffer_pages | total_pages | change_buffer_page_percentage | --------------------- ------------- ------------------------------- | 25 | 8192 | 0.3052 | --------------------- ------------- ------------------------------- 有关所提供的其他数据信息 INNODB_BUFFER_PAGE表,看 第24.35.1,“information_schema innodb_buffer_page表” 。有关使用信息,看 第15.14.5“InnoDB缓冲池,information_schema表” 性能模式 改变缓冲区的互斥等提供先进性能监测仪表。查看改变缓冲仪表,发出以下查询: mysql>
SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb/ibuf%';+-------------------------------------------------------+---------+-------+ | NAME | ENABLED | TIMED | +-------------------------------------------------------+---------+-------+ | wait/synch/mutex/innodb/ibuf_bitmap_mutex | YES | YES | | wait/synch/mutex/innodb/ibuf_mutex | YES | YES | | wait/synch/mutex/innodb/ibuf_pessimistic_insert_mutex | YES | YES | +-------------------------------------------------------+---------+-------+有关监测 InnoDB互斥等待,看 第15.15.2,“监测InnoDB互斥等使用性能模式”
InnoDBinnodb_adaptive_hash_index
InnoDB
LIKE
innodb_adaptive_hash_index_partsinnodb_adaptive_hash_index_parts
InnoDB
SEMAPHORESSHOW ENGINE INNODB
STATUS
innodb_log_buffer_size
innodb_flush_log_at_trx_commitinnodb_flush_log_at_timeout
InnoDBInnoDB
ibdata1innodb_data_file_path
InnoDBInnoDBInnoDB
fsync()
innodb_doublewrite
innodb_flush_method
innodb_rollback_segments
innodb_file_per_table.ibd
DYNAMIC
InnoDBCREATE TABLESPACE
CREATE TABLE
tbl_name ... TABLESPACE [=]
tablespace_nameALTER TABLE
tbl_name TABLESPACE [=]
tablespace_name
InnoDBinnodb_undo_tablespaces
innodb_undo_tablespaces
innodb_temp_data_file_pathinnodb_temp_data_file_pathinnodb_data_home_dir
INFORMATION_SCHEMA.FILES
mysql> SELECT * FROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME='innodb_temporary'\G
INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO
innodb_temp_data_file_path
MySQL的> SELECT @@innodb_temp_data_file_path;------------------------------ | @ @ InnoDB _ _文件日期时间_ _路径| ------------------------------ | ibtmp1::autoextend | ------------------------------ 12M
INFORMATION_SCHEMA.FILES
MySQL的> SELECT FILE_NAME, TABLESPACE_NAME, ENGINE, INITIAL_SIZE, TOTAL_EXTENTS*EXTENT_SIZEAS TotalSizeBytes, DATA_FREE, MAXIMUM_SIZE FROM INFORMATION_SCHEMA.FILESWHERE TABLESPACE_NAME = 'innodb_temporary'\G*************************** 1。行:*************************** file_name。/ ibtmp1tablespace_name:innodb_temporary引擎:InnoDB initial_size:12582912:12582912:6291456 totalsizebytes data_free maximum_size:空
TotalSizeBytes
innodb_temp_data_file_pathinnodb_data_home_dir
innodb_temp_data_file_path
innodb_temp_data_file_path
[mysqld]innodb_temp_data_file_path=ibtmp1:12M:autoextend:max:500M
innodb_temp_data_file_path
default_tmp_storage_engineinternal_tmp_disk_storage_engineMyISAM
innodb_rollback_segments
InnoDB
ib_logfile0
InnoDBInnoDBInnoDB
COMMIT
InnoDB
InnoDB
第15.5.1,“InnoDB锁定” 介绍了使用的锁定类型 InnoDB第15.5.2,“InnoDB事务模型” 介绍了事务隔离级别和锁定策略的各。还讨论了使用 autocommit,一致的非锁定读,读和锁定。 第15.5.3,“锁由InnoDB”不同的SQL语句 探讨了在特定类型的锁 InnoDB各种报表 第15.5.4,“Phantom Rows” 介绍了如何 InnoDB用下键锁定避免幻像行。 第15.5.5,“会”Deadlocks 提供一个例子讨论了死锁,死锁检测和回滚,并为减少和处理死锁的小费 InnoDB
InnoDB
InnoDBSX
一 共享( S)锁 许可证持有锁读一行的交易。 一个 (Exclusive X)锁 许可证持有锁的更新或删除行的交易。
T1ST2
一个请求 T2对于一个 S锁可以立即授予。作为一个结果,两 T1 和 T2持有 S锁上 R 一个请求 T2对于一个 X锁不能立即授予
T1XT2T2r
InnoDBLOCK TABLES ...
WRITEInnoDB
SELECT ...
FOR SHARESELECT ... FOR
UPDATE
在交易前可以获得一个共享锁在一个表中的行,它必须首先获得 IS锁或更强的桌上 在交易前可以对一个表中的一个排他锁,它必须首先获得 IX桌子上的锁
X | IX | S | IS | |
|---|---|---|---|---|
X | ||||
IX | ||||
S | ||||
IS |
LOCK
TABLES ... WRITE
SHOW
ENGINE INNODB STATUS
TABLE LOCK table `test`.`t` trx id 10080 lock mode IX
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;10
InnoDB
SHOW
ENGINE INNODB STATUS
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t` trx id 10078 lock_mode X locks rec but not gap Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0 0: len 4; hex 8000000a; asc ;; 1: len 6; hex 00000000274f; asc 'O;; 2: len 7; hex b60000019d0110; asc ;;
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20
FOR UPDATE;t.c1
id
SELECT * FROM child WHERE id = 100;
id
InnoDB
READ COMMITTED
READ COMMITTEDUPDATEWHEREUPDATE
InnoDBR
(negative infinity, 10] (10, 11] (11, 13] (13, 20] (20, positive infinity)
InnoDBREPEATABLE READ
SHOW
ENGINE INNODB STATUS
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t` trx id 10080 lock_mode X Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0 0: len 8; hex 73757072656d756d; asc supremum;; Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0 0: len 4; hex 8000000a; asc ;; 1: len 6; hex 00000000274f; asc 'O;; 2: len 7; hex b60000019d0110; asc ;;
INSERT
mysql>CREATE TABLE child (id int(11) NOT NULL, PRIMARY KEY(id)) ENGINE=InnoDB;mysql>INSERT INTO child (id) values (90),(102);mysql>START TRANSACTION;mysql>SELECT * FROM child WHERE id > 100 FOR UPDATE;+-----+ | id | +-----+ | 102 | +-----+
mysql>START TRANSACTION;mysql>INSERT INTO child (id) VALUES (101);
SHOW ENGINE INNODB
STATUS
RECORD LOCKS space id 31 page no 3 n bits 72 index `PRIMARY` of table `test`.`child`
trx id 8731 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 80000066; asc f;;
1: len 6; hex 000000002215; asc " ;;
2: len 7; hex 9000000172011c; asc r ;;...
AUTO-INC
innodb_autoinc_lock_mode
InnoDB
SPATIALREPEATABLE
READSERIALIZABLE
SPATIALSPATIAL
InnoDBInnoDBInnoDBInnoDB
InnoDBREAD UNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLEREPEATABLE READ
SET
TRANSACTION--transaction-isolation
InnoDBREPEATABLE READREAD COMMITTEDREAD UNCOMMITTEDSERIALIZABLEREPEATABLE
READ
这是默认的隔离级别 InnoDB一致性读 在同一个事务读取 快照 在第一次读了。这意味着如果你问题的几种普通(非锁定) SELECT在相同的交易报表,这些 SELECT陈述是一致的也就彼此。看到 第15.5.2.3,“一致的非锁定读” 为 锁定读 ( SELECT与 更新 或 FOR SHARE), UPDATE,和 DELETE报表,锁定取决于语句使用唯一索引的一个独特的搜索条件,或一系列类型的搜索条件。 一个独特的试验指标与搜索条件, InnoDB唯一的索引记录发现锁,不 Gap 在它之前 对于其他搜索条件, InnoDB锁的索引范围扫描,使用 间隙锁 或 下一个关键的锁 块插入到其他课程所覆盖的区域差距。关于间隙锁next-key锁信息,看 第15.5.1,“InnoDB锁定”
每个一致性读,即使在同一个事务,集和读自己的新快照。关于一致性读的信息,参见 第15.5.2.3,“一致的非锁定读” 锁定读( SELECT与 更新 或 FOR SHARE), UPDATE报表,并 DELETE声明, InnoDB 唯一索引记录锁,不是差距在他们面前,从而允许插入新记录的自由下锁定记录。间隙锁仅用于外键约束检查和重复键检查。 因为间隙锁是禁用的,可能会出现幽灵的问题,其他会话可以插入新的行插入空白。关于幻影,看 第15.5.4,“Phantom Rows” 只有基于行的二进制日志的支持与 READ COMMITTED隔离级别。如果你使用 提交读 与 binlog_format=MIXED,服务器自动使用基于行的日志。 使用 READ COMMITTED有其他的作用: 考虑下面的例子,从这张桌子: CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB; INSERT INTO t VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
在这种情况下,表没有索引,所以搜索和索引扫描使用隐藏的聚集索引记录锁(见 第15.8.2.1,“聚集和二级指标” )而非索引列 假设一个会话执行 UPDATE使用这些语句: # Session ASTART TRANSACTION;UPDATE t SET b = 5 WHERE b = 3;
假设第二会话执行 UPDATE通过执行这些语句后的第一次会议: # Session BUPDATE t SET b = 4 WHERE b = 2;
作为 InnoDB实行各 UPDATE,它首先获取每一个排他锁,然后决定是否修改。如果 InnoDB不修改行时,它将释放锁。否则, InnoDB保留锁直到事务结束。这会影响事务处理如下。 使用默认的时 REPEATABLE READ第一级分离, UPDATE获得每一行,一个他读不释放任何人: X-lock(1.2);retain X-Lockx-lock(2.3);Update(2.3)to(2.5);retain X-Lockx-lock(3.2);retain x-ockx-lock(4.3);update(4.3)to(4.5);retain X-Lockx-lock(5.2);retain X-lock 第二 UPDATE块,只要它试图获取任何锁(因为第一次更新保留锁定所有行),而不进行直到第一 UPDATE提交或回滚: 他(1,2);阻塞并等待第一次更新提交或回滚 如果 READ COMMITTED代替,第一 UPDATE每行一个他获得它读取并释放那些不修改的行: X-lock(1.2);unlock(1.2)x-lock(2.3);Update(2.3)to(2.5);retain X-Lockx-lock(3.2);unlock(3..2)x-lock(4.3);update(4.3)to(4.5);retain X-Lockx-Lock(5.2);UNlock(5.2) 第二 UPDATE, InnoDB 做一个 “ 半一致 “ 阅读,返回最新的提交版本每行读取MySQL,MySQL可以决定是否行匹配 WHERE条件的 UPDATE: 的X锁(1.2);(2)Update to retain X(1);(2);lockx锁锁解锁(2)×(3);(3)Update to retain X(3);(4);lockx锁解锁锁(X(4)更新(2);(4);2)to retain X锁 然而,如果 WHERE条件包括一个索引列,和 InnoDB 使用索引、唯一索引列时是考虑采取和保持记录锁。在下面的例子中,第一个 UPDATEtakes and retains an x-lock on each row where b = 2. The secondUPDATE块,当它试图获得对同一记录x-locks,因为它也使用索引定义在B栏 CREATE TABLE t (a INT NOT NULL, b INT, c INT, INDEX (b)) ENGINE = InnoDB;INSERT INTO t VALUES (1,2,3),(2,2,4);COMMIT;# Session ASTART TRANSACTION;UPDATE t SET b = 3 WHERE b = 2 AND c = 3;# Session BUPDATE t SET b = 4 WHERE b = 2 AND c = 4;
影响使用 READ COMMITTED隔离级别是使不一样 innodb_locks_unsafe_for_binlog配置选项,这些例外: 有可能 innodb_locks_unsafe_for_binlog是一个全局设置,会影响所有的会话,而隔离级别可以设置全局的所有会话,每个会话或单独。 innodb_locks_unsafe_for_binlog只能设置在服务器启动,而隔离级别可以设置在启动或在运行时改变。
READ COMMITTED因此提供更精细和更灵活的控制比 innodb_locks_unsafe_for_binlogSELECT报表是一个非锁定的方式进行,但一个可能的早期行版本可以使用。因此,使用这种隔离级别,这样的阅读是不一致的。这也被称为 脏读 。否则,该隔离级别的作品像 READ COMMITTED这个水平是一样的 REPEATABLE READ,但 InnoDB 隐式转换所有的平原 SELECT报表 SELECT ... FOR SHARE如果 autocommit被禁用。如果 autocommit启用的 SELECT是自己的事务。因此它是只读和可序列化,如果作为一个一致的表现(非锁定)读不需要为其他交易块。(力平 SELECT阻止其他事务修改如果选定行,禁用 autocommit。)
InnoDBautocommitautocommit
autocommitSTART
TRANSACTIONBEGINCOMMITROLLBACK
autocommitSET autocommit = 0COMMITROLLBACK
autocommit
COMMIT
COMMITROLLBACKCOMMITROLLBACK
SET autocommit
= 0COMMITROLLBACKSTART
TRANSACTIONCOMMITROLLBACK
内核> mysql test
MySQL的> CREATE TABLE customer (a INT, b CHAR (20), INDEX (a));查询行,0行受影响(0秒)MySQL > -- Do a transaction with autocommit turned on.MySQL的> START TRANSACTION;查询行,0行受影响(0秒)MySQL > INSERT INTO customer VALUES (10, 'Heikki');查询行,1行的影响(0秒)MySQL > COMMIT;查询行,0行受影响(0秒)MySQL > -- Do another transaction with autocommit turned off.MySQL的> SET autocommit=0;查询行,0行受影响(0秒)MySQL > INSERT INTO customer VALUES (15, 'John');查询行,1行的影响(0秒)MySQL > INSERT INTO customer VALUES (20, 'Paul');查询行,1行的影响(0秒)MySQL > DELETE FROM customer WHERE b = 'Heikki';查询行,1行的影响(0秒)MySQL > -- Now we undo those last 2 inserts and the delete.MySQL的> ROLLBACK;查询行,0行受影响(0秒)MySQL > SELECT * FROM customer;————| A B | | ------ -------- | 10 |海基|————在1行集(0.00美国证券交易委员会(SEC)的MySQL >
在交易客户端语言
COMMITSELECTINSERT
InnoDBSELECT
REPEATABLE READ
READ COMMITTED
InnoDBSELECTREAD COMMITTEDREPEATABLE READ
REPEATABLE READSELECT
SELECTDELETEUPDATE
SELECT COUNT(c1) FROM t1 WHERE c1 = 'xyz'; -- Returns 0: no rows match. DELETE FROM t1 WHERE c1 = 'xyz'; -- Deletes several rows recently committed by other transaction. SELECT COUNT(c2) FROM t1 WHERE c2 = 'abc'; -- Returns 0: no rows match. UPDATE t1 SET c2 = 'cba' WHERE c2 = 'abc'; -- Affects 10 rows: another txn just committed 10 rows with 'abc' values. SELECT COUNT(c2) FROM t1 WHERE c2 = 'cba'; -- Returns 10: this txn can now see the rows it just updated.
SELECTSTART TRANSACTION WITH
CONSISTENT SNAPSHOT
Session A Session B
SET autocommit=0; SET autocommit=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
READ
COMMITTED
SELECT * FROM t FOR SHARE;
READ COMMITTEDSELECT
一致性读不工作 DROP TABLE,因为MySQL不能使用表已经下降 InnoDB destroys桌 一致性读不工作 ALTER TABLE,因为声明对原表临时复制和删除原表当临时复制是建立。当你重新一致读的事务中,新表中的行不可见,因为那些行不存在交易时的快照拍摄。在这种情况下,交易会返回一个错误: ER_TABLE_DEF_CHANGED, “ 表的定义已经改变,请重试事务 “
INSERT INTO ...
SELECTUPDATE
... (SELECT)CREATE TABLE ...
SELECTFOR SHARE
默认情况下, InnoDB使用更强的锁, SELECT部分像 READ COMMITTED,每个一致性读,即使在同一个事务,集和读自己的新快照。 在这种情况下,使用一致的读取,设置事务的隔离级别 READ UNCOMMITTED, READ COMMITTED,或 REPEATABLE READ(这是比其他任何东西 SERIALIZABLE)。在这种情况下,没有锁上设置从选定表中读取行。
SELECT
设置一个共享模式锁在任何行,读。其他会议可以读取数据,但不能修改它们,直到你的事务提交。如果这些行被另一个事务未提交的改变,你的查询等待直到交易结束,然后用新的值。 笔记 SELECT ... FOR SHARE是一种替代 选择锁在共享模式 ,但 LOCK IN SHARE MODE仍然可以向后兼容。语句是等价的。然而, 分享 支持 OFtable_name, 不等待 ,和 SKIP LOCKED选项看到 锁定读并发NOWAIT跳过锁定 索引记录搜索的邂逅,锁定行和任何相关的指标项,如你一样发出 UPDATE这些行的声明。其他事务不能更新的行,做 选择分享 ,或在某些事务隔离级别的数据读取。一致性读忽略在阅读观存在的记录集任何锁。(一个记录不能老版本被锁定;他们重建的应用 UNDO日志 在记录的内存拷贝。)
FOR SHARE
START
TRANSACTIONautocommit
t2
SELECT * FROM t1 WHERE c1 = (SELECT c1 FROM t2) FOR UPDATE;
t2
SELECT * FROM t1 WHERE c1 = (SELECT c1 FROM t2 FOR UPDATE) FOR UPDATE;
child
PARENTSELECT
SELECT
SELECT * FROM parent WHERE NAME = 'Jones' FOR SHARE;
FOR SHARECHILD
CHILD_CODESCHILD
FOR SHARE
FOR
UPDATE
SELECT counter_field FROM child_codes FOR UPDATE;UPDATE child_codes SET counter_field = counter_field + 1;
SELECT ... FOR
UPDATEUPDATE
SELECT ... FOR
UPDATE
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1);SELECT LAST_INSERT_ID();
SELECT
SELECT ... FOR
UPDATE
NO WAITSELECT ... FOR
UPDATE
NOWAIT锁定阅读使用 NOWAIT不要等待获取锁。查询立即执行,没有一个错误如果请求的行锁。 SKIP LOCKED锁定阅读使用 SKIP LOCKED不要等待获取锁。执行查询立即解除闭锁行的结果集。 笔记 跳过锁定行返回不一致的数据视图查询。 SKIP LOCKED因此不适合普通的事务性工作。然而,它可以用来避免锁争用时,多个会话访问同一队列的表。
NO WAIT
NO WAIT
NOWAITNOWAIT
# Session 1: mysql>CREATE TABLE t (i INT, PRIMARY KEY (i)) ENGINE = InnoDB;mysql>INSERT INTO t (i) VALUES(1),(2),(3);mysql>START TRANSACTION;mysql>SELECT * FROM t WHERE i = 2 FOR UPDATE;+---+ | i | +---+ | 2 | +---+ # Session 2: mysql>START TRANSACTION;mysql>SELECT * FROM t WHERE i = 2 FOR UPDATE NOWAIT;ERROR 3572 (HY000): Do not wait for lock. # Session 3: mysql>START TRANSACTION;mysql>SELECT * FROM t FOR UPDATE SKIP LOCKED;+---+ | i | +---+ | 1 | | 3 | +---+
UPDATEDELETEInnoDB
InnoDB
InnoDB
SELECT ... FROM是一个一致性读,读数据库快照和设置没有锁,除非事务隔离级别设置为 SERIALIZABLE。为 SERIALIZABLE水平,搜索设置共享的索引记录它遇到下一个关键的锁。然而,只有一个索引记录锁是锁行语句使用一个独特的指标来寻找一个独特的行要求。 SELECT ... FOR UPDATE和 SELECT ... FOR SHARE语句中使用唯一索引获取锁和释放锁的扫描行,行不符合包含在结果集(例如,如果他们不符合特定的标准 哪里 条款)。然而,在某些情况下,行可能不会马上解锁,因为结果行和源之间的关系,在查询过程中丢失了。例如,在一个 UNION,扫描(锁)从一个表中的行可以被插入到一个临时表在评估他们是否符合资格的结果集。在这种情况下,在临时表中的行在原来的表中的行的关系失去了后者的行不上锁,直到查询执行结束。 为 锁定读 ( SELECT与 更新 或 FOR SHARE), UPDATE,和 DELETE报表,都取决于语句使用唯一索引的一个独特的搜索条件的锁,或一系列类型的搜索条件。 一个独特的试验指标与搜索条件, InnoDB唯一的索引记录发现锁,不 Gap 在它之前 另一种不同的条件,而非独特的条件, InnoDB锁的索引范围扫描,使用 间隙锁 或 下一个关键的锁 块插入到其他课程所覆盖的区域差距。关于间隙锁next-key锁信息,看 第15.5.1,“InnoDB锁定”
索引记录搜索的遭遇, SELECT ... FOR UPDATE块其他会话做 SELECT ... FOR SHARE或在某些事务隔离级别的阅读。一致性读忽略在阅读观存在的记录集任何锁。 UPDATE ... WHERE ...设置一个专属next-key锁在每个记录搜索的遭遇。然而,只有一个索引记录锁是锁行语句使用一个独特的指标来寻找一个独特的行要求。 什么时候 UPDATE修改一个聚集索引记录,隐锁是针对次级索引记录的影响。这个 UPDATE操作也需要共享锁在受影响的辅助索引记录时执行重复检查扫描插入新的辅助索引记录之前,当插入新的辅助索引记录。 DELETE FROM ... WHERE ...设置一个专属next-key锁在每个记录搜索的遭遇。然而,只有一个索引记录锁是锁行语句使用一个独特的指标来寻找一个独特的行要求。 INSERT设置在插入一个排他锁。这把锁是一个索引记录锁,不下钥匙锁(即没有间隙锁)并不会阻止其他会话插入间隙插入行之前。 在插入行之前,一种被称为间隙锁插入意向间隙锁设置。这锁信号的意图将在这样一种方式,多个事务插入同一指标的差距不需要如果他们不是插在缝隙内的同一位置等待对方。假设有一个记录索引值4和7。两个事务试图插入5和6每个锁的缺口4和7之间插入意向锁获取插入行的排他锁之前的值,但不阻止对方因为排不冲突。 如果一个duplicate-key错误发生,一个共享锁的重复的索引记录集。使用一个共享锁会导致死锁在多个会话试图插入同一行,如果另一个会话已经独占锁。这可以在另一个session删除行时。假设一个 InnoDB表 T1 具有以下结构: CREATE TABLE t1 (i INT, PRIMARY KEY (i)) ENGINE = InnoDB;
现在假设3届执行以下操作顺序: 会话1: START TRANSACTION; INSERT INTO t1 VALUES(1);
第二: START TRANSACTION; INSERT INTO t1 VALUES(1);
会话3: START TRANSACTION; INSERT INTO t1 VALUES(1);
会话1: ROLLBACK;
通过1届的操作获取排他锁。运作会议2和3的结果都是一个重复键错误都要求行共享锁。当会话1回滚,它释放排它独占锁和共享锁请求的排队会话二、三是理所当然的。在这一点上,2届和3死锁:既不可以因为分享对方持有的锁获取排他锁。 类似的情况发生,如果表已经包含关键值1和三届行按顺序执行如下操作: 会话1: START TRANSACTION; DELETE FROM t1 WHERE i = 1;
第二: START TRANSACTION; INSERT INTO t1 VALUES(1);
会话3: START TRANSACTION; INSERT INTO t1 VALUES(1);
会话1: COMMIT;
通过1届的操作获取排他锁。通过会议和操作的结果都是一个重复键错误都要求行共享锁。当第一次提交时,它释放排它独占锁和共享锁请求的排队会话二、三是理所当然的。在这一点上,2届和3死锁:既不可以因为分享对方持有的锁获取排他锁。 INSERT ... ON DUPLICATE KEY UPDATE简单的白喉 INSERT在专用锁,而不是一个共享锁放在行被更新时,重复键错误发生。独家索引记录锁为重复的主键值。独家next-key锁为一份独特的核心价值。 INSERT INTO T SELECT ... FROM S WHERE ...设置一个唯一索引记录锁(没有间隙锁)在每一行插入 T 。如果事务隔离级别 READ COMMITTED, InnoDB 做搜索 S作为一个一致性读(无锁)。否则, InnoDB 设置共享行下关键锁 SInnoDB 在后者的情况下设置有锁:前滚恢复使用基于语句的二进制日志中,SQL语句都必须以完全相同的方式完成它是最初。 CREATE TABLE ... SELECT ...执行 SELECT共享下钥匙锁或一致读的,至于 INSERT ... SELECT当一个 SELECT用于构建 替换选择…从在哪里… 或 UPDATE t ... WHERE col IN (SELECT ... FROM s ...), InnoDB 设置共享行从桌下钥匙锁 s初始化一个先前指定的时 AUTO_INCREMENT在表列, InnoDB 设置关联的指标最终独占锁 AUTO_INCREMENT专栏在访问自动递增计数器, InnoDB 使用一个特定的 AUTO-INC表锁模式,锁只持续到当前的SQL语句的结束,而不是整个交易结束。其他会议不能插入表时 auto-inc 表锁;看 第15.5.2,“InnoDB事务模型” InnoDB取先前初始化值 汽车 没有设置任何锁柱 如果一个 FOREIGN KEY约束是一个表定义的任何插入、更新或删除需要约束条件进行检查记录集的共享锁的记录,它看起来在检查约束。 InnoDB 还设置这些锁的情况下,约束失败。 LOCK TABLES集表锁,但它是更高的MySQL层以上 InnoDB 层设置这些锁 InnoDB意识到表锁如果 innodb_table_locks = 1(默认的), autocommit = 0层以上,和mysql InnoDB 知道行级锁 否则, InnoDB的自动死锁检测无法检测到死锁所涉及的如表锁。同时,因为在这种情况下,较高的MySQL层不知道行级锁,它是可能得到表上,另一个会话的当前行级锁表锁。然而,这并不影响交易的完整性,如在 第15.5.5.2,“死锁检测和回滚” 。参见 第15.8.1.7”限制,InnoDB表”
SELECT
id
SELECT * FROM child WHERE id > 100 FOR UPDATE;
ididSELECT
InnoDBInnoDBR
InnoDBInnoDB
UPDATESELECT ... FOR
UPDATE
LOCK TABLESSELECT ... FOR
UPDATESELECT ...
FOR UPDATEUPDATE ... WHERE
InnoDBinnodb_deadlock_detectinnodb_lock_wait_timeoutSHOW ENGINE INNODB
STATUSinnodb_print_all_deadlocks
S
MySQL的> CREATE TABLE t (i INT) ENGINE = InnoDB;查询行,0行受影响(1.07秒)MySQL > INSERT INTO t (i) VALUES(1);查询行,1行的影响(0.09秒)MySQL > START TRANSACTION;查询行,0行受影响(0秒)MySQL > SELECT * FROM t WHERE i = 1 FOR SHARE;------ |)| | 1 |??????
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
XS
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
XXSSXX
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
InnoDBInnoDB
InnoDBinnodb_table_locks = 1autocommit = 0LOCK TABLESinnodb_lock_wait_timeout
InnoDB
SELECTROLLBACK
LATEST DETECTED DEADLOCK
innodb_lock_wait_timeoutinnodb_deadlock_detect
InnoDB
在任何时候,问题 SHOW ENGINE INNODB STATUS命令确定最近的僵局的原因。这可以帮助你调整你的应用程序避免死锁。 如果频繁死锁的警告引起关注,收集更广泛的调试信息,使 innodb_print_all_deadlocks配置选项。每一个死锁的信息,而不只是最新的一个,是记录在MySQL 错误日志 。禁用该选项,当你完成调试。 永远不因僵局准备再发行交易。死锁是危险的。你就再试试。 保持事务小时间短,使它们不易碰撞。 提交事务制定一套相关的变化,使它们不容易受到碰撞后立即。特别是,不要把一个互动 MySQL 对于一个未提交的事务,长时间打开会话。 如果你使用 锁定读 ( SELECT ... FOR UPDATE或 选择分享 ),尝试使用较低的隔离级别等 READ COMMITTED当修改多个表在一个事务内,或不同组的同一个表中的行,以一致的顺序每次做这些操作。然后交易形式定义的队列不僵局。例如,组织的数据库操作功能在您的应用程序,或调用存储程序,而不是多个相似序列编码 INSERT, 更新 ,和 DELETE在不同地方的声明 选择好你的表添加索引。那么你的查询需要扫描更少的索引记录从而设置更少的锁。使用 EXPLAIN SELECT确定指标的MySQL服务器视为最适合您的查询。 少用锁。如果你能够允许 SELECT将数据从一个旧的快照返回,不添加条款 更新 或 FOR SHARE它。使用 READ COMMITTED这里的隔离级别是好的,因为在相同的事务一致性读写各从自己的新快照。 如果没有其他的帮助,序列化你的交易表级锁。正确的使用方法 LOCK TABLES事务表,如 InnoDB 表,是开始一个事务 SET autocommit = 0(不 START TRANSACTIONfollowed by) LOCK TABLES并不是说, UNLOCK TABLES直到提交事务明确。例如,如果你需要写表 T1 读表 t2,你可以这样做: SET autocommit=0;LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...打开表提交; 表级锁防止并发更新的表,避免死锁在不反应的费用为一个繁忙的系统。 另一种方法是创建一个辅助序列化事务 “ 信号量 “ 表只包含一个行。有排在访问其他表中每个事务的更新。这样,所有的交易都发生在一个串行的方式。请注意, InnoDB即时的死锁检测算法也可以在这种情况下,因为序列化锁是一个行级锁。MySQL表级锁,超时必须用来解决死锁的方法。
InnoDBInnoDB
InnoDBInnoDB
InnoDB
InnoDBInnoDB
InnoDB
mysqld-auto.cnf--defaults-file
mysqld --defaults-file=path_to_configuration_fileInnoDB
C:\Program Files\MySQL\MySQL Server
8.0\bin
C:\> "C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld" --console
bin
内核> bin/mysqld --user=mysql &
InnoDB
InnoDB*.ibd
在某些情况下,数据库性能提高的数据是不是都放在同一个物理磁盘。将日志文件放在不同的磁盘数据是性能往往有益。例如,您可以将系统表空间的数据文件在不同的磁盘上的日志文件。你也可以使用原始磁盘分区(原设备)为 InnoDB数据文件,这可能会加速I / O的看 第15.7.3,“使用原始磁盘分区的系统表空间” InnoDB是一个交易的安全(酸标准)的MySQL已经提交,存储引擎回滚和崩溃恢复功能,保护用户数据。 然而,它不能这样做 如果底层的操作系统或硬件不成功。许多操作系统或磁盘子系统可能会延迟或重新排序来提高性能的写操作。在一些操作系统,很 fsync()系统调用,应该等到一个文件的所有不成文的数据已被刷新可能会在返回的数据已经刷新到稳定存储器。正因为如此,操作系统崩溃或断电可能会破坏最近提交的数据,或在最坏的情况下,甚至破坏数据库因为写已经重新排序操作。如果数据的完整性是很重要的你,做一些 “ 拔插头 “ 在使用任何生产试验。在OS X 10.3高, InnoDB使用一种特殊的 fcntl() 文件清除的方法。在Linux的领导下,这是明智的 禁用写回缓存 对ATA SATA磁盘驱动器,命令 hdparm -W0 /dev/hda可以禁用回写高速缓存。 要注意的是,一些驱动器或磁盘控制器可能无法禁用写回缓存。 关于 InnoDB恢复功能,保护用户数据, InnoDB 使用一个文件冲洗技术涉及的结构称为 doublewrite缓冲 ,这是默认启用的( innodb_doublewrite=ON)。的doublewrite缓冲增加了安全恢复后死机或停电,并通过减少需要提高对UNIX大部分品种表现 fsync() 运营建议 innodb_doublewrite选项是启用如果你关心的是数据的完整性和可能出现的故障。关于doublewrite缓冲的更多信息,参见 “第15.11.1 InnoDB,磁盘I / O” 在使用NFS与 InnoDB,审查潜在问题概述 使用NFS与MySQL
innodb_data_file_pathinnodb_data_file_path
;
innodb_data_file_path=datafile_spec1【; datafile_spec2]…
ibdata1
[mysqld] innodb_data_file_path=ibdata1:12M:autoextend
KG
对于一个 innodb_page_size16Kb或价值较小,最小的文件大小为3MB。 对于一个 innodb_page_size值32KB,最小的文件大小为6MB。 对于一个 innodb_page_size值为64KB,最小的文件大小是12mb。
ibdata1
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
autoextend
file_name:file_size[:autoextend[:max:max_file_size]]
autoextendinnodb_data_file_path
autoextendautoextendinnodb_autoextend_increment
InnoDBautoextendibdata1
[mysqld]innodb_data_file_path=ibdata1:12M:autoextend:max:500M
InnoDBdatadirinnodb_data_home_diribdata2InnoDB
[mysqld]innodb_data_home_dir = /path/to/myibdata/innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
innodb_data_home_dir
InnoDBmkdir
InnoDBinnodb_data_home_dirinnodb_data_home_dir./
innodb_data_home_dirinnodb_data_file_path
[mysqld]innodb_data_home_dir =innodb_data_file_path=/path/to/myibdata/ibdata1:50M;/path/to/myibdata/ibdata2:50M:autoextend
InnoDBdatadirib_logfile1
innodb_log_group_home_dir定义目录路径 InnoDB 日志文件(重做日志)。如果这个选项是不配置, InnoDB日志文件是在MySQL数据目录中创建( datadir) 你可以使用这个选项的地方 InnoDB日志文件存储在不同的物理存储位置 InnoDB 数据文件以避免潜在的I/O资源冲突。例如: [mysqld] innodb_log_group_home_dir = /dr3/iblogs
笔记 InnoDB无法创建目录,所以确保在你启动服务器日志目录存在。使用Unix或DOS mkdir 命令创建必要的目录 确保MySQL服务器具有适当的访问权限在日志目录中创建文件。更普遍的是,服务器必须在任何需要的地方创建日志文件目录的访问权限。 innodb_log_files_in_group定义日志的日志文件组的数目。默认的推荐值为2。 innodb_log_file_size定义在日志组中的每个日志文件的字节大小。日志文件的大小( innodb_log_file_size* innodb_log_files_in_group)不能超过一个,略小于最大值512gb。例如一对255 GB的日志文件,接近极限但不超过它。默认的日志文件的大小是48mb。一般来说,对日志文件的大小应足够大,使服务器能够顺利的高峰和低谷负荷的活动,这通常意味着有足够的日志空间来处理一个多小时写作业。这个值越大,越检查点刷新活动在缓冲池的需要,节省磁盘I / O的更多信息,参见 8.5.4节,“优化InnoDB重做日志”
innodb_undo_directoryinnodb_undo_directorydatadirinnodb_undo_directory
innodb_undo_tablespaces
InnoDBinnodb_data_home_dirinnodb_temp_data_file_path
innodb_temp_data_file_pathinnodb_data_home_dirinnodb_temp_data_file_path
innodb_data_home_dirdatadir
innodb_temp_data_file_path
innodb_page_size
InnoDB
InnoDBkey_buffer_size
InnoDB
innodb_buffer_pool_size定义了缓冲池的大小,这是保存缓存数据的存储区 InnoDB 表,索引,及其他辅助缓冲区。缓冲池的大小,系统的性能是非常重要的,这是典型的建议 innodb_buffer_pool_size配置为50%到75%的系统内存。默认的缓冲池大小为128MB。额外的指导,看 第8.12.3.1,“MySQL如何使用内存” 。有关如何配置 InnoDB缓冲池的大小,看 第15.6.3.2,“配置InnoDB缓冲池大小” 。缓冲池的大小可以配置在启动或动态。 在大量的存储系统,你可以通过划分成多个缓冲池,缓冲池的情况下改善并发性。缓冲池的实例数量的控制 innodb_buffer_pool_instances选项默认情况下, InnoDB 创建一个缓冲池的实例。缓冲池的实例数量可以配置在启动时。有关更多信息,参见 第15.6.3.3,“配置多个缓冲池的实例” innodb_log_buffer_size定义字节大小的缓冲区 InnoDB 使用磁盘写入日志文件。默认大小为16MB。一个大的日志缓冲区使大交易运行而不需要在事务提交日志写入磁盘。如果你有交易,更新、插入或删除多行,你可能会考虑增加日志缓冲区的大小以节省磁盘I / O. innodb_log_buffer_size可以配置在启动时。相关的信息,看 8.5.4节,“优化InnoDB重做日志”
glibc
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
sort_buffer_size +
read_buffer_size
InnoDB
InnoDB--innodb-read-only
如何使
innodb_change_buffering=0
如果实例是只读介质如CD或DVD,或 /var目录不可写的: --pid-file=path_on_writeable_media和 --event-scheduler=disabled--innodb_temp_data_file_path。此选项指定的路径、文件名、文件大小 InnoDB 临时表空间的数据文件。默认设置是 ibtmp1:12M:autoextend,造成 ibtmp1 在数据目录中的临时表空间的数据文件。准备只读操作的一个实例,设置 innodb_temp_data_file_path在数据目录以外的位置。路径必须相对于数据目录;例如: --innodb_temp_data_file_path=../../../tmp/ibtmp1:12M:autoextend
innodb_read_onlyInnoDBinnodb_read_onlyANALYZE
TABLEALTER TABLE
tbl_name
ENGINE=engine_name
mysqlCREATE USERGRANTREVOKEINSTALL PLUGIN
使用场景
分配一个MySQL的应用程序,或一套MySQL数据,在只读存储介质如CD或DVD。 多个MySQL实例查询相同的数据目录的同时,在一个典型的数据仓库结构。你可以使用这种技术来避免 瓶颈 可以与负载沉重的MySQL实例出现,或者你会调整每一个查询特定种类的各种情况下使用不同的配置选项。 已投入安全或数据完整性的只读状态数据的查询,如归档备份数据。
工作原理
--innodb-read-only
否 变化的缓冲 做,特别是没有将从变化的缓冲。确保更改缓冲区是空的当你准备只读操作实例,禁止改变缓冲( innodb_change_buffering=0)and do a 缓慢关闭 第一 因为 重做日志文件 不用于只读操作,您可以设置 innodb_log_file_size为了尽可能最小化(1MB)之前的实例为只读。 所有的后台线程以外的I / O读线程关闭。作为一个结果,一个只读实例不能遇到任何 死锁 关于死锁,监视器输出信息,等等不写入临时文件。作为一个结果, SHOW ENGINE INNODB STATUS不产生任何输出 配置选项设置通常会改变写操作行为的变化,没有任何效果,当服务器处于只读模式。 这个 撤消日志 不使用。对于禁用任何设置 innodb_undo_tablespaces和 innodb_undo_directory配置选项
InnoDB
InnoDBInnoDB
InnoDB
理想情况下,你设置的缓冲池的大小以及实际的大的值,留下足够的内存用于其他进程在服务器运行没有过度分页。该缓冲池更大,更 InnoDB就像一个内存数据库,从磁盘读取数据一次然后访问存储器的数据在随后的读。看到 第15.6.3.2,“配置InnoDB缓冲池大小” 与大的内存大小,64位系统,你可以将缓冲池分成多个部分,减少之间的并行操作的内存结构竞争。详情见 第15.6.3.3,“配置多个缓冲池的实例” 你可以把经常访问的数据在内存中尽管如备份或报告经营活动突。详情见 第15.6.3.4,“缓冲池扫描耐” 你可以控制何时以及如何 InnoDB执行预读要求预取页面进入缓冲池的情况,预计很快将会需要的页面。详情见 第15.6.3.5”配置,InnoDB缓冲池预取(预读)” 你可以控制当背景冲洗脏页时,是否 InnoDB动态调整基于负载率冲洗。详情见 第15.6.3.6,“配置InnoDB缓冲池冲洗” 您可以微调方面 InnoDB缓冲池冲洗行为来提高性能。详情见 第15.6.3.7,“微调InnoDB缓冲池冲洗” 你可以配置 InnoDB保存当前缓冲池的状态后,重新启动服务器,避免长时间的热身。你也可以保存当前缓冲池的状态在服务器正在运行。详情见 第15.6.3.8,“保存和恢复缓冲池的状态”
InnoDB
在头部,一个子列表 “ 新 “ (或 “ 年轻 “ )页面访问最近 在尾部,一个子列表 “ 旧版 “ 页面访问最近少
3 / 8的缓冲池是致力于老子列表。 列表的中点是新的子列表尾遇到旧列表头的边界在哪里。 什么时候 InnoDB读取页面的缓冲池,它最初将在中点(老子头)。一个页面可以阅读因为它是一个用户指定的操作,如SQL查询的需要,或一部分 读前 操作自动执行的 InnoDB在旧的列表,访问一个网页让它 “ 年轻 “ ,将它移动到缓冲池的头(新的子列表的头)。如果页面阅读因为它是必需的,第一次访问时立即和页面由年轻。如果网页是由于提前读读书,第一接入并不立即发生(可能不会出现在所有页面之前拆迁)。 作为数据库操作,在缓冲池中不被访问的页 “ 年龄 “ 通过向列表的尾部。在新旧sublists年龄其他网页是新的网页。在旧的子列表页也年龄页插在中点。最终,一个页面,仍然未使用足够长的时间达到老子列表尾部,驱逐。
SELECT
InnoDB
InnoDB
指定的缓冲池的大小。如果缓冲池小,你有足够的内存,使缓冲池,大的可以提高性能,减少磁盘I/O需要查询访问 InnoDB表这个 innodb_buffer_pool_size选择是动态的,它允许您配置缓冲池大小不重启服务器。看到 第15.6.3.2,“配置InnoDB缓冲池大小” 更多信息 innodb_buffer_pool_chunk_size定义块的大小 InnoDB缓冲池大小调整操作。看到 第15.6.3.2,“配置InnoDB缓冲池大小” 更多信息 将缓冲池到用户指定的独立的区域,每个都有其自己的LRU列表和相关的数据结构,以减少内存争用期间并发读写操作。此选项仅当您设置生效 innodb_buffer_pool_size为值1GB以上。总规模为你指定的缓冲池中。最佳的效率,指定一个组合 innodb_buffer_pool_instances和 innodb_buffer_pool_size所以,每个缓冲池实例至少1千兆字节。看到 第15.6.3.3,“配置多个缓冲池的实例” 更多信息 指定的近似比例的缓冲池 InnoDB对于旧块子列表的使用。值的范围是5到95。默认值是37(即3/8的游泳池)。看到 第15.6.3.4,“缓冲池扫描耐” 更多信息 指定时间多久(MS)页面插入到老 子列表 要移动到新的子表的首次访问后留在那里。如果该值为0,页插入老子马上行动的新的子表的首次访问,无论多么快的访问发生后插入。如果该值大于0,页面停留在旧的列表,直到访问至少发生多少毫秒后首次访问。例如,一个价值1000引起页面停留在旧的子列表1秒才成为合格的移动到新的子列表的第一个访问后。 设置 innodb_old_blocks_time0防止大于一次性表扫描驱新列表页面只用于扫描。在一个页面中读取的行扫描访问多次快速连续,但页不使用后。如果 innodb_old_blocks_time设置的值大于时间过程的页面,页面仍然在 “ 旧版 “ 子列表和年龄到列表的尾部被迅速。这样,页面仅用于一次性扫描不到大量使用的页面在新的子表的损害。 innodb_old_blocks_time可以在运行时设置,你可以改变它的临时作业时,如表扫描和转储: SET GLOBAL innodb_old_blocks_time = 1000;
... perform queries that scan tables ...SET GLOBAL innodb_old_blocks_time = 0;这种策略不如果你的目的是应用 “ 热身 “ 缓冲池由其填充表格的内容。例如,基准测试往往执行扫描一个表或索引在服务器启动,因为数据通常是在缓冲池中正常使用一段时间后。在这种情况下,离开 innodb_old_blocks_time设置为0,至少在热身阶段完成。 看到 第15.6.3.4,“缓冲池扫描耐” 更多信息 使随机 读前 预取页面缓冲池技术。随机提前读是一种技术,预测当页面可能需要很快基于页面已经在缓冲池中,无论是为了在这些页面被阅读。 innodb_random_read_ahead默认是禁用的 指定是否动态调整冲洗速度 脏页 在缓冲池中基于工作量。刷新率动态调整的目的是为了避免爆发的I/O活动。默认启用。 影响算法和启发式算法的参数 脸红 对缓冲池的运行。主要感兴趣的I/O密集型工作负载的性能专家整定。它规定,每个缓冲池的实例,多远了缓冲池LRU列表 page_cleaner线扫描寻找 脏页 冲洗 innodb_max_dirty_pages_pct_lwm低水位标记代表的比例 脏页 在preflushing能够控制脏页率。值0禁用预冲洗行为完全。 指定保存表空间ID和网页ID的列表中的文件的名称 innodb_buffer_pool_dump_at_shutdown或 innodb_buffer_pool_dump_now看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 innodb_buffer_pool_dump_at_shutdown指定是否记录页面缓存在缓冲池,当MySQL服务器关闭,缩短 热身 在下一个过程的启动 看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 innodb_buffer_pool_load_at_startup指定,在MySQL服务器启动时,缓冲池自动 回暖 通过加载它在早些时候同一页。通常结合使用 innodb_buffer_pool_dump_at_shutdown看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 立即记录页面缓存在缓冲池。 看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 立即 热身 通过加载一组数据页面缓冲池,无需等待服务器重启。可以将缓存返回到已知状态在标杆有用,或准备好的MySQL服务器运行报告或维护查询后恢复其正常的工作量。与通常使用的 innodb_buffer_pool_dump_now看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 指定最近使用的每个缓冲池的读出并转储页的百分比。范围是1到100。 看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息 中断恢复过程 缓冲池 触发器 innodb_buffer_pool_load_at_startup或 innodb_buffer_pool_load_now看到 第15.6.3.8,“保存和恢复缓冲池的状态” 更多信息
InnoDB
innodb_buffer_pool_sizeinnodb_buffer_pool_chunk_size
innodb_buffer_pool_chunk_sizeinnodb_buffer_pool_instancesinnodb_buffer_pool_sizeinnodb_buffer_pool_chunk_sizeinnodb_buffer_pool_instancesinnodb_buffer_pool_chunk_sizeinnodb_buffer_pool_instances
innodb_buffer_pool_sizeinnodb_buffer_pool_instancesinnodb_buffer_pool_chunk_size
8Ginnodb_buffer_pool_sizeinnodb_buffer_pool_instances=16innodb_buffer_pool_chunk_size=128M
shell> mysqld --innodb_buffer_pool_size=8G --innodb_buffer_pool_instances=16
MySQL的> SELECT @@innodb_buffer_pool_size/1024/1024/1024;在这里,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,这是什么?
innodb_buffer_pool_sizeinnodb_buffer_pool_instancesinnodb_buffer_pool_chunk_size9Ginnodb_buffer_pool_instances=16innodb_buffer_pool_chunk_size=128Minnodb_buffer_pool_sizeinnodb_buffer_pool_chunk_sizeinnodb_buffer_pool_instances
内核> mysqld --innodb_buffer_pool_size=9G --innodb_buffer_pool_instances=16
MySQL的> SELECT @@innodb_buffer_pool_size/1024/1024/1024;------------------------------------------ | @ _ InnoDB缓冲池_ _ 1024 1024 1024大小/ / / | ------------------------------------------ | 10.000000000000 | ------------------------------------------
innodb_buffer_pool_chunk_size
shell> mysqld --innodb_buffer_pool_chunk_size=134217728
[mysqld] innodb_buffer_pool_chunk_size=134217728
innodb_buffer_pool_chunk_size
如果新的 innodb_buffer_pool_chunk_size价值* innodb_buffer_pool_instances比目前更大的缓冲池大小的缓冲池初始化时, innodb_buffer_pool_chunk_size截断 innodb_buffer_pool_size/ innodb_buffer_pool_instances例如,如果缓冲池的大小与初始化 2GB(2147483648字节), 四 缓冲池的情况下,一块大小 1GB(1073741824字节),块的大小是截断值等于 innodb_buffer_pool_size/ innodb_buffer_pool_instances,如下图所示: 内核> mysqld --innodb_buffer_pool_size=2147483648 --innodb_buffer_pool_instances=4--innodb_buffer_pool_chunk_size=1073741824;MySQL的> SELECT @@innodb_buffer_pool_size;--------------------------- | @ @ InnoDB缓冲池的大小_ _ _ | --------------------------- | 2147483648 | > --------------------------- MySQL SELECT @@innodb_buffer_pool_instances;-------------------------------- | @ @ innodb_buffer_pool_instances | -------------------------------- | 4 | -------------------------------- #块大小被设置为1GB(1073741824字节)启动但#截断innodb_buffer_pool_size / innodb_buffer_pool_instancesmysql > SELECT @@innodb_buffer_pool_chunk_size;--------------------------------- | @ @ innodb_buffer_pool_chunk_size | --------------------------------- | 536870912 | --------------------------------- 缓冲池的大小必须等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances。如果你改变 innodb_buffer_pool_chunk_size, innodb_buffer_pool_size自动调整到一个值等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances。调整发生时,缓冲池初始化。这种行为是下面的例子演示了: #缓冲池有128MB默认大小(134217728字节)MySQL > SELECT @@innodb_buffer_pool_size;--------------------------- | @ @ innodb_buffer_pool_size | --------------------------- | 134217728 | --------------------------- #块大小也128mb(134217728字节)MySQL > SELECT @@innodb_buffer_pool_chunk_size;--------------------------------- | @ @ innodb_buffer_pool_chunk_size | --------------------------------- | 134217728 | --------------------------------- #有一个单独的缓冲池instancemysql > SELECT @@innodb_buffer_pool_instances;+--------------------------------+| @@innodb_buffer_pool_instances |+--------------------------------+| 1 |+--------------------------------+# Chunk size is decreased by 1MB (1048576 bytes) at startup# (134217728 - 1048576 = 133169152):shell>mysqld --innodb_buffer_pool_chunk_size=133169152MySQL的> SELECT @@innodb_buffer_pool_chunk_size;--------------------------------- | @ @ innodb_buffer_pool_chunk_size | --------------------------------- | 133169152 | --------------------------------- #缓冲池的大小从134217728增加到266338304 #缓冲池大小自动调整到一个值,等于#或多个innodb_buffer_pool_chunk_size * innodb_buffer_pool_instancesmysql > SELECT @@innodb_buffer_pool_size;--------------------------- | @ @ InnoDB缓冲池的大小_ _ _ | --------------------------- | 266338304 | --------------------------- 这个例子演示了相同的行为,但多缓冲池的实例: # The buffer pool has a default size of 2GB (2147483648 bytes) mysql>
SELECT @@innodb_buffer_pool_size;+---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 2147483648 | +---------------------------+ # The chunk size is .5 GB (536870912 bytes) mysql>SELECT @@innodb_buffer_pool_chunk_size;+---------------------------------+ | @@innodb_buffer_pool_chunk_size | +---------------------------------+ | 536870912 | +---------------------------------+ # There are 4 buffer pool instances mysql>SELECT @@innodb_buffer_pool_instances;+--------------------------------+ | @@innodb_buffer_pool_instances | +--------------------------------+ | 4 | +--------------------------------+ # Chunk size is decreased by 1MB (1048576 bytes) at startup # (536870912 - 1048576 = 535822336): shell>mysqld --innodb_buffer_pool_chunk_size=535822336mysql>SELECT @@innodb_buffer_pool_chunk_size;+---------------------------------+ | @@innodb_buffer_pool_chunk_size | +---------------------------------+ | 535822336 | +---------------------------------+ # Buffer pool size increases from 2147483648 to 4286578688 # Buffer pool size is automatically adjusted to a value that is equal to # or a multiple of innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances mysql>SELECT @@innodb_buffer_pool_size;+---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 4286578688 | +---------------------------+护理时应更换 innodb_buffer_pool_chunk_size,为改变这个值可以增加缓冲池的大小,如上面的示例所示。在你改变 innodb_buffer_pool_chunk_size,计算的影响 innodb_buffer_pool_size为确保缓冲池的大小是可以接受的。
innodb_buffer_pool_sizeinnodb_buffer_pool_chunk_size
innodb_buffer_pool_sizeSET
MySQL的> SET GLOBAL innodb_buffer_pool_size=402653184;
InnoDB
Innodb_buffer_pool_resize_status
MySQL的> SHOW STATUS WHERE Variable_name='InnoDB_buffer_pool_resize_status';---------------------------------- name变量值_ ---------------------------------- | | | ---------------------------------- ---------------------------------- | InnoDB缓冲池_ _ _ _缩放调整状态| also other哈希表。一个多月以前评论
[Note] InnoDB: Resizing buffer pool from 134217728 to 4294967296. (unit=134217728) [Note] InnoDB: disabled adaptive hash index. [Note] InnoDB: buffer pool 0 : 31 chunks (253952 blocks) was added. [Note] InnoDB: buffer pool 0 : hash tables were resized. [Note] InnoDB: Resized hash tables at lock_sys, adaptive hash index, dictionary. [Note] InnoDB: completed to resize buffer pool from 134217728 to 4294967296. [Note] InnoDB: re-enabled adaptive hash index.
[Note] InnoDB: Resizing buffer pool from 4294967296 to 134217728. (unit=134217728) [Note] InnoDB: disabled adaptive hash index. [Note] InnoDB: buffer pool 0 : start to withdraw the last 253952 blocks. [Note] InnoDB: buffer pool 0 : withdrew 253952 blocks from free list. tried to relocate 0 pages. (253952/253952) [Note] InnoDB: buffer pool 0 : withdrawn target 253952 blocks. [Note] InnoDB: buffer pool 0 : 31 chunks (253952 blocks) was freed. [Note] InnoDB: buffer pool 0 : hash tables were resized. [Note] InnoDB: Resized hash tables at lock_sys, adaptive hash index, dictionary. [Note] InnoDB: completed to resize buffer pool from 4294967296 to 134217728. [Note] InnoDB: re-enabled adaptive hash index.
添加页面 chunks(块的大小被定义为 innodb_buffer_pool_chunk_size) 将哈希表、列表和指针在内存中使用新的地址 添加新的页面到自由列表
对缓冲池和退出页面(释放) 删除页面 chunks(块的大小被定义为 innodb_buffer_pool_chunk_size) 将哈希表、列表和指针在内存中使用新的地址
innodb_buffer_pool_instancesinnodb_buffer_pool_size
InnoDB
innodb_buffer_pool_instancesinnodb_buffer_pool_instancesinnodb_buffer_pool_size
InnoDB
InnoDB
3/8
InnoDB
InnoDBinnodb_old_blocks_pctinnodb_old_blocks_pct5
innodb_old_blocks_timeinnodb_old_blocks_time
innodb_old_blocks_pctinnodb_old_blocks_timemy.iniSYSTEM_VARIABLES_ADMIN
SHOW ENGINE INNODB STATUS
innodb_old_blocks_time
innodb_old_blocks_pctinnodb_old_blocks_pct=5
innodb_old_blocks_pctinnodb_old_blocks_pct=50
innodb_old_blocks_timeinnodb_old_blocks_pctinnodb_old_blocks_pct
InnoDB
InnoDBinnodb_read_ahead_threshold
innodb_read_ahead_thresholdinnodb_read_ahead_thresholdinnodb_read_ahead_thresholdInnoDBSET
GLOBALSYSTEM_VARIABLES_ADMIN
InnoDBinnodb_random_read_ahead
SHOW ENGINE INNODB STATUS
innodb_random_read_ahead
InnoDB
InnoDBinnodb_max_dirty_pages_pct_lwminnodb_max_dirty_pages_pctinnodb_max_dirty_pages_pct
InnoDB
InnoDBinnodb_max_dirty_pages_pct
InnoDB
innodb_adaptive_flushinginnodb_adaptive_flushingmy.cnfSET GLOBALSYSTEM_VARIABLES_ADMIN
InnoDB
InnoDB
innodb_flush_neighborsinnodb_lru_scan_depthInnoDB
InnoDB
innodb_adaptive_flushing
innodb_adaptive_flushinginnodb_io_capacityinnodb_max_dirty_pages_pct
InnoDBinnodb_adaptive_flushing_lwmInnoDBinnodb_adaptive_flushing
InnoDBinnodb_io_capacityinnodb_io_capacity_max
InnoDBinnodb_max_dirty_pages_pctinnodb_max_dirty_pages_pct
innodb_max_dirty_pages_pct
innodb_max_dirty_pages_pct_lwminnodb_max_dirty_pages_pctinnodb_max_dirty_pages_pct_lwm=0
innodb_flushing_avg_loopsinnodb_flushing_avg_loopsInnoDBinnodb_max_dirty_pages_pct
innodb_log_file_sizeinnodb_flushing_avg_loopsinnodb_flushing_avg_loops
InnoDBinnodb_buffer_pool_dump_pct
InnoDBINNODB_BUFFER_PAGE_LRUib_buffer_poolinnodb_buffer_pool_filename
innodb_buffer_pool_dump_pct
SET GLOBAL innodb_buffer_pool_dump_pct=40;
innodb_buffer_pool_dump_pct
[mysqld]innodb_buffer_pool_dump_pct=40
innodb_buffer_pool_dump_pct
SET GLOBAL innodb_buffer_pool_dump_at_shutdown=ON;
innodb_buffer_pool_dump_at_shutdown
--innodb_buffer_pool_load_at_startup
mysqld --innodb_buffer_pool_load_at_startup=ON;
SET GLOBAL innodb_buffer_pool_dump_now=ON;
SET GLOBAL innodb_buffer_pool_load_now=ON;
SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status';
SHOW STATUS LIKE 'Innodb_buffer_pool_load_status';
stage/innodb/buffer pool load
使 stage/innodb/buffer pool load工具: MySQL的> UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'WHERE NAME LIKE 'stage/innodb/buffer%';使舞台事件消费表,其中包括 events_stages_current, events_stages_history,和 events_stages_history_longMySQL的> UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'WHERE NAME LIKE '%stages%';把当前的缓冲池的状态使 innodb_buffer_pool_dump_nowMySQL的> SET GLOBAL innodb_buffer_pool_dump_now=ON;检查缓冲池堆状况以确保操作完成。 mysql>
SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status'\G*************************** 1. row *************************** Variable_name: Innodb_buffer_pool_dump_status Value: Buffer pool(s) dump completed at 150202 16:38:58通过启用缓冲池的负荷 innodb_buffer_pool_load_now: MySQL的> SET GLOBAL innodb_buffer_pool_load_now=ON;通过查询性能模式检查缓冲池负荷运行现状 events_stages_currentTable .the work_completed 列显示了缓冲池页面数载。这个 WORK_ESTIMATED柱提供剩余工作的一个估计,在页。 MySQL的> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_current;------------------------------- ---------------- ---------------- | event_name | work_completed | work_estimated | ------------------------------- ---------------- ---------------- |阶段/ InnoDB /缓冲池的负荷| 5353 | 7167 | ------------------------------- ---------------- ---------------- 这个 events_stages_current如果缓冲池负荷操作完成表格返回空集。在这种情况下,你可以检查 events_stages_history表观为完成事件数据。例如: MySQL的> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATEDFROM performance_schema.events_stages_history;------------------------------- ---------------- ---------------- | event_name | work_completed | work_estimated | ------------------------------- ---------------- ---------------- |阶段/ InnoDB /缓冲池的负荷| 7167 | 7167 | ------------------------------- ---------------- ----------------
innodb_buffer_pool_load_at_startup
InnoDBSHOW
ENGINE INNODB STATUSBUFFER POOL AND
MEMORY
---------------------- BUFFER POOL AND MEMORY ---------------------- Total large memory allocated 2198863872 Dictionary memory allocated 776332 Buffer pool size 131072 Free buffers 124908 Database pages 5720 Old database pages 2071 Modified db pages 910 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 4, not young 0 0.10 youngs/s, 0.00 non-youngs/s Pages read 197, created 5523, written 5060 0.00 reads/s, 190.89 creates/s, 244.94 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 5720, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0]
InnoDB
InnoDB
InnoDB | |
这个 youngs/s度量只涉及旧的页面。它是基于一些访问网页而不是页面的数量。可以有多个访问一个给定的页面,所有这些都算。如果你看的很低 年轻人的 当没有发生大的扫描值,你可能需要减少延迟时间或增加使用旧表缓冲池的百分比。含量的增加使老子更大,在移动到尾和被采取的子列表更长的页面,所以。这增加了页面被访问一次,让年轻的可能性。 这个 non-youngs/s度量只涉及旧的页面。它是基于一些访问网页而不是页面的数量。可以有多个访问一个给定的页面,所有这些都算。如果你没有看到很多 非弹性的 当你做的大表扫描(和许多 youngs/s),增加延时值 这个 young-making访问率占所有缓冲池页面,不只是访问在老子列表页。这个 年轻的制作 率和 not率通常不总计达整体缓冲池命中率。页面点击在老子导致页面移动到新的子列表,但页面点击在新页面的列表,因为只有他们是从头部一定距离移动到列表的头。 not (young-making rate)的平均命中率,页面访问没有导致页面年轻由于定义的延迟 innodb_old_blocks_time没有得到满足,或因在新的子列表,不在页面移动到头部的结果页面点击。这个比率占访问所有缓冲池页面,不只是访问在老子列表页。
InnoDBINNODB_BUFFER_POOL_STATSINNODB_BUFFER_POOL_STATS
INSERTUPDATEDELETEInnoDB
InnoDBinnodb_change_bufferinginnodb_change_buffering
innodb_change_buffering
all默认值:缓冲器插入、删除标记操作和清洗。 none没有缓冲区的任何操作。 inserts缓冲器插入操作 deletes缓冲区删除标记操作 changes缓冲区插入和删除操作都标记。 purges缓冲区的物理删除操作发生在后台。
innodb_change_bufferingmy.iniSET GLOBALSYSTEM_VARIABLES_ADMIN
innodb_change_buffer_max_sizeinnodb_change_buffer_max_size
innodb_change_buffer_max_size
innodb_change_buffer_max_size
innodb_change_buffer_max_size
InnoDBInnoDB
InnoDB
innodb_thread_concurrencyinnodb_thread_sleep_delay
innodb_adaptive_max_sleep_delayinnodb_thread_sleep_delayinnodb_thread_sleep_delay
innodb_thread_concurrencyinnodb_thread_concurrency
InnoDBinnodb_thread_concurrencyinnodb_thread_sleep_delay
innodb_thread_concurrencyInnoDBinnodb_thread_concurrencyInnoDB
innodb_thread_concurrencyInnoDBinnodb_thread_concurrencyinnodb_concurrency_tickets
InnoDBinnodb_adaptive_hash_index
InnoDBinnodb_read_io_threadsinnodb_write_io_threadsmy.ini1-64
InnoDBInnoDBinnodb_read_io_threadsinnodb_read_io_threads
InnoDB
InnoDB
InnoDBinnodb_use_native_aioInnoDB
InnoDBnnInnoDBinnodb_read_io_threadsinnodb_write_io_threads
InnoDB
SHOW ENGINE INNODB STATUS\G
InnoDBinnodb_use_native_aio=0tmpdirtmpfs
innodb_io_capacityinnodb_io_capacity
innodb_io_capacity
innodb_io_capacityinnodb_io_capacityinnodb_io_capacity
my.cnfSET GLOBALSYSTEM_VARIABLES_ADMIN
innodb_flush_syncinnodb_io_capacityinnodb_flush_sync
InnoDBinnodb_purge_threads
innodb_spin_wait_delayinnodb_spin_wait_delay=0
innodb_spin_wait_delaymy.cnfSET GLOBAL
innodb_spin_wait_delay=delaydelaySYSTEM_VARIABLES_ADMIN
innodb_purge_threadsinnodb_purge_threads
innodb_purge_batch_size
InnoDB
你可以使用 innodb_stats_auto_recalc配置选项控制是否自动更新后的统计表的实质性变化。 你可以使用 STATS_PERSISTENT, stats_auto_recalc ,和 STATS_SAMPLE_PAGES保险条款 CREATE TABLE和 ALTER TABLE报表配置单独的表,优化器统计。 你可以查询优化器的统计数据 mysql.innodb_table_stats和 mysql.innodb _ index stats _ 表 你可以查看 last_update列的 mysql.innodb _ _ stats桌 和 mysql.innodb_index_stats当看到统计表的最后更新。 你可以手动修改 mysql.innodb_table_stats和 mysql.innodb _ index stats _ 表强制一个特定的查询优化计划或测试替代方案不需要修改数据库。
innodb_stats_persistent=ON
ANALYZE TABLEANALYZE TABLE
innodb_stats_persistent=ONSTATS_PERSISTENT=1innodb_stats_persistent
mysql.innodb_table_stats
ALTER TABLE
tbl_name STATS_PERSISTENT=0
innodb_stats_auto_recalcCREATE TABLEALTER TABLEinnodb_stats_auto_recalc
innodb_stats_auto_recalcANALYZE TABLE
innodb_stats_auto_recalcANALYZE TABLEinnodb_stats_auto_recalc
innodb_stats_auto_recalcANALYZE TABLE
innodb_stats_persistentinnodb_stats_auto_recalcinnodb_stats_persistent_sample_pagesSTATS_AUTO_RECALCCREATE TABLEALTER TABLE
STATS_PERSISTENT指定是否启用 持续的统计 对于一个 InnoDBTable .the value 默认 导致持续统计表是由设置 innodb_stats_persistent配置选项。的价值 一 使表持续的统计,而价值 0关闭此功能。使持续统计通过后 创建表 或 ALTER TABLE声明的问题 ANALYZE TABLE表计算统计,加载后有代表性的数据到表中。 STATS_AUTO_RECALC指定是否自动重新计算 持续的统计 对于一个 InnoDBTable .the value 默认 导致持续统计表是由设置 innodb_stats_auto_recalc配置选项。的价值 一 原因是时重新计算统计表中的数据10%已经改变了。的价值 0防止此表的自动重新计算;使用此设置问题 ANALYZE TABLE表重新计算统计后的表格作出实质性的变化。 STATS_SAMPLE_PAGES指定样本估计基数和其他统计索引列的索引页面的数量,如计算 ANALYZE TABLE
CREATE TABLE
CREATE TABLE `t1` (`id` int(8) NOT NULL auto_increment,`data` varchar(255),`date` datetime,PRIMARY KEY (`id`),INDEX `DATE_IX` (`date`)) ENGINE=InnoDB, STATS_PERSISTENT=1, STATS_AUTO_RECALC=1, STATS_SAMPLE_PAGES=25;
ANALYZE
TABLE
innodb_stats_persistent_sample_pages
innodb_stats_persistent_sample_pages
统计不够准确和优化选择次优方案 ,如图所示 EXPLAIN输出。统计数据的准确性可以通过比较某一指标实际基数检查(如返回运行 SELECT DISTINCT在索引列)提供的估计 mysql.innodb _ index stats _ 持续的统计表 如果确定统计不够准确,价值 innodb_stats_persistent_sample_pages应该增加到统计估计是足够准确的。增加的 innodb_stats_persistent_sample_pages太多了,但是,可能导致 ANALYZE TABLE运行缓慢 ANALYZE TABLE太慢了 。在这种情况下 innodb_stats_persistent_sample_pages应该减少直到 ANALYZE TABLE执行时间是可以接受的。减少的价值太多,但是,可能会导致第一个问题不准确的统计数据和次优的查询执行计划。 如果一个平衡不能实现之间的准确的统计 ANALYZE TABLE执行时,考虑减少索引的表中的列或限制分区数量减少 ANALYZE TABLE复杂性.表中的主键列的数目也是很重要的考虑,因为主键列附加到每个非唯一索引。
InnoDBREAD UNCOMMITTEDinnodb_stats_include_delete_marked
innodb_stats_include_delete_markedANALYZE TABLE
innodb_stats_include_delete_marked
mysqlinnodb_index_stats
database_name | |
table_name | |
last_update | InnoDB |
n_rows | |
clustered_index_size | |
sum_of_other_index_sizes |
database_name | |
table_name | |
index_name | |
last_update | InnoDB |
stat_name | stat_value |
stat_value | stat_name |
sample_size | stat_value |
stat_description | stat_name |
innodb_table_statslast_update
mysql> SELECT * FROM innodb_table_stats \G
*************************** 1. row ***************************
database_name: sakila
table_name: actor
last_update: 2014-05-28 16:16:44
n_rows: 200
clustered_index_size: 1
sum_of_other_index_sizes: 1
...MySQL的> SELECT * FROM innodb_index_stats \G*************************** 1。行*************************** database_name:sakila table_name:演员index_name:主要last_update:2014-05-28 16:16:44 stat_name:n_diff_pfx01 stat_value:200 sample_size:1…
innodb_table_statsFLUSH TABLE
tbl_name
innodb_table_statsANALYZE TABLE
innodb_table_stats
t1bd
f
CREATE TABLE t1 (a INT, b INT, c INT, d INT, e INT, f INT,PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f)) ENGINE=INNODB;
mysql> SELECT * FROM t1;
+---+---+------+------+------+------+
| a | b | c | d | e | f |
+---+---+------+------+------+------+
| 1 | 1 | 10 | 11 | 100 | 101 |
| 1 | 2 | 10 | 11 | 200 | 102 |
| 1 | 3 | 10 | 11 | 100 | 103 |
| 1 | 4 | 10 | 12 | 200 | 104 |
| 1 | 5 | 10 | 12 | 100 | 105 |
+---+---+------+------+------+------+
ANALYZE TABLEinnodb_stats_auto_recalc
MySQL的> ANALYZE TABLE t1;--------- --------- ---------- ---------- |表| OP | msg_type | msg_text | --------- --------- ---------- ---------- | test.t1 |分析|状态|好| --------- --------- ---------- ----------
t12014-03-14 14:36:341
mysql> SELECT * FROM mysql.innodb_table_stats WHERE table_name like 't1'\G
*************************** 1. row ***************************
database_name: test
table_name: t1
last_update: 2014-03-14 14:36:34
n_rows: 5
clustered_index_size: 1
sum_of_other_index_sizes: 2
innodb_index_statsstat_name
mysql>SELECT index_name, stat_name, stat_value, stat_descriptionFROM mysql.innodb_index_stats WHERE table_name like 't1';+------------+--------------+------------+-----------------------------------+ | index_name | stat_name | stat_value | stat_description | +------------+--------------+------------+-----------------------------------+ | PRIMARY | n_diff_pfx01 | 1 | a | | PRIMARY | n_diff_pfx02 | 5 | a,b | | PRIMARY | n_leaf_pages | 1 | Number of leaf pages in the index | | PRIMARY | size | 1 | Number of pages in the index | | i1 | n_diff_pfx01 | 1 | c | | i1 | n_diff_pfx02 | 2 | c,d | | i1 | n_diff_pfx03 | 2 | c,d,a | | i1 | n_diff_pfx04 | 5 | c,d,a,b | | i1 | n_leaf_pages | 1 | Number of leaf pages in the index | | i1 | size | 1 | Number of pages in the index | | i2uniq | n_diff_pfx01 | 2 | e | | i2uniq | n_diff_pfx02 | 5 | e,f | | i2uniq | n_leaf_pages | 1 | Number of leaf pages in the index | | i2uniq | size | 1 | Number of pages in the index | +------------+--------------+------------+-----------------------------------+
stat_name
size:where 国家_ name size,的 _状态的价值 列显示在索引中的总页数。 n_leaf_pages:where 国家_ name n_leaf_pages,的 _状态的价值 列显示在索引叶子页的数量。 n_diff_pfxNN:在哪里 国家_ name n_diff_pfx01,的 _状态的价值 列显示在索引中的第一列的不同值的个数。哪里 stat_name=n _ _ pfx02 diff ,的 stat_value列显示在索引中的第一两列的不同值的个数,等等。此外,在 国家_ name n_diff_pfxNN,的 _状态描述 列显示一个逗号分隔的列表的索引的列数。
n_diff_pfxNNt1bdf
CREATE TABLE t1 ( a INT, b INT, c INT, d INT, e INT, f INT, PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f)) ENGINE=INNODB;
mysql> SELECT * FROM t1;
+---+---+------+------+------+------+
| a | b | c | d | e | f |
+---+---+------+------+------+------+
| 1 | 1 | 10 | 11 | 100 | 101 |
| 1 | 2 | 10 | 11 | 200 | 102 |
| 1 | 3 | 10 | 11 | 100 | 103 |
| 1 | 4 | 10 | 12 | 200 | 104 |
| 1 | 5 | 10 | 12 | 100 | 105 |
+---+---+------+------+------+------+
index_namestat_valuestat_name LIKE 'n_diff%'
MySQL的> SELECT index_name, stat_name, stat_value, stat_descriptionFROM mysql.innodb_index_statsWHERE table_name like 't1' AND stat_name LIKE 'n_diff%';————| ----------------- Enbrel ------- ----------------- Enbrel -------指标_ name name | _ |状态状态状态_价值| _描述| ----------------- Enbrel -------——----------------- Enbrel -------将|小学| N _差异_ pfx01 | | A 1 N | |小学| _差异_ pfx02 | 5 | A,B | | |(N _差异_ pfx01 | 1 | | | | C(n _差异_ pfx02 | 2 | C,D(N | | | _差异_ pfx03 | 2 | C,D,A(N | | | _差异_ pfx04 | 5 | C,D,A,B | | i2uniq | N _差异_ pfx01 | 2 |电子| | i2uniq | N _差异_ pfx02 | 5 | E、F——----------------- Enbrel -------将| ----------------- Enbrel -------
PRIMARY
InnoDB
哪里 index_name=首要 和 stat_name=n_diff_pfx01 ,的 stat_value是 一 ,这表明有索引的第一列一个不同的值(柱 a)。在列中不同值的个数 一 由柱查看数据确认 a表 T1 ,其中有一个不同的值( 1)。计算列( 一 )所示 stat_description结果集的列 哪里 index_name=首要 和 stat_name=n _ _ pfx02 diff ,的 stat_value是 五 ,这表明在两列索引五种不同的价值观( a,b)。在列中不同值的个数 一 和 b通过查看数据证实在列 一 和 b表 T1 ,其中有五个不同的值:( 1,1),( 1,2 ),( 1,3),( 1 )和( 1,5)。计算列( A,B )表现在 stat_description结果集的列
i1c,dInnoDBc,d
哪里 index_name=1 和 stat_name=n_diff_pfx01 ,的 stat_value是 一 ,这表明有索引的第一列一个不同的值(柱 c)。在列中不同值的个数 C 由柱查看数据确认 c表 T1 ,其中有一个不同的值:( 10)。计算列( C )所示 stat_description结果集的列 哪里 index_name=1 和 stat_name=n _ _ pfx02 diff ,的 stat_value是 二 ,这表明在指数前两列的两个不同的值( c,d)。在列中不同值的个数 C 一个 d通过查看数据证实在列 C 和 d表 T1 ,其中有两个不同的值:( 10,11)和( 10、12 )。计算列( c,d)表现在 _状态描述 结果集的列 哪里 index_name=1 和 stat_name=n_diff_pfx03 ,的 stat_value是 二 ,这表明在索引列第3 2个不同的值( c,d,a)。在列中不同值的个数 C , d,和 一 由柱查看数据确认 c, D ,和 a表 T1 ,其中有两个不同的值:( 10,11,1)和( 10,12,1 )。计算列( c,d,a)表现在 _状态描述 结果集的列 哪里 index_name=1 和 stat_name=n _ _ pfx04 diff ,的 stat_value是 五 ,这表明在指数的四列五个不同的值( c,d,a,b)。在列中不同值的个数 C , d, 一 和 b通过查看数据证实在列 C , d, 一 ,和 b表 T1 ,其中有五个不同的值:( 10,11,1,1),( 10,11,1,2 ),( 10,11,1,3),( 10,12,1,4 )和( 10,12,1,5)。计算列( C,D,A,B )表现在 stat_description结果集的列
i2uniq
哪里 index_name=i2uniq 和 stat_name=n_diff_pfx01 ,的 stat_value是 二 ,这表明有索引的第一列的两个不同的值(柱 e)。在列中不同值的个数 E 由柱查看数据确认 e表 T1 ,其中有两个不同的值:( 100)和( 二百 )。计算列( e)所示 _状态描述 结果集的列 哪里 index_name=i2uniq 和 stat_name=n _ _ pfx02 diff ,的 stat_value是 五 ,这表明在两列索引五种不同的价值观( e,f)。在列中不同值的个数 E 和 f通过查看数据证实在列 E 和 f表 T1 ,其中有五个不同的值:( 100,101),( 二十万零一百零二 ),( 100,103),( 二十万零一百零四 和 100,105)。计算列( E、F )表现在 stat_description结果集的列
innodb_index_statst1
mysql>SELECT SUM(stat_value) pages, index_name,SUM(stat_value)*@@innodb_page_size sizeFROM mysql.innodb_index_stats WHERE table_name='t1'AND stat_name = 'size' GROUP BY index_name;+-------+------------+-------+ | pages | index_name | size | +-------+------------+-------+ | 1 | PRIMARY | 16384 | | 1 | i1 | 16384 | | 1 | i2uniq | 16384 | +-------+------------+-------+
WHERE
mysql>SELECT SUM(stat_value) pages, index_name,SUM(stat_value)*@@innodb_page_size sizeFROM mysql.innodb_index_stats WHERE table_name like 't1#P%'AND stat_name = 'size' GROUP BY index_name;
innodb_stats_persistent=OFFSTATS_PERSISTENT=0
innodb_stats_persistent
优化器统计信息更新
运行 SHOW TABLE STATUS, SHOW INDEX,或查询 INFORMATION_SCHEMA.TABLES或 INFORMATION_SCHEMA.STATISTICS表的 innodb_stats_on_metadata启用选项 设置为默认 innodb_stats_on_metadata是 关闭 。有可能 innodb_stats_on_metadata可以减少,有大量的表或索引架构的访问速度,减少查询执行计划,包括稳定性 InnoDB 表 innodb_stats_on_metadata使用一个全局配置 SET声明 SET GLOBAL innodb_stats_on_metadata=ON
笔记 innodb_stats_on_metadata只适用于当优化器 统计 被配置为非持久性(当 innodb_stats_persistent是的 开始 MySQL 客户端与 --auto-rehash启用选项,这是默认的。这个 auto-rehash选择原因 InnoDB 表被打开,而打开的表操作造成统计数据重新计算。 为了提高启动时间的 MySQL 客户端和更新统计信息,你可以关闭 auto-rehash使用 --disable-auto-rehash选项这个 auto-rehash功能使自动数据库、表名完成,和互动的用户名称。 表第一次打开 InnoDB检测到1/16台已自上次统计更新修改。
配置采样的页面数
InnoDB
innodb_stats_transient_sample_pagesinnodb_stats_transient_sample_pages
innodb_stats_transient_sample_pagesinnodb_stats_persistent=0
小的值如1或2可以导致不准确的估计数。 增加 innodb_stats_transient_sample_pages值可能需要更多的磁盘读取。值远大于8(如100),会导致它需要打开一个表或执行时间显著放缓 显示表状态 优化器可能会选择基于索引的选择性不同的估计不同的查询计划。
innodb_stats_transient_sample_pagesANALYZE TABLEANALYZE TABLE
innodb_stats_transient_sample_pages
ANALYZE TABLE
页面抽取的样本数,定义为 innodb_stats_persistent_sample_pages索引的列表中的数 分区的数量。如果表没有分区,分区的数量是1。
ANALYZE TABLE
innodb_stats_persistent_sample_pages
ANALYZE TABLE
innodb_stats_persistent_sample_pagesCREATE TABLEALTER TABLE
innodb_stats_persistent=OFFinnodb_stats_transient_sample_pages
ANALYZE
TABLE
ANALYZE TABLE
或(n _样品×(n _ cols _在_唯一_ N _ cols _ _ _唯一不在N中_ _ cols _ _ PK(1×N _ _唯一不_)×N _兼职)
n_sample是页面抽取的样本数(定义 innodb_stats_persistent_sample_pages) n_cols_in_uniq_i是所有唯一索引的所有列的总数(不包括主键列) n_cols_in_non_uniq_i是在所有的非唯一索引的所有列的总数 n_cols_in_pk是主键中的列数(如果没有定义一个主关键字, InnoDB 创建一个单列主键内部) n_non_uniq_i表中的非唯一索引的数量 n_part是分区的数量。如果没有定义分区表被认为是一个分区。
t
创建表(一个int,int b INT,C,D E F int,int,int,int,int g,h,主键(A,B),(C,D i1uniq独特的关键),关键i2nonuniq(E,F),关键i3nonuniq(G,H));
mysql.innodb_index_statsn_diff_pfx%b
InnoDB
mysql>SELECT index_name, stat_name, stat_descriptionFROM mysql.innodb_index_stats WHEREdatabase_name='test' ANDtable_name='t' ANDstat_name like 'n_diff_pfx%';+------------+--------------+------------------+ | index_name | stat_name | stat_description | +------------+--------------+------------------+ | PRIMARY | n_diff_pfx01 | a | | PRIMARY | n_diff_pfx02 | a,b | | i1uniq | n_diff_pfx01 | c | | i1uniq | n_diff_pfx02 | c,d | | i2nonuniq | n_diff_pfx01 | e | | i2nonuniq | n_diff_pfx02 | e,f | | i2nonuniq | n_diff_pfx03 | e,f,a | | i2nonuniq | n_diff_pfx04 | e,f,a,b | | i3nonuniq | n_diff_pfx01 | g | | i3nonuniq | n_diff_pfx02 | g,h | | i3nonuniq | n_diff_pfx03 | g,h,a | | i3nonuniq | n_diff_pfx04 | g,h,a,b | +------------+--------------+------------------+
n_cols_in_uniq_i在所有的唯一指标,不包括主键列的所有列的总数是2( C 和 d) n_cols_in_non_uniq_i,在所有非唯一索引的所有列的总数是4( E , f, G 和 h) n_cols_in_pk,主键中的列数,2( 一 和 b) n_non_uniq_i,表中的非唯一索引的数量,是2( i2nonuniq 和 i3nonuniq)) n_part,分区的数量,是1
innodb_stats_persistent_sample_pages20innodb_page_size=16384), you can then estimate that 20 * 12 * 16384t
MiB
MERGE_THRESHOLDMERGE_THRESHOLDUPDATEMERGE_THRESHOLD
MERGE_THRESHOLDMERGE_THRESHOLD
MERGE_THRESHOLDMERGE_THRESHOLD
设置一个表格merge_threshold
MERGE_THRESHOLDtable_optionCREATE TABLE
CREATE TABLE t1 ( id INT, KEY id_index (id)) COMMENT='MERGE_THRESHOLD=45';
MERGE_THRESHOLDtable_optionALTER TABLE
CREATE TABLE t1 ( id INT, KEY id_index (id));ALTER TABLE t1 COMMENT='MERGE_THRESHOLD=40';
设置个人指标merge_threshold
MERGE_THRESHOLDindex_optionCREATE TABLEALTER TABLECREATE INDEX
设置 MERGE_THRESHOLD一个索引的使用 CREATE TABLE: CREATE TABLE t1 ( id INT, KEY id_index (id) COMMENT 'MERGE_THRESHOLD=40');
设置 MERGE_THRESHOLD一个索引的使用 ALTER TABLE: CREATE TABLE t1 ( id INT, KEY id_index (id));ALTER TABLE t1 DROP KEY id_index;ALTER TABLE t1 ADD KEY id_index (id) COMMENT 'MERGE_THRESHOLD=40';
设置 MERGE_THRESHOLD一个索引的使用 CREATE INDEX: CREATE TABLE t1 (id INT);CREATE INDEX id_index ON t1 (id) COMMENT 'MERGE_THRESHOLD=40';
MERGE_THRESHOLDInnoDBMERGE_THRESHOLDMERGE_THRESHOLD
查询一个指数的merge_threshold价值
MERGE_THRESHOLDINNODB_INDEXES
MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_INDEXES WHERE NAME='id_index' \G*************************** 1。行*************************** index_id:91名称:id_index table_id:68型:0:1:4 n_fields page_no空间:57merge_threshold:40
SHOW CREATE TABLEtable_option
mysql> SHOW CREATE TABLE t2 \G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`id` int(11) DEFAULT NULL,
KEY `id_index` (`id`) COMMENT 'MERGE_THRESHOLD=40'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
MERGE_THRESHOLDMERGE_THRESHOLDMERGE_THRESHOLD=50
SHOW INDEXindex_option
mysql> SHOW INDEX FROM t2 \G
*************************** 1. row ***************************
Table: t2
Non_unique: 1
Key_name: id_index
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment: MERGE_THRESHOLD=40
测量merge_threshold设置的效果
INNODB_METRICS
mysql>SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICSWHERE NAME like '%index_page_merge%';+-----------------------------+----------------------------------------+ | NAME | COMMENT | +-----------------------------+----------------------------------------+ | index_page_merge_attempts | Number of index page merge attempts | | index_page_merge_successful | Number of successful index page merges | +-----------------------------+----------------------------------------+
MERGE_THRESHOLD
一个较小的数页合并的尝试和成功的页面合并 类似的一些尝试和成功的页页合并的合并
MERGE_THRESHOLD
INNODB_METRICS
innodb_dedicated_server
表15.5自动配置缓冲池大小 检测服务器内存 缓冲池大小 < 1G 128mib(the innodb_buffer_pool_size默认) <= 4G 检测服务器内存×0.5 > 4G 检测服务器内存×0.75 表15.6自动配置日志文件大小 检测服务器内存 日志文件大小 < 1GB 48mib(的 innodb_log_file_size默认) <= 4GB 128mib <= 8GB 512mib <= 16GB 1024mib > 16GB 2048mib 将冲洗方法 O_DIRECT_NO_FSYNC什么时候 innodb_dedicated_server是的。如果 O _ _没有直接_ fsync 默认设置是不可用的, innodb_flush_method设置
stderr
[Warning] [000000] InnoDB: Option innodb_dedicated_server is ignored for innodb_buffer_pool_size because innodb_buffer_pool_size=134217728 is specified explicitly.
innodb_dedicated_serverinnodb_buffer_pool_sizeinnodb_log_file_sizeinnodb_flush_method
InnoDB
InnoDB
增加InnoDB SYSTEM表空间的大小
InnoDBInnoDBinnodb_autoextend_increment
关闭MySQL服务器。 如果之前的最后一个数据文件的关键字定义 autoextend, change its definition to use a fixed size, based on how large it has actually grown. Check the size of the data file, round it down to the closest multiple of 1024 × 1024 bytes (= 1MB), and specify this rounded size explicitly ininnodb_data_file_path添加一个新的数据文件结束 innodb_data_file_path,选择使文件自动扩展。只有最后一个数据文件中 innodb_data_file_path可以被指定为自动扩展。 再次启动MySQL服务器。
ibdata1
innodb_data_home_dir =innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
InnoDB
降低InnoDB SYSTEM表空间的大小
使用 mysqldump 把你所有的 InnoDB表,包括 InnoDB 位于MySQL数据库表。 mysql>
SELECT TABLE_NAME from INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='mysql' and ENGINE='InnoDB';+---------------------------+ | TABLE_NAME | +---------------------------+ | columns_priv | | component | | db | | default_roles | | engine_cost | | func | | global_grants | | gtid_executed | | help_category | | help_keyword | | help_relation | | help_topic | | innodb_dynamic_metadata | | innodb_index_stats | | innodb_table_stats | | plugin | | procs_priv | | proxies_priv | | role_edges | | server_cost | | servers | | slave_master_info | | slave_relay_log_info | | slave_worker_info | | tables_priv | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | | user | +---------------------------+停止服务器 删除所有现有的表空间文件( *.ibd),including the ibdata 和 ib_log文件不要忘记删除 鸡传染性法氏囊病* 对于位于MySQL数据库表文件。 一个新的表格 重新启动服务器 进口转储文件
InnoDBInnoDB
InnoDB
停止MySQL服务器,确保关闭时没有错误。 编辑 my.cnf更改日志文件配置。更改日志文件的大小,配置 innodb_log_file_size。增加日志文件的数量,配置 innodb_log_files_in_group再次启动MySQL服务器。
InnoDBinnodb_log_file_size
InnoDB
mysql--memlockroot
配置Linux和UNIX系统的磁盘分区
当你创建一个新的数据文件,指定关键字 newraw对于数据文件大小后立即 innodb_data_file_path选项分区必须至少为你指定的大小一样大。注意:1MB InnoDB 1024×1024字节,而1MB的磁盘规格通常是1000000字节。 [mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
重新启动服务器 InnoDB注意事项 newraw 关键词并初始化新的分区。然而,不创造或改变任何 InnoDB表吗。否则,当你下次重新启动服务器, InnoDB 重新初始化分区和更改了。(作为一种安全措施 InnoDB防止用户修改数据时,任何分区 newraw 是指定的。) 后 InnoDB初始化新的分区,停止服务器,改变 newraw 在数据文件规范 raw: [mysqld]innodb_data_home_dir=innodb_data_file_path=/dev/hdd1:3Graw;/dev/hdd2:2Graw
重新启动服务器 InnoDB现在允许进行更改
在Windows分配磁盘分区
innodb_data_file_path
当你创建一个新的数据文件,指定关键字 newraw对于数据文件大小后立即 innodb_data_file_path选项: [mysqld]innodb_data_home_dir=innodb_data_file_path=//./D::10Gnewraw
这个 //./对应于Windows语法 \ \ \ 访问物理驱动器。在上面的例子中, D:是分区的盘符 重新启动服务器 InnoDB注意事项 newraw 关键词并初始化新的分区。 后 InnoDB初始化新的分区,停止服务器,改变 newraw 在数据文件规范 raw: [mysqld]innodb_data_home_dir=innodb_data_file_path=//./D::10Graw
重新启动服务器 InnoDB现在允许进行更改
InnoDBInnoDBInnoDB.ibd.ibdinnodb_file_per_table
文件表的表空间的优势
你可以回收磁盘空间时截断或删除一个表存储在一个文件中的每个表tablepace。截断或删除表存储在共享 系统片 创建自由空间在SYSTEM表空间的数据文件( ibdata文件 )只能用于新 InnoDB数据 同样,一个表复制 ALTER TABLE操作台位于共享表空间可以增加表空间使用的空间量。这样的操作可能需要在表格和索引数据的多少额外的空间。为表复制所需的额外空间 ALTER TABLE操作不回操作系统是每个表的表空间文件发布。 这个 TRUNCATE TABLE运行更快,存储在每台tablepaces表运行时文件。 你可以存储在不同的存储设备特定的表、I/O优化、空间管理、或备份的目的使用的语法指定每个表的位置 CREATE TABLE ... DATA DIRECTORY =absolute_path_to_directory,解释 第15.7.5”创建文件,每个表的表空间在数据目录” 你可以运行 OPTIMIZE TABLE紧凑型或创建一个文件,每个表的表空间。当你运行一个 OPTIMIZE TABLE, InnoDB 创建一个新的 .ibd一个临时文件名的文件,使用只需存储实际数据的空间。当优化完成, InnoDB 删除旧的 .ibd文件和替换它与新。如果说以前的 鸡传染性法氏囊病 文件增长显著,但实际数据只占其体积的一部分,运行 OPTIMIZE TABLE回收未使用的空间 您可以将个人 InnoDB而不是整个数据库表 你可以复制的个体 InnoDB从一个MySQL实例到另一个表(称为 可传输表空间 特征) 您可以启用表大更高效的存储 BLOB或 文本 柱的使用 动态行格式 每个表的表空间可以提高文件恢复成功的机会,节省时间,当一个腐败的发生,当服务器无法重新启动,或当备份和二进制日志不可用。 你可以备份或还原单个表迅速用MySQL企业备份产品,不中断的使用等 InnoDB表如果你有表需要备份较少或在不同的备份计划,这是有益的。看到 使部分备份 详情 每个表的表空间文件每台状态报告时,复制或备份表方便。 你可以在一个文件系统级监控表的大小,而无需访问MySQL。 常见的Linux文件系统不允许同时写入一个文件时, innodb_flush_method是集 直接_ O 。因此,有可能的性能改进,当使用文件每表表空间结合 innodb_flush_methodSYSTEM表空间存储数据字典和UNDO日志,和的大小是有限的 InnoDB表空间大小的限制。See 第15.8.1.7”限制,InnoDB表” 。每个表的表空间文件,每个表都有自己的空间,它提供了成长的空间。
每个表的表空间文件潜在的缺点
每个表的表空间文件,每个表可能有未使用的空间,这只能由同一个表中的行的利用。这可能会导致浪费的空间如果不妥善管理。 fsync操作必须运行在每一个打开的表,而不是一个单一的文件。因为有一个单独的 fsync 每个文件的操作,写操作在多个表不能被合并成一个单一的I/O操作。这可能需要 InnoDB执行一个较高的总数量 fsync 运营 mysqld 必须保持每桌一个打开的文件句柄,这可能会影响性能,如果你在每个表的表空间中有大量的表格文件。 使用多个文件描述符 innodb_file_per_table默认情况下启用。你可以考虑禁用如果MySQL 5.5或更早版本的向后兼容性是一个问题。禁用 innodb_file_per_table防止 ALTER TABLE从移动 InnoDB 从系统表空间到一个单独的表 .ibd文件的情况下 ALTER TABLE重新创建表( ALGORITHM=COPY) 例如,当重组聚集索引的 InnoDB表,表中重新创建使用当前设置 innodb_file_per_table。这种行为不适用于添加或删除时 InnoDB 次要指标。当一次索引的创建没有重建表,索引存储在同一文件中的表格数据,无论当前 innodb_file_per_table设置这种行为也不适用于表添加到系统表空间使用 CREATE TABLE ... TABLESPACE或 ALTER TABLE ... TABLESPACE语法。这些表不受影响 innodb_file_per_table设置 如果多个表越来越有更多的碎片可以阻碍潜在 DROP TABLE和表扫描性能。然而,当碎片化的管理,在自己的表空间有文件可以提高性能。 缓冲池扫描当滴每桌表空间文件,这可能需要几秒钟缓冲池大小的字节数。扫描是一个广泛的内部锁,这可能会延迟其他操作。在SYSTEM表空间的表不受影响。 这个 innodb_autoextend_increment变量,它定义了增量大小(MB)扩展延伸共享表空间文件当它成为全自动的大小,并不适用于每个表的表空间文件的文件,这是自动延伸的 innodb_autoextend_increment设置最初的扩展是由少量,之后扩展发生在增量4MB。
innodb_file_per_table
innodb_file_per_table--innodb_file_per_tablemy.cnf
[mysqld]innodb_file_per_table=1
innodb_file_per_table
MySQL的> SET GLOBAL innodb_file_per_table=1;
innodb_file_per_tabletbl_name.ibdtbl_name.MYDtbl_name.ibd
innodb_file_per_tableInnoDBCREATE TABLE ...
TABLESPACE
InnoDB
innodb_file_per_table
MySQL的> SET GLOBAL innodb_file_per_table=1;MySQL的> ALTER TABLEtable_nameENGINE=InnoDB;
CREATE TABLE ...
TABLESPACEALTER TABLE ...
TABLESPACEinnodb_file_per_tableALTER TABLE ...
TABLESPACE
InnoDB.ibd
.ibdInnoDBinnodb_file_per_tableCREATE TABLE ...
TABLESPACEALTER TABLE ...
TABLESPACEinnodb_file_per_table
DATA DIRECTORY =
absolute_path_to_directoryCREATE TABLE
DATA DIRECTORYALTER TABLE
.ibd
MySQL的> USE test;数据库changedmysql > SHOW VARIABLES LIKE 'innodb_file_per_table';----------------------- ------- | variable_name |价值| ----------------------- ------- | innodb_file_per_table |在| ----------------------- ------- MySQL > CREATE TABLE t1 (c1 INT PRIMARY KEY) DATA DIRECTORY = '/alternative/directory';# MySQL创建。在子目录对应的数据库# namedb_user @ Ubuntu新表的IBD文件:~ /替代/目录/试验 lst1.ibd
InnoDBinnodb_directoriesinnodb_directories
CREATE TABLE ...
TABLESPACEinnodb_file_per_table
MySQL的> CREATE TABLE t2 (c1 INT PRIMARY KEY) TABLESPACE = innodb_file_per_tableDATA DIRECTORY = '/alternative/directory';
innodb_file_per_table
使用说明:
MySQL最初持有 .ibd打开文件,防止你拆卸装置,但最终可能如果服务器正在关闭表。虽然MySQL正在小心不小心拆卸外部设备,或启动MySQL而设备断开。试图访问一个表时,相关 鸡传染性法氏囊病 文件丢失导致一个严重的错误,需要重新启动服务器。 服务器重启问题的错误和警告如果 .ibd文件不在预期的路径。在这种情况下,您可以还原表空间 鸡传染性法氏囊病 文件从备份或删除表从删除关于它的信息 数据字典 在下表在一个NFS安装量,审查潜在问题概述 使用NFS与MySQL 如果你使用LVM快照,文件复制,或其他基于文件的备份机制 .ibd文件,总是使用 FLUSH TABLES ... FOR EXPORT声明首先是要确保所有更改缓冲存储器 冲洗 磁盘备份发生之前 这个 DATA DIRECTORY条款是支持的替代 使用符号链接 ,这是不支持个人 InnoDB表
InnoDB
InnoDB
InnoDB
局限性和用法说明
表空间复制过程时,才有可能 innodb_file_per_table启用,这是默认设置。居住在共享系统表空间不能被停止的表。 当一个表是停止的,只有只读事务在受影响的表允许。 导入表空间时,页面大小必须匹配输入实例的页面大小。 ALTER TABLE ... DISCARD TABLESPACE负载partitioned is for InnoDB 表,并 ALTER TABLE ... DISCARD PARTITION ... TABLESPACE支持 InnoDB 表分区 DISCARD TABLESPACE不是一个亲子间的支持(主键外键)关系时 foreign_key_checks是集 一 。在丢弃一亲子表的表空间,设置 foreign_key_checks=0。分区 InnoDB 表不支持外键 ALTER TABLE ... IMPORT TABLESPACE不强制外键约束进口数据。如果有与表的外键约束,所有的表应该出口在同一时间点(逻辑)。分区 InnoDB 表不支持外键 ALTER TABLE ... IMPORT TABLESPACE和 ALTER TABLE ... IMPORT PARTITION ... TABLESPACE不需要 CFG桩复合地基 元数据文件导入表空间。然而,元数据检查不进行导入时,没有 .cfg文件,并警告类似下面的发行: 信息:InnoDB:IO读取错误:(2,没有这样的文件或目录)打开错误”。\检验\ t.cfg ',将试图进口无图式核对行集(0秒) 进口无能力 .cfg文件可以更方便的时候没有模式匹配的预期。此外,进口无能力 CFG桩复合地基 文件可以在崩溃恢复的情况下,无法收集的元数据是有用的 .ibd文件 如果没有 .cfg文件使用, InnoDB 用一个等效的 SELECT MAX(ai_col) FROMtable_nameFOR UPDATE语句初始化内存自动递增计数器,用于分配的值为 汽车 专栏否则,当前的最大自动递增计数器值的读取 .cfg元数据文件。相关的信息,看 InnoDB auto_increment计数器初始化 由于一个 .cfg元数据文件的限制,架构不匹配不报道的分区类型或分区定义差异时,进口表空间文件分区表。报道了柱的差异。 当运行 ALTER TABLE ... DISCARD PARTITION ... TABLESPACE和 ALTER TABLE ... IMPORT PARTITION ... TABLESPACE在subpartitioned分区和子分区表,表名是允许的。当一个分区,分区名称指定,包括在操作的子分区。 从另一个MySQL服务器实例导入表空间文件作品如果实例有GA(通用性)状态和服务器实例的文件导入是在相同或更高的版本在同一版本系列。导入表空间文件到一个服务器实例运行较早版本的MySQL不支持。 在复制的情景, innodb_file_per_table必须设置为 打开(放) 对主人和奴隶 在Windows, InnoDB存储数据库,表空间,并在小写字母表的名称。为了避免敏感的操作系统如Linux和Unix的进口问题,创建的所有数据库,表空间,使用小写的名字表。一个方便的方式来完成,这是添加下面一行的 [ mysqld ] 部分的你 my.cnf或 my.ini 在创建数据库,文件表空间,或表: [mysqld] lower_case_table_names=1
笔记 禁止在启动服务器 lower_case_table_names设置不同的设置时使用的服务器初始化。 ALTER TABLE ... DISCARD TABLESPACE和 ALTER TABLE ...IMPORT TABLESPACE是不是属于一个表支持 InnoDB 一般的表空间。有关更多信息,参见 CREATE TABLESPACE默认的行格式 InnoDB表的配置使用 innodb_default_row_format配置选项。试图导入的表不显式定义行格式( row_format ),或使用 ROW_FORMAT=DEFAULT,可能会导致一个模式失配误差如果 innodb_default_row_format设置源实例不同于目标实例的设置。相关的信息,看 第15.10.2,“指定行格式为表” 在导出表空间,使用加密 InnoDB表空间加密功能, InnoDB 生成一个 .cfp另外一个文件 CFG桩复合地基 元数据文件。这个 .cfp文件必须复制到目标实例一起 CFG桩复合地基 文件和表空间文件之前执行 ALTER TABLE ... IMPORT TABLESPACE在目标实例操作。这个 。CFP 文件包含一个传输密钥和加密密钥空间。进口, InnoDB使用传输密钥解密表空间的关键。相关的信息,看 第15.7.11,“InnoDB表空间加密” FLUSH TABLES ... FOR EXPORT不支持,有一个全文索引表。全文搜索辅助表不脸红。在导入一张 全文 指数运行 OPTIMIZE TABLE重建 全文 指标。另外,降 FULLTEXT指标导出操作之前和之后重新创建它们进口目标实例的表。
InnoDB
例1:一个InnoDB表复制到另一个实例
InnoDB
在源代码实例,创建一个表,如果不存在: mysql>
USE test;mysql>CREATE TABLE t(c1 INT) ENGINE=InnoDB;在目标实例,创建一个表,如果不存在: mysql>
USE test;mysql>CREATE TABLE t(c1 INT) ENGINE=InnoDB;在目标实例,抛弃现有的表空间。(前一个表空间可以进口, InnoDB必须抛弃的表空间是连接到接收表。) MySQL的> ALTER TABLE t DISCARD TABLESPACE;在实例的源码,运行 FLUSH TABLES ... FOR EXPORT暂停该表的创建 CFG桩复合地基 元数据文件: mysql>
USE test;mysql>FLUSH TABLES t FOR EXPORT;元数据( .cfg)中创建 InnoDB 数据目录 笔记 这个 FLUSH TABLES ... FOR EXPORT声明确保命名表的变化已被刷新到磁盘,一个二进制表复制可以在实例运行。什么时候 FLUSH TABLES ... FOR EXPORT运行, InnoDB 产生一个 .cfg在同一个数据库文件的目录表。这个 CFG桩复合地基 文件包含用于架构验证导入表空间元数据文件时。 复制 .ibd文件和 CFG桩复合地基 元数据文件从源到目标实例的实例。例如: shell>
scp/path/to/datadir/test/t.{ibd,cfg} destination-server:/path/to/datadir/test笔记 这个 .ibd文件和 CFG桩复合地基 文件必须复制之前释放共享锁,为下一步的描述。 在实例的源码,使用 UNLOCK TABLES释放获取的锁 FLUSH TABLES ... FOR EXPORT: MySQL的> USE test;MySQL的> UNLOCK TABLES;在目标实例,导入的表空间: mysql>
USE test;mysql>ALTER TABLE t IMPORT TABLESPACE;笔记 这个 ALTER TABLE ... IMPORT TABLESPACE功能不执行导入数据的外键约束。如果有与表的外键约束,所有的表应该出口在同一时间点(逻辑)。在这种情况下,你会停止更新表,提交所有交易,获取表上的共享锁,然后执行导出操作。
例2:复制InnoDB表分区到另一个实例
InnoDB
在实例的源码,创建分区表如果不存在。在下面的例子中,三个分区表(P0,P1,P2)创建: mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3;在 /datadir/test目录中,有一个单独的表空间( 鸡传染性法氏囊病 )每三个分区的文件 mysql>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd/path/to/datadir/test/在目标实例,创建相同的分区表: mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3;在 /datadir/test目录中,有一个单独的表空间( 鸡传染性法氏囊病 )每三个分区的文件 mysql>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd/path/to/datadir/test/在目标实例,抛弃对分区表的表空间。(在表空间可以进口的目标实例,表空间是连接到接收表必须丢弃。) mysql>
ALTER TABLE t1 DISCARD TABLESPACE;三 .ibd文件,弥补了分区表的表空间被丢弃的 / datadir测试 目录 在实例的源码,运行 FLUSH TABLES ... FOR EXPORTto the the table和创造partitioned静默 CFG桩复合地基 元数据文件: mysql>
USE test;mysql>FLUSH TABLES t1 FOR EXPORT;元数据( .cfg)文件,每一个表空间( 鸡传染性法氏囊病 )文件,创建于 /datadir/test在源实例目录: MySQL的> \! ls/path/to/datadir/test/# p0.ibd T1 T1 # P P P # # # p1.ibd T1 T1 # p0.cfg # p2.ibdt1 # P P P T1的# # p1.cfg # # p2.cfg 笔记 FLUSH TABLES ... FOR EXPORT声明确保命名表的变化已被刷新到磁盘,二进制表复制可以在实例运行。什么时候 FLUSH TABLES ... FOR EXPORT运行, InnoDB 产生一个 .cfg元数据文件表的表空间文件在同一数据库目录表。这个 CFG桩复合地基 文件包含元数据用于架构验证当导入表空间文件。 FLUSH TABLES ... FOR EXPORT只能运行在桌子上,不是个人的表分区。 复制 .ibd和 CFG桩复合地基 从源实例的数据库目录到目标实例的数据库目录下的文件。例如: shell>scp
/path/to/datadir/test/t1*.{ibd,cfg} destination-server:/path/to/datadir/test笔记 这个 .ibd和 CFG桩复合地基 文件必须复制之前释放共享锁,为下一步的描述。 在实例的源码,使用 UNLOCK TABLES释放获取的锁 FLUSH TABLES ... FOR EXPORT: MySQL的> USE test;MySQL的> UNLOCK TABLES;在目标实例,导入表空间的分区表: mysql>
USE test;mysql>ALTER TABLE t1 IMPORT TABLESPACE;
例三:InnoDB表分区复制到另一个实例
InnoDB
在实例的源码,创建分区表如果不存在。在下面的例子中,四个分区表(P0,P1,P2,P3)创建: mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4;在 /datadir/test目录中,有一个单独的表空间( 鸡传染性法氏囊病 - Fil for each of the Four Pacts . mysql>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd/path/to/datadir/test/在目标实例,创建相同的分区表: mysql>
USE test;mysql>CREATE TABLE t1 (i int) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4;在 /datadir/test目录中,有一个单独的表空间( 鸡传染性法氏囊病 - Fil for each of the Four Pacts . mysql>
\! lst1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd/path/to/datadir/test/在目标实例,将表空间的分区,您计划从源实例导入。(在表空间的分区可以进口的目标实例,是连接到接收表相应的分区必须被丢弃。) mysql>
ALTER TABLE t1 DISCARD PARTITION p2, p3 TABLESPACE;这个 .ibd对于两丢弃分区文件被删除的 / datadir测试 在目标实例目录,将下列文件: MySQL的> \! ls/path/to/datadir/test/# p0.ibd T1 T1 # P P # p1.ibd # 笔记 什么时候 ALTER TABLE ... DISCARD PARTITION ... TABLESPACE运行在subpartitioned分区和子分区表,表名是允许的。当一个分区,分区名称指定,包括在操作的子分区。 在实例的源码,运行 FLUSH TABLES ... FOR EXPORTto the the table和创造partitioned静默 CFG桩复合地基 Metadat-files。 mysql>
USE test;mysql>FLUSH TABLES t1 FOR EXPORT;元数据文件( .cfg文件)创建于 / datadir测试 在源实例目录。有一个 CFG桩复合地基 每个表空间文件( .ibd文件) MySQL的> \! ls/path/to/datadir/test/T1 # P # p0.ibd T1 # P # p1.ibd T1 # P # p2.ibd T1 # P # P3。ibdt1 # P # p0.cfg T1 # P # p1.cfg T1 # P # p2.cfg T1 # P # p3.cfg 笔记 FLUSH TABLES ... FOR EXPORT声明确保命名表的变化已被刷新到磁盘,二进制表复制可以在实例运行。什么时候 FLUSH TABLES ... FOR EXPORT运行, InnoDB 产生一个 .cfg元数据文件表的表空间文件在同一数据库目录表。这个 CFG桩复合地基 文件包含元数据用于架构验证当导入表空间文件。 FLUSH TABLES ... FOR EXPORT只能运行在桌子上,不是个人的表分区。 复制 .ibd和 CFG桩复合地基 从源实例的数据库目录到目标实例的数据库目录下的文件。在这个例子中,只有 .ibd和 CFG桩复合地基 2文件的分区(P2)和分区3(P3)复制到 data在目标实例目录。分区0(P0)和分区1(P1)留在源码实例。 内核> scp t1#P#p2.ibd t1#P#p2.cfg t1#P#p3.ibd t1#P#p3.cfg destination-server:/path/to/datadir/test笔记 这个 .ibd文件和 CFG桩复合地基 文件必须复制之前释放共享锁,为下一步的描述。 在实例的源码,使用 UNLOCK TABLES释放获取的锁 FLUSH TABLES ... FOR EXPORT: MySQL的> USE test;MySQL的> UNLOCK TABLES;关于目的地,进出口部分(P2和P3): mysql>
USE test;mysql>ALTER TABLE t1 IMPORT PARTITION p2, p3 TABLESPACE;笔记 什么时候 ALTER TABLE ... IMPORT PARTITION ... TABLESPACE运行在subpartitioned分区和子分区表,表名是允许的。当一个分区,分区名称指定,包括在操作的子分区。
InnoDB
ALTER TABLE
... DISCARD TABLESPACE
表锁定在X模式 独立的表空间(tablespace)is the from the table。
FLUSH
TABLES ... FOR EXPORT
桌子被冲洗出口被锁在共享模式。 清除线程停止协调员 脏页都同步到磁盘 表的元数据写入二进制 .cfg文件
2013-09-24T13:10:19.903526Z 2 [Note] InnoDB: Sync to disk of '"test"."t"' started. 2013-09-24T13:10:19.903586Z 2 [Note] InnoDB: Stopping purge 2013-09-24T13:10:19.903725Z 2 [Note] InnoDB: Writing table metadata to './test/t.cfg' 2013-09-24T13:10:19.904014Z 2 [Note] InnoDB: Table '"test"."t"' flushed to disk
UNLOCK
TABLES
二CFG文件被删除 共享锁在表或表进口释放和净化协调线程启动。
2013-09-24T13:10:21.181104Z 2 [Note] InnoDB: Deleting the meta-data file './test/t.cfg' 2013-09-24T13:10:21.181180Z 2 [Note] InnoDB: Resuming purge
ALTER TABLE
... IMPORT TABLESPACE
每个表空间的页查腐败。 空间ID和日志序列号(LSN)在每一页的更新 标志验证和LSN更新的标题页。 Btree页的更新 页面状态设置为脏,写入磁盘。
2013-07-18 15:15:01 34960 [Note] InnoDB: Importing tablespace for table 'test/t' that was exported from host 'ubuntu' 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase I - Update all pages 2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk 2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk - done! 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase III - Flush changes to disk 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase IV - Flush complete
.ibd
2013-07-18 15:14:38 34960 [警告] InnoDB:表“测试”,“T”表空间设置为discarded.2013-07-18 15:14:38 7f34d9a37700 InnoDB:无法计算表的“测试”的统计,“T”因为IBD文件丢失。的帮助,请参阅tohttp://dev.mysql.com/doc/refman/8.0/en/innodb-troubleshooting.html
innodb_directories
innodb_data_home_dirinnodb_undo_directorydatadirinnodb_directoriesinnodb_directoriesinnodb_directories--datadir
innodb_directories
mysqld --innodb-directories="directory_path_1;directory_path_2"
[mysqld] innodb_directories="directory_path_1;directory_path_2"
停止服务器 将表空间的文件或目录。 使新的目录称为 InnoDB如果移动的个体 文件表 或 烟草公司 文件目录,添加未知的 innodb_directories价值 定义的目录 innodb_data_home_dir, innodb_undo_directory,和 datadir配置选项会自动添加到 innodb_directories参数的值,所以你不需要指定这些。 文件表空间文件只能搬到一个相同名字的目录架构。例如,如果 actor表属于 sakila 图式,然后 actor.ibd数据文件只能被移到一个目录下 sakila 一般的表空间文件不能被移动到数据目录和数据目录的一个子目录中。
如果移动系统表空间文件,撤销表空间,或数据目录,更新 innodb_data_home_dir, innodb_undo_directory,和 datadir设置必要的
重新启动服务器
使用说明
通配符表达式不能用于 innodb_directories参数的值 这个 innodb_directories扫描指定的目录的子目录也穿越。复制目录和子目录被丢弃从目录列表进行扫描。 这个 innodb_directories选项仅支持移动 InnoDB 表空间文件。运动属于一个比其他存储引擎文件 InnoDB不支持。这个限制也适用于移动整个数据目录。 这个 innodb_directories选项支持重命名的表空间文件时将文件移动到一个扫描目录。它还支持移动表空间文件到其他支持的操作系统。 当移动表空间文件到一个不同的操作系统,确保表空间文件名不包含禁止的字符或字符与目标系统上的一个特殊的意义。 如果移动表空间文件到一个不同的操作系统,介绍了跨平台的复制,它是数据库管理员的责任确保DDL语句包含特定于平台的目录的复制。语句允许指定目录包括 CREATE TABLE ... DATA DIRECTORY和 CREATE TABLESPACE ... ADD DATAFILE该目录的文件表和一般的表空间创建的文件的绝对路径或在数据目录以外的位置应该被添加到 innodb_directories参数的值。否则, InnoDB 是不是能够找到这些文件的恢复。 CREATE TABLE ... DATA DIRECTORY和 CREATE TABLESPACE ... ADD DATAFILE允许的绝对路径表空间文件的创建。 CREATE TABLESPACE ... ADD DATAFILE也允许表空间文件目录,是相对于数据目录。查看表空间文件位置,查询 INFORMATION_SCHEMA.FILES表 MySQL的> SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES \GCREATE TABLESPACE ... ADD DATAFILE要求目标目录存在并且是众所周知的 InnoDB 。已知的目录包括隐式和显式定义的 innodb_directories选项
innodb_undo_tablespacesinnodb_undo_tablespaces
innodb_undo_tablespaces
innodb_undo_tablespacesinnodb_undo_tablespaces
innodb_undo_directorydatadirinnodb_undo_directory
undo_NNNNNN
undo space number = 0xFFFFFFF0 - undo space ID
undo space ID = 0xFFFFFFF0 - undo space number
innodb_rollback_segments
innodb_rollback_segments
innodb_rollback_segments
innodb_undo_tablespacesinnodb_undo_tablespaces
MySQL的> SELECT @@innodb_undo_tablespaces;Taballacco,Annod,Annod Change,Annod Change,Annod Change,Annod Change,Annod Change,Annod Change,Annod Change,Annod Change,Annod Can,Annodb Conseiller,Taballages Industry
innodb_undo_tablespaces
使截断撤销表空间
innodb_undo_log_truncate
MySQL的> SET GLOBAL innodb_undo_log_truncate=ON;
innodb_undo_log_truncateinnodb_max_undo_log_sizeinnodb_max_undo_log_size
MySQL的> SELECT @@innodb_max_undo_log_size;第二次世界大战期间发生的事件
innodb_max_undo_log_size
mysql> SET GLOBAL innodb_max_undo_log_size=2147483648;
innodb_undo_log_truncate
撤销表空间,超过 innodb_max_undo_log_size设置标记为截断。选择一个undo表空间截断是以循环的方式进行避免截断的undo表空间的每一次。 回滚段居住在选定的undo表空间是不活跃的,它们没有被分配到新的交易。现有的交易,目前正在使用的回滚段被允许完成。 这个 净化 系统释放那些不再需要的回滚段。 在undo表空间是释放所有的回滚段,截断操作运行和undo表空间是截断其初始大小。一个undo表空间文件取决于初始大小 innodb_page_size的价值。for the default 16K InnoDB 页面大小,初始的undo表空间的文件大小是10mib。4K,8K,32K、64K的页面大小,初始undo表空间文件大小7mib,8mib,20mib,和40mib,分别。 一个截断术后撤销表空间的大小可能大于由于直接使用下面的操作完成的初始大小。 这个 innodb_undo_directory选项定义了undo表空间文件的位置。默认值 “ “ 代表所在的目录 InnoDB默认情况下创建日志文件。 MySQL的> SELECT @@innodb_undo_directory;见到| @ @ InnoDB _ Undo _ |见到|目录。|见到 回滚段可以分配给新的交易活动。
加快截断的undo表空间文件
innodb_purge_rseg_truncate_frequencyinnodb_purge_rseg_truncate_frequency
MySQL的> SELECT @@innodb_purge_rseg_truncate_frequency;---------------------------------------- | @ @ InnoDB _ _ truncate _频电磁_ rseg | ---------------------------------------- | | ---------------------------------------- 128
innodb_purge_rseg_truncate_frequency
MySQL的> SET GLOBAL innodb_purge_rseg_truncate_frequency=32;
性能影响截断undo表空间文件在线
number of Undo表空间 一些UNDO日志 undo表空间的大小 的I / O susbsystem速度 现有的长时间运行的事务 系统负荷
InnoDBCREATE
TABLESPACE
类似的系统表空间,表空间是共享表空间一般可以存储数据的多个表。 一般的表空间有一个潜在的内存优势 每个表的表空间文件 。表空间元数据服务器保存在内存中的表空间的寿命。更少的一般表空间多个表的表空间元数据的消耗比在单独的文件中的每个表的表空间表相同数量的内存少。 一般表空间数据文件可以放在一个目录相关或独立的MySQL数据目录,它为你提供了许多数据文件和存储管理能力 每个表的表空间文件 。与每个表的表空间文件,将数据文件的MySQL数据目录之外的能力允许你管理关键表分别表现,设定RAID或DRBD的特定的表,或将表特定的磁盘,例如。 一般表空间支持的羚羊和梭鱼的文件格式,因此支持所有的表行的格式和相关特征。对文件格式的支持,一般表空间没有依赖 innodb_file_format或 innodb_file_per_table设置这些变量,也不会有任何影响的一般表空间。 这个 TABLESPACE选项可用于 CREATE TABLE在一般的表空间中创建表,每个表的表空间文件,或在SYSTEM表空间。 这个 TABLESPACE选项可用于 ALTER TABLE从一般的表空间,表,每个表的表空间文件,和系统表空间。以前,它是不可能移动一个表每表表空间文件系统表空间。与一般的表空间的功能,现在你可以这样做。
CREATE TABLESPACE
CREATE TABLESPACE tablespace_name ADD DATAFILE 'file_name' [FILE_BLOCK_SIZE = value] [ENGINE [=] engine_name]
InnoDBinnodb_directoriesinnodb_directories
mysql> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
mysql> CREATE TABLESPACE `ts1` ADD DATAFILE '/my/tablespace/directory/ts1.ibd' Engine=InnoDB;
my_tablespace
MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE '../my_tablespace/ts1.ibd' Engine=InnoDB;
ENGINE = InnoDBCREATE
TABLESPACEdefault_storage_engine=InnoDB
InnoDBCREATE
TABLE tbl_name ... TABLESPACE [=]
tablespace_nameALTER TABLE
tbl_name TABLESPACE [=]
tablespace_name
MySQL的> CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=COMPACT;
MySQL的> ALTER TABLE t2 TABLESPACE ts1;
CREATE
TABLEALTER TABLE
REDUNDANTDYNAMIC
ROW_FORMAT=COMPRESSEDFILE_BLOCK_SIZEinnodb_page_sizeFILE_BLOCK_SIZE/1024innodb_page_size=16KFILE_BLOCK_SIZE=8KKEY_BLOCK_SIZE
innodb_page_sizeKEY_BLOCK_SIZEKEY_BLOCK_SIZEFILE_BLOCK_SIZEKEY_BLOCK_SIZECREATE TABLE
innodb_page_size | ||
innodb_page_size | ||
innodb_page_size | ||
innodb_page_sizeKEY_BLOCK_SIZE
MySQL的> CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的> CREATE TABLE t4 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
FILE_BLOCK_SIZEinnodb_page_sizeinnodb_page_sizeREDUNDANT
ALTER TABLEInnoDB
CREATE TABLESPACE
ALTER TABLE tbl_name TABLESPACE [=]tablespace_nameinnodb_system
ALTER TABLE tbl_name ... TABLESPACE [=] innodb_system
innodb_file_per_table
ALTER TABLE tbl_name ... TABLESPACE [=] innodb_file_per_table
ALTER TABLE ... TABLESPACE
ALTER TABLE ... TABLESPACE
DATA DIRECTORYCREATE TABLE ... TABLESPACE=innodb_file_per_tableTABLESPACE
TABLESPACE
mysql>CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;mysql>CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' Engine=InnoDB;mysql>CREATE TABLE t1 (a INT, b INT) ENGINE = InnoDBPARTITION BY RANGE(a) SUBPARTITION BY KEY(b) (PARTITION p1 VALUES LESS THAN (100) TABLESPACE=`ts1`,PARTITION p2 VALUES LESS THAN (1000) TABLESPACE=`ts2`,PARTITION p3 VALUES LESS THAN (10000) TABLESPACE `innodb_file_per_table`,PARTITION p4 VALUES LESS THAN (100000) TABLESPACE `innodb_system`);mysql>CREATE TABLE t2 (a INT, b INT) ENGINE = InnoDBPARTITION BY RANGE(a) SUBPARTITION BY KEY(b) (PARTITION p1 VALUES LESS THAN (100) TABLESPACE=`ts1`(SUBPARTITION sp1,SUBPARTITION sp2),PARTITION p2 VALUES LESS THAN (1000)(SUBPARTITION sp3,SUBPARTITION sp4 TABLESPACE=`ts2`),PARTITION p3 VALUES LESS THAN (10000)(SUBPARTITION sp5 TABLESPACE `innodb_system`,SUBPARTITION sp6 TABLESPACE `innodb_file_per_table`));
TABLESPACEALTER TABLE
MySQL的> ALTER TABLE t1 ADD PARTITION (PARTITION p5 VALUES LESS THAN (1000000) TABLESPACE = `ts1`);
TABLESPACE =
tablespace_nameALTER TABLE ...
ADD PARTITIONCREATE TABLEALTER TABLE
ALTER TABLE tbl_name
TABLESPACE [=]
tablespace_nameALTER TABLEALGORITHM=COPYTABLESPACE [=]
tablespace_name
INFORMATION_SCHEMA.INNODB_TABLES
MySQL的> SELECT NAME, SPACE, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_TABLESWHERE NAME LIKE '%t1%';----------------------- ------- ------------ |名字|空间| space_type | ----------------------- ------- ------------ |测试/ T1 # P # P1 # SP # p1sp0 | 57 |一般| |测试/ T1 # P # P2 # SP # p2sp0 | 58 |一般| |测试/ T1 # P # P3 # SP # p3sp0 | 59 |单| |测试/ T1 # P # P4 # SP # p4sp0 | 0 |系统| |测试/ T1 # P # P5 # SP # p5sp0 | 57 |一般| ----------------------- ------- ------------ MySQL > SELECT NAME, SPACE, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_TABLESWHERE NAME LIKE '%t2%';--------------------- ------- ------------ |名字|空间| space_type | --------------------- ------- ------------ |测试/ T2 # P # P1 # SP # SP1 | 57 |一般| |测试/ T2 # P # P1 # SP # SP2 | 57 |一般| |测试/ T2 # P # P2 # SP # SP3 | 60 |单| |测试/ T2 # P # P2 # SP # SP4 | 58 |一般| |测试/ T2 # P # P3 # SP # SP5 | 0 |系统| |测试/ T2 # P # P3 # SP # SP6 | 61 |单| --------------------- ------- ------------
ALTER TABLE
tbl_name REORGANIZE
PARTITION
INFORMATION_SCHEMA.INNODB_TABLESINFORMATION_SCHEMA.INNODB_TABLESPACES
TABLESPACE =
tablespace_nameInnoDBt1ts1ALTER TABLE t1
REORGANIZE PARTITION
ALTER TABLEALGORITHM=COPYTABLESPACE [=]
tablespace_name
MySQL的> CREATE TABLESPACE ts1 ADD DATAFILE 'ts1.ibd';MySQL的> CREATE TABLESPACE ts2 ADD DATAFILE 'ts2.ibd';MySQL的> CREATE TABLE t1 ( a INT NOT NULL, PRIMARY KEY (a))ENGINE=InnoDB TABLESPACE ts1PARTITION BY RANGE (a) PARTITIONS 3 (PARTITION P1 VALUES LESS THAN (2),PARTITION P2 VALUES LESS THAN (4) TABLESPACE `innodb_file_per_table`,PARTITION P3 VALUES LESS THAN (6) TABLESPACE `innodb_system`);MySQL的> SELECT A.NAME as partition_name, A.SPACE_TYPE as space_type, B.NAME as space_nameFROM INFORMATION_SCHEMA.INNODB_TABLES ALEFT JOIN INFORMATION_SCHEMA.INNODB_TABLESPACES BON A.SPACE = B.SPACE WHERE A.NAME LIKE '%t1%' ORDER BY A.NAME;|分区---------------- ----------------- Enbrel -------——_ name |太空_型|太空_ name | ----------------- Enbrel ------- |;T1——试验/ # P # P1 |将军| TS1 | |测试/ # P2 P T1 # |单|测试/ # # P2 P T1 T1 | |测试/ # P3 P # |系统|空| MySQL ----------------- Enbrel -------——>; ALTER TABLE t1 REORGANIZE PARTITION P1INTO (PARTITION P1 VALUES LESS THAN (2) TABLESPACE = `ts2`);MySQL的> ALTER TABLE t1 REORGANIZE PARTITION P2INTO (PARTITION P2 VALUES LESS THAN (4) TABLESPACE = `ts2`);MySQL的> ALTER TABLE t1 REORGANIZE PARTITION P3INTO (PARTITION P3 VALUES LESS THAN (6));MySQL的> SELECT A.NAME AS partition_name, A.SPACE_TYPE AS space_type, B.NAME AS space_nameFROM INFORMATION_SCHEMA.INNODB_TABLES ALEFT JOIN INFORMATION_SCHEMA.INNODB_TABLESPACES BON A.SPACE = B.SPACE WHERE A.NAME LIKE '%t1%' ORDER BY A.NAME;|分区---------------- ----------------- Enbrel ------- ----------------- Enbrel ------- _ name |太空_型|太空_ name | ---------------- ----------------- Enbrel ------- ----------------- Enbrel ------- |测试/ P T1 # # P1 |将军| ts2 | |测试/ # P2 P T1 # |将军| ts2 | |测试/ P T1 # # P3 |将军| TS1 | ---------------- ----------------- Enbrel ------- ----------------- Enbrel -------
ALTER
TABLESPACE ... RENAME TO
修改表空间重命名S2 S1;
CREATE TABLESPACE
RENAME TOautocommitautocommit
RENAME TOLOCK TABLESFLUSH TABLES WITH READ
LOCK
DROP TABLESPACE
DROP TABLESPACEDROP
TABLESPACE
InnoDBDROP TABLESPACE
tablespace_name
DROP DATABASEDROP
DATABASEDROP
TABLESPACE tablespace_name
InnoDBDROP TABLE
InnoDB
mysql>CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;mysql>CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts10 Engine=InnoDB;mysql>DROP TABLE t1;mysql>DROP TABLESPACE ts1;
tablespace_name
一个生成的或现有的表空间不能被改变到一个一般的表空间。 临时表空间创建一般不支持。 一般不支持临时表的表空间。 类似的系统表空间,截断或删除表存储在表空间创建的自由空间一般在一般的表空间 IBD数据文件 这只能用于新 InnoDB数据空间不回操作系统它是释放 文件表 表空间 此外,表复制 ALTER TABLE操作台位于共享表空间(一般的表空间或SYSTEM表空间)可以增加表空间使用的空间量。这样的操作需要在表格和索引数据的多少额外的空间。为表复制所需的额外空间 ALTER TABLE操作不回操作系统是每个表的表空间文件发布。 ALTER TABLE ... DISCARD TABLESPACE和 ALTER TABLE ...IMPORT TABLESPACE不属于一个总的表空间表支持。
InnoDB
InnoDB
keyring_file
这个 keyring_encrypted_file插件,这在一个加密的服务器主机的本地文件存储密匙数据。 这个 keyring_okv插件,包括KMIP客户端(KMIP 1.1)采用KMIP兼容的产品作为一个密匙存储后端。支持KMIP兼容的产品包括集中式的密钥管理解决方案,如Oracle密钥库,金雅拓KeySecure,泰勒斯Vormetric的密钥管理服务器,并fornetix关键业务流程。 这个 keyring_aws插件,这与亚马逊网络服务(AWS公里通信密钥管理服务)作为后端的密钥生成和使用密钥存储本地文件。
keyring_file
一个钥匙圈插件必须安装和配置。钥匙圈插件安装进行启动使用 early-plugin-load选项早期加载确保插件可以初始化之前 InnoDB 存储引擎。因为钥匙插件安装和配置说明,见 第6.5.4,“MySQL的钥匙” 只有一个钥匙圈插件应该是一次启用。使多个钥匙圈插件不支持。 重要 一旦加密表在MySQL实例创建的密钥环插件加载创建加密表时要继续加载使用 early-plugin-load选择,prior to InnoDB 初始化。如果不这样做,在错误的结果在启动和 InnoDB恢复 验证一个钥匙圈的插件是活跃的,使用 SHOW PLUGINS表或查询 INFORMATION_SCHEMA.PLUGINS表。例如: MySQL的> SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE 'keyring%';-------------- --------------- | plugin_name | plugin_status | -------------- --------------- | keyring_file |主动| -------------- --------------- 这个 innodb_file_per_table备选案文1: InnoDB 表空间加密只支持 文件表 表空间。或者,您可以指定 TABLESPACE='innodb_file_per_table'当创建一个加密选项表或改变现有的表启用加密。 使用前 InnoDB表空间加密功能与生产数据,确保你已经采取了措施来防止主密钥丢失。 如果主密钥丢失,加密存储在表空间文件的数据是不可恢复的。 如果你使用的是 keyring_file或 keyring_encrypted_file 插件,建议您创建的密钥数据备份文件后立即创建第一个加密表前和万能钥匙旋转后。对于 keyring_file插件,到此数据文件的位置是确定的 keyring_file_data配置选项。for the keyring_encrypted_file 插件,到此数据文件的位置是确定的 keyring_encrypted_file_data配置选项。如果你使用的是 keyring_okv 或 keyring_aws插件,确保你完成必要的配置。有关说明,见 第6.5.4,“MySQL的钥匙”
InnoDBCREATE TABLE
MySQL的> CREATE TABLE t1 (c1 INT) ENCRYPTION='Y';
InnoDBALTER TABLE
MySQL的> ALTER TABLE t1 ENCRYPTION='Y';
InnoDBENCRYPTION='N'ALTER TABLE
MySQL的> ALTER TABLE t1 ENCRYPTION='N';
ENCRYPTIONALTER TABLE ...
ENCRYPTIONALGORITHM=COPYALGORITHM=INPLACE
innodb_redo_log_encrypt
innodb_redo_log_encryptinnodb_redo_log_encrypt
ib_logfile0
InnoDB
innodb_undo_log_encrypt
innodb_undo_log_encryptinnodb_undo_log_encrypt
undoN.ibdN
InnoDB
ENCRYPTION_KEY_ADMINSUPER
mysql> ALTER INSTANCE ROTATE INNODB MASTER KEY;
ALTER INSTANCE
ROTATE INNODB MASTER KEYCREATE TABLE ...
ENCRYPTEDALTER TABLE ...
ENCRYPTED
InnoDB
InnoDB
InnoDBInnoDB
InnoDBtablespace_name.cfptablespace_name.cfp
这个 ALTER INSTANCE ROTATE INNODB MASTER KEY声明仅在复制环境中,主人和奴隶运行一个版本的MySQL支持表空间加密功能支持。 成功的 ALTER INSTANCE ROTATE INNODB MASTER KEY语句写入复制奴隶的二进制日志。 如果一个 ALTER INSTANCE ROTATE INNODB MASTER KEY语句失败,它没有记录到二进制日志,是不可复制的奴隶。 复制一个 ALTER INSTANCE ROTATE INNODB MASTER KEY如果钥匙插件安装在主而不是奴隶操作失败。 如果 keyring_file插件是安装在主人和奴隶,奴隶没有密匙数据文件复制 ALTER INSTANCE ROTATE INNODB MASTER KEY语句创建的奴隶的密匙数据文件,假设密钥环文件数据不在内存中缓存。 ALTER INSTANCE ROTATE INNODB MASTER KEY使用密匙文件数据被缓存在内存中,如果可以的话。
ENCRYPTIONCREATE TABLEALTER TABLEINFORMATION_SCHEMA.TABLES
MySQL的> SELECT TABLE_SCHEMA, TABLE_NAME, CREATE_OPTIONS FROM INFORMATION_SCHEMA.TABLESWHERE CREATE_OPTIONS LIKE '%ENCRYPTION="Y"%';+--------------+------------+----------------+| TABLE_SCHEMA | TABLE_NAME | CREATE_OPTIONS |+--------------+------------+----------------+| test | t1 | ENCRYPTION="Y" |+--------------+------------+----------------+
如果服务器退出或正常运行时停止,建议使用相同的加密设置,之前配置重新启动服务器。 第一主加密密钥时产生的第一个新的或现有的表是加密的。 主密钥重新加密钥匙转动的表空间,但不改变表空间密钥本身。改变表空间的关键,必须禁用和重新启用表加密使用 ALTER TABLEtbl_nameENCRYPTION,这是一个 ALGORITHM=COPY这是rebuilds手术真的结束了。 如果一个表创建的 COMPRESSION和 ENCRYPTION选项,在表空间的数据进行压缩加密。 如果一个钥匙圈数据文件(文件名的 keyring_file_data或 keyring_encrypted_file_data系统变量)是空的或缺少的,第一次执行 ALTER INSTANCE ROTATE INNODB MASTER KEY创建一个主密钥 卸载 keyring_file或 keyring_encrypted_file 插件不删除现有的密匙数据文件。 建议你不要把钥匙数据文件同目录下的表空间的数据文件。 修改 keyring_file_data或 keyring_encrypted_file_data在运行时设置或重新启动服务器可以导致以前的加密表无法访问,导致数据丢失。
高级加密标准(AES)是唯一支持的加密算法。 InnoDB表空间加密使用电子密码本(ECB)分组加密模式的表空间加密和密码块链接(CBC)用于数据加密的块加密模式。 改变 ENCRYPTION一个表的属性是一个 ALGORITHM=COPY运营 ALGORITHM=INPLACE不支持 表空间加密只支持存储在一个表 文件表 表空间。加密是不是存储在其他表空间的类型包括表支持 禁忌将军 ,的 系统表空间 ,UNDO日志表空间和临时表空间。 你不能移动或复制加密表从 文件表 表空间的表空间类型不支持。 默认情况下,表空间加密只适用于表空间的数据。重做日志和重做日志数据可能使用加密 innodb_redo_log_encrypt和 innodb_undo_log_encrypt选项看到 重做日志数据加密 ,和 UNDO日志数据加密 。二进制日志的数据是不加密的。 不允许更改一个表,加密或先前加密的存储引擎。
InnoDB
InnoDB
InnoDBCREATE TABLE
CREATE TABLE t1 (a INT, b CHAR (20), PRIMARY KEY (a)) ENGINE=InnoDB;
ENGINE=InnoDB
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+
ENGINE=InnoDBCREATE TABLE
InnoDBinnodb_file_per_tableinnodb_file_per_tableInnoDBCREATE TABLE ...
TABLESPACE
InnoDB
InnoDBtestt1
InnoDBinnodb_default_row_formatDynamicInnoDBinnodb_file_per_table
SET GLOBAL innodb_file_per_table=1;CREATE TABLE t3 (a INT, b CHAR (20), PRIMARY KEY (a)) ROW_FORMAT=DYNAMIC;CREATE TABLE t4 (a INT, b CHAR (20), PRIMARY KEY (a)) ROW_FORMAT=COMPRESSED;
CREATE TABLE ...
TABLESPACE
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=DYNAMIC;
CREATE TABLE ...
TABLESPACEDynamicRedundant
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE = innodb_system ROW_FORMAT=DYNAMIC;
InnoDBInnoDB
InnoDB
最重要的是通过查询引用。 没有留下空白 永远不会有重复的值 很少变化值一旦插入
(firstname,
lastname)
# The value of ID can act like a pointer between related items in different tables. CREATE TABLE t5 (id INT AUTO_INCREMENT, b CHAR (20), PRIMARY KEY (id)); # The primary key can consist of more than one column. Any autoinc column must come first. CREATE TABLE t6 (id INT AUTO_INCREMENT, a INT, b CHAR (20), PRIMARY KEY (id,a));
CREATE
TABLEALTER TABLE
InnoDBSHOW TABLE STATUS
MySQL的> SHOW TABLE STATUS FROM test LIKE 't%' \G;*************************** 1。行***************************名称:T1发动机:InnoDB版本:十row_format:紧凑的行数:0:0 avg_row_length data_length:16384max_data_length:0:0 0 index_length data_free:auto_increment:空create_time:2015-03-16 15:13:31 update_time:空check_time:空整理:utf8mb4_0900_ai_ci校验:空create_options:评论:
SHOW TABLE
STATUS
InnoDB
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test/t1' \G
*************************** 1. row ***************************
TABLE_ID: 45
NAME: test/t1
FLAG: 1
N_COLS: 5
SPACE: 35
ROW_FORMAT: Compact
ZIP_PAGE_SIZE: 0
SPACE_TYPE: Single
InnoDBinnodb_default_row_format
InnoDB
InnoDB
InnoDBSHOW TABLE
STATUS
MySQL的> SHOW TABLE STATUS IN test1\G*************************** 1。行***************************名称:T1发动机:InnoDB版本:10 row_format:动态的行:0 avg_row_length:0 data_length:16384max_data_length:0 index_length:16384:0:1 data_free auto_increment create_time:2016-09-14 16:29:38 update_time:空check_time:空整理:utf8mb4_0900_ai_ci校验:空create_options:评论:
InnoDBINFORMATION_SCHEMA.INNODB_TABLES
MySQL的> SELECT NAME, ROW_FORMAT FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test1/t1';---------- ------------ |名字| row_format | ---------- ------------ | test1/T1 |动态| ---------- ------------
REDUNDANT
InnoDB
每个索引记录包含6个字节的报头。这个头是用来连接连续的记录,也用于行级锁。 在聚集索引记录包含所有用户定义的列字段。此外,有6个字节的事务ID字段和7-byte辊指针字段。 如果没有主键是定义一个表,每个群集索引记录还包含6个字节的行ID字段。 每一次索引记录包含所有主键字段聚集索引的关键不在二级指标定义。 记录包含一个指针指向记录的每个字段。如果记录中字段的总长度小于字节,一个字节的指针;否则,两个字节。这些指针的数组被称为记录目录。这些指针指向的地方称为记录的数据部分。 InnoDB固定长度字段大于或等于76字节长度变长字段的编码,它可以存储页。例如,一个 char(255) 柱可以超过768字节如果字符集的最大字节长度大于3,因为它是 utf8mb4一个SQL NULL价值储备的唱片目录的一个或两个字节。除此之外,SQL 无效的 价值储备零字节的数据记录的一部分,如果存储在可变长度列。在固定长度列,它保留了在记录的数据部分的固定长度列。保留固定的空间 NULL值使栏目的更新 无效的 在非 NULL将不会导致网页索引碎片做的价值。
COMPACTCOMPACT
InnoDB
每个索引记录包含一个5字节的标头,可以冠以一个变长的头。这个头是用来连接连续的记录,也用于行级锁。 该记录头的长度可变的部分包含指示位向量 NULL专栏如果列数的指数,可以 无效的 是 N,位向量占用 ceiling( N八) 字节。(例如,如果有9到16列,可 无效的 ,位向量使用两个字节。)柱, NULL不占空间比其他在这个向量的点。标题的长度可变的部分还包含可变长度列的长度。每个长度以一个或两个字节,这取决于该列的最大长度。如果索引中的所有列 不为空 有一个固定的长度,记录头没有变长的部分。 每个非 NULL可变长度字段,记录头包含在一个或两个字节的列的长度。只需两字节如果列部分存储在外部溢出页或最大长度超过255字节和字节的实际长度超过127。一个外部存储的列的字节长度表示内部存储的部分加上20字节指针指向外部存储部分的长度。内部768字节,所以长度为20。20字节的指针存储列的真实长度。 记录头的后面是非数据内容— NULL专栏 在聚集索引记录包含所有用户定义的列字段。此外,有6个字节的事务ID字段和7-byte辊指针字段。 如果没有主键是定义一个表,每个群集索引记录还包含6个字节的行ID字段。 每一次索引记录包含所有主键字段聚集索引的关键不在二级指标定义。如果任何这些主键字段的长度是可变的,每一次索引记录头具有可变长度的部分记录的长度,即使次要指标是固定长度列定义。 在内部,为固定长度的字符集, InnoDB存储固定长度的字符列如 CHAR(10)在固定长度格式 InnoDB不截断的尾随空格 VARCHAR专栏 在内部,对可变长度字符集等 utf8mb3和 utf8mb4 , InnoDB试图保存 CHAR(N)进入 N通过修整尾随空格字节。如果一个字节的长度 CHAR(N)列值超过 N字节, InnoDB TRIMs尾随空格最少的列值的字节长度。一个最大长度 CHAR(N)柱的最大字节长度× NInnoDB储备最低 N字节 CHAR(N)。最小预留空间 N在许多情况下,使栏目更新到位而造成的碎片做索引页。通过比较,为 ROW_FORMAT=REDUNDANT, CHAR(N)柱的最大字节长度×占据 NInnoDB固定长度字段大于或等于76字节长度变长字段的编码,它可以存储页。例如,一个 char(255) 柱可以超过768字节如果字符集的最大字节长度大于3,因为它是 utf8mb4ROW_FORMAT=DYNAMIC和 ROW_FORMAT=COMPRESSED手柄 CHAR存储在相同的方式 ROW_FORMAT=COMPACT
InnoDB
InnoDBmy.cnf
[mysqld] lower_case_table_names=1
lower_case_table_names
InnoDB
迁移表空间
FLUSH
TABLES ... FOR EXPORTInnoDBinnodb_file_per_tableInnoDB
MySQL企业备份
复制数据文件(冷备份方法)
InnoDB
InnoDBFLOATDOUBLE
.ibd
.ibdRENAME
TABLE
重命名表 db1.tbl_name以 db2.tbl_name;
.ibd
桌子上没有删除或截断你复制 .ibd文件,因为这样会改变存储在表空间的表ID。 这一问题 ALTER TABLE语句删除当前 鸡传染性法氏囊病 文件: ALTER TABLE
tbl_nameDISCARD TABLESPACE;复制备份 .ibd文件到适当的数据库目录。 这一问题 ALTER TABLE声明中说 InnoDB 使用新的 .ibd文件内容表: 修改表 tbl_name导入表; 笔记 这个 ALTER TABLE ... IMPORT TABLESPACE功能不执行导入数据的外键约束。
.ibd
有交易的任何未提交的修改 .ibd文件 有无合并插入缓冲中的条目 .ibd文件 清除已删除所有删除标记索引的记录 .ibd文件 mysqld 已经刷新所有修改过的页面的 .ibd从缓冲池的文件
.ibd
停止一切活动,从 mysqld 所有的交易服务器和承诺。 等到 SHOW ENGINE INNODB STATUS显示数据库中有没有活跃的交易,而主线程的状态 InnoDB 是 Waiting for server activity。然后你可以复制的 鸡传染性法氏囊病 文件
.ibd
使用MySQL企业备份程序备份 InnoDB安装 开始第二 mysqld 服务器上的备份,让它清理 .ibd在备份文件
进出口(就)
MyISAMInnoDB
MyISAM
MyISAMkey_buffer_sizeinnodb_buffer_pool_sizeInnoDB
MyISAMautocommitCOMMITROLLBACK
如果你使用的是 MySQL 互动实验环节,总是 COMMIT(敲定的变化)或 ROLLBACK(撤销更改)完成时。关闭互动环节,而不是让他们开了很长时间,避免长时间打开的事务由事故。 ROLLBACK是一种比较昂贵的操作,因为 INSERT, UPDATE,和 DELETE操作写入 InnoDB 之前的表 COMMIT,与期望,大多数都是成功提交和回滚是罕见的。当试验的大量数据,避免更改大量行然后回滚这些变化。 加载大量的数据序列时 INSERT报表,定期 COMMIT结果避免了交易的最后几个小时。在典型的负载操作的数据仓库,如果做错了事情,你截断该表(使用 TRUNCATE TABLE)和从头开始而不是做 ROLLBACK
COMMIT
对于大多数操作 InnoDB表格,你应该使用的设置 autocommit=0。从效率的角度来看,这就避免了不必要的I / O当你发行大量连续的 INSERT, UPDATE,或 DELETE声明.从安全角度来看,这可以让你的问题 ROLLBACK语句来恢复丢失或数据被破坏,如果你在犯一个错误 MySQL 命令行,或者在一个异常处理程序在您的应用程序。 的时候 autocommit=1适用于 InnoDB 表是当运行一个查询序列生成报告或统计分析。在这种情况下,没有I/O处罚相关 COMMIT或 ROLLBACK,和 InnoDB 可以 自动优化只读的工作量 如果你把一系列相关的变化,最终在一个单独的所有改变 COMMIT最后.例如,如果您将相关的信息分成几个表,做一个 COMMIT在所有的变化。如果你运行多个 INSERT报表,做单 COMMIT毕竟数据加载;如果你是做百万 INSERT报表,也许分手的巨大的交易通过发行 COMMIT每一万或几十万条记录,所以交易不太大。 记住,即使 SELECT语句打开一个交易,所以在运行一些报告或在交互式调试查询 MySQL 会议期间,无论是问题 COMMIT或关闭 MySQL 会话
SHOW ENGINE INNODB
STATUSInnoDBinnodb_deadlock_detectinnodb_lock_wait_timeout
innodb_print_all_deadlocksSHOW ENGINE INNODB
STATUS
InnoDB
MyISAMinnodb_file_per_tableinnodb_page_sizeROW_FORMATCREATE TABLE
innodb_file_per_tableInnoDB
InnoDB
InnoDBALTER
TABLE
InnoDBtable_nameCREATE TABLEENGINE=INNODB
InnoDBinnodb_tablemyisam_tableprimary_key_columns
InnoDB
UNIQUE
SET unique_checks=0;... import operation ...SET unique_checks=1;InnoDBunique_checks
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey >somethingAND yourkey <=somethingelse;
InnoDB
InnoDBinnodb_file_per_table
MyISAMInnoDBALTER TABLE
PRIMARY KEY
声明一个 PRIMARY KEY每个表。通常,这是你所指的是最重要的列 哪里 条款在查找一行 申报 PRIMARY KEY在原来的条款 CREATE TABLE声明中,而不是添加后通过 ALTER TABLE声明 选择列及其数据类型的仔细。喜欢的数字列在字符或字符串的。 如果没有一个稳定的、独特的、非空的考虑使用自动递增列,数值列使用。 一个自动递增列也是一个不错的选择,如果有任何怀疑的主键列的值会改变。改变一个主键列中的值是一个昂贵的操作,可能涉及到重新排列的表中的数据在每个二级指标。
VARCHARUNIQUE NOT NULL
PRIMARY KEY
InnoDB
INT
InnoDBAUTO_INCREMENTAUTO_INCREMENTai_col
AUTO_INCREMENTInnoDB
AUTO_INCREMENTinnodb_autoinc_lock_mode
innodb_autoinc_lock_mode
“ INSERT喜欢 “ 声明 所有陈述,产生新的表行,包括 INSERT, INSERT ... SELECT, REPLACE, REPLACE ... SELECT,和 LOAD DATA。包括 “ 简单的插入 “ , “ 批量插入 “ ,和 “ 混合模式 “ 插入 “ 简单的插入 “ 陈述的是插入的行数可以事先确定(当语句初步处理)。这包括单排、多排 INSERT和 REPLACE声明没有嵌套的子查询,但不 INSERT ... ON DUPLICATE KEY UPDATE“ 批量插入 “ 陈述的是插入的行数(和所需的自动增量值的数量)在事先是不知道的。这包括 INSERT ... SELECT, REPLACE ... SELECT,和 LOAD DATA陈述,而不是单纯的 插入 InnoDB指定新的值为 汽车 列在一个时间的每一行进行处理。 “ 混合模式插入 “ 这些都是 “ 简单的插入 “ 语句指定了自动增量值(但不是全部)的新的行。一个例子如下,其中 c1是一个 汽车 列的表 t1: 插入T1(C1,C2)values(1,a),(a ' a),(Null,b),(5 ' c),(Null,d '); 另一种类型的 “ 混合模式插入 “ 是 INSERT ... ON DUPLICATE KEY UPDATE,在最坏的情况下实际上是一种 INSERT其次是 UPDATE,在分配值为 汽车 柱可能会或可能不会更新期使用。
innodb_autoinc_lock_modeinnodb_autoinc_lock_mode=2innodb_autoinc_lock_mode=1
innodb_autoinc_lock_mode = 0( “ 传统 “ 锁定模式) 传统的锁模式提供了在存在相同的行为 innodb_autoinc_lock_mode配置参数介绍了MySQL 5.1。传统的锁模式的选择提供了向后兼容性,性能测试,并在“混合模式插入”问题的工作,由于在语义上可能存在的差异。 在这种锁定模式,所有 “ 插入像 “ 报表获得特殊的表级 AUTO-INC锁插入表 汽车 专栏这锁通常被认为语句的末尾(不到交易结束)确保自动增量值被分配在一个可预测和可重复的,对于一个给定的序列 INSERT报表,并确保自动增量值的任何语句分配是连续的。 在基于语句的复制的情况下,这意味着当一个SQL语句是在从服务器上复制,相同的值用于自动递增列作为主服务器上。执行多个结果 INSERT报表是确定性的,和从再现相同的数据作为主人。如果由多个自动增量值 INSERT报表是交错的,两个并行的结果 INSERT报表将具有不确定性,并不能可靠地传播到使用基于语句的复制从服务器。 清楚地说明这一点,考虑一个例子,使用此表: CREATE TABLE t1 ( c1 INT(11) NOT NULL AUTO_INCREMENT, c2 VARCHAR(10) DEFAULT NULL, PRIMARY KEY (c1) ) ENGINE=InnoDB;
假设有两交易,每个插入到表中的 AUTO_INCREMENT专栏一个事务使用 INSERT ... SELECT语句,插入1000行,另一个是使用一个简单的 INSERT表插入一行: TX1:插入T1(C2)选择1000行与另一个表中插入…2:T1(C2)值('xxx”); InnoDB不知道提前多少行提取 SELECT在 INSERT声明在TX1,它将自动增加值一次为报表收益。与表级锁,在语句的末尾,只有一个 INSERT声明指表 T1 可以执行一次,并由不同的报表自动增量数代不交错。由TX1所产生的自动增量值 INSERT ... SELECT语句是连续的,和(单)自动增值利用 INSERT声明在TX2是小于或大于那些用于TX1,根据语句首先执行。 只要在SQL语句执行时相同的顺序重演的二进制日志(当使用基于语句的复制,或恢复情况),结果都是一样的因为他们当TX1和TX2第一跑。因此,表级锁直到语句的结束使 INSERT通过使用自动增量安全基于语句的复制语句。然而,那些表级锁的并发性和可扩展性限制当多个事务同时执行INSERT语句。 在前面的例子中,如果没有表级锁,用于自动递增列的值 INSERT在TX2依靠精确的语句执行时。如果 INSERT对TX2执行而 INSERTTX1运行(而不是在它开始之前或之后完成),由两个指定特定的自动增量值 INSERT陈述是不确定的,并可以运行。 下 连续的 锁模式, InnoDB可以避免使用表级 auto-inc 锁 “ 简单的插入 “ 报表所在行数是已知的,并且仍然保持为基于语句的复制确定执行和安全。 如果你没有使用二进制日志重播SQL语句作为恢复或复制部分的 交错 锁定模式可以用来消除所有使用表级 AUTO-INC锁更大的并发性和性能,在成本允许的情况下自动递增编号分配差距的声明和潜在的数据并发执行的语句交错布置。 innodb_autoinc_lock_mode = 1( “ 连续的 “ 锁定模式) 在这种模式下, “ 批量插入 “ 使用专用的 AUTO-INC表级锁和保持它在语句结束。这适用于所有 INSERT ... SELECT, REPLACE ... SELECT,和 LOAD DATA声明.只有一个声明持 auto-inc 锁可以执行一次。如果批量插入操作的源表不同于目标表的 AUTO-INC在目标表锁在一个共享锁被选定的源表中的第一行了。如果源和批量插入操作的目标是相同的表, auto-inc 锁是在共享锁上所有选定的行了。 “ 简单的插入 “ (为要插入的行数是已知的)避免表水平 AUTO-INC由一个互斥体的控制下获得所需的自动增量值的数量(一个轻量级的锁锁),只有分配过程的持续时间, 不 直到语句完成。没有表水平 AUTO-INC锁是使用除非 auto-inc 锁被另一个事务举行。如果另一个事务持有 AUTO-INC锁,一 “ 简单的插入 “ 等待 AUTO-INC锁,如果它是一个 “ 大容量插入 “ 这种锁定模式确保,在存在 INSERT报表所在行数是事先不知道(在自动递增编号为声明的进展),所有自动增量值指定的任何 “ INSERT喜欢 “ 语句是连续的,操作安全的基于语句的复制。 简单地说,这种锁模式显著提高了可扩展性,安全使用基于语句的复制。此外,与 “ 传统 “ 锁定模式,自动增加的数字的任何语句分配 连续的 。有 无变化 在语义比较 “ 传统 “ 任何声明,使用自动增量模式,一个重要的例外。 例外的是 “ 混合模式插入 “ ,在用户提供了一个明确的价值观 AUTO_INCREMENT列一些,但不是全部,在一个多行行 “ 简单的插入 “ 。这种刀片, InnoDB分配更多的自动增量值比行数插入。然而,所有的值自动分配连续产生(因此高于)通过最近执行先前的陈述所产生的自动增量值。 “ 过剩 “ 数据丢失 innodb_autoinc_lock_mode = 2( “ 交错 “ 锁定模式) 在这种锁定模式,没有 “ INSERT喜欢 “ 语句中使用表级 auto-inc 锁,和多个语句可以同时执行。这是最快和最可扩展的锁定模式,但它是 不安全 当使用基于语句的复制或恢复的情况时,SQL语句是从二进制日志重播。 在这种锁定模式,自动增量值保证在所有并发执行的是独特的和单调递增 “ INSERT喜欢 “ 声明.然而,由于多个语句可以同时生成数(即分配数 交错 在陈述),价值观产生的任何语句插入的行可能不连续。 如果唯一的语句的执行是 “ 简单的插入 “ 在要插入的行数是事先已知的,有在一个语句生成的数字没有差距,除了 “ 混合模式插入 “ 。然而,当 “ 批量插入 “ 执行时,有可能在汽车增量值的任何语句分配是。
使用自动增量复制 如果您使用的是基于语句的复制,设置 innodb_autoinc_lock_mode0或1,使用相同的值对主人和奴隶。自动增量值不保证对奴隶一样在主如果使用 innodb_autoinc_lock_mode= 2 (“ 交错 “ )或配置,主人和奴隶都使用相同的锁定模式。 如果您使用的是基于行的或混合格式的复制,所有的自动增量的锁模式是安全的,因为基于行的复制不会对SQL语句的执行顺序敏感(和混合格式使用基于行的复制任何陈述,不安全的基于语句的复制)。 “ 迷路的 “ 自动增量值序列的空白 在所有的锁模式(0, 1,2),如果一个事务产生自动增量值回滚,那些自动增量值 “ 迷路的 “ 。一旦一个值是一个自动递增列生成的,它不能被回滚,是否 “ INSERT喜欢 “ 陈述完毕,是否包含事务回滚。这样的损失值不重复使用。因此,有可能存储在一个值是空白 汽车 一个表列 指定为null或者0 AUTO_INCREMENT专栏 在所有的锁模式(0, 1,2),如果用户指定为零或0 AUTO_INCREMENT柱在 INSERT, InnoDB 将行如果值没有指定,它产生一个新值。 给一个负值 AUTO_INCREMENT专栏 在所有的锁模式(0, 1,2),该自动递增机制的行为是不确定如果你到指定一个负值 AUTO_INCREMENT专栏 如果 AUTO_INCREMENT值变得大于指定的整数类型的最大整数 在所有的锁模式(0,1,2),该自动递增机制的行为是未定义的值,如果较大,可以存储在指定的整数类型的最大整数。 自动增量值的差距 “ 批量插入 “ 与 innodb_autoinc_lock_mode设置为0( “ 传统 “ (1)或 “ 连续的 “ ),任何给定的语句生成的自动增量值是连续的,没有间隙,因为表级 AUTO-INC锁在语句的结尾,只有一个这样的语句可以执行一次。 与 innodb_autoinc_lock_mode设置为2( “ 交错 “ ),有可能产生的自动增加值是空白 “ 批量插入, “ 但如果有concurrently执行只读 “ INSERT喜欢 “ 声明. 锁模式1或2,差距之间可能会发生连续的陈述,因为批量插入的每个语句所需的精确自动增量值的数量可能不被高估是可能的。 自动增加值分配 “ 混合模式插入 “ 考虑一个 “ 混合模式插入, “ 其中一个 “ 简单的插入 “ 指定一些自动增量值(但不是全部)产生的行。这样一个声明的行为不同的锁模式0,1,和2。例如,假设 c1是一个 汽车 列的表 t1,和最新的自动生成的序列号是100。 MySQL的> CREATE TABLE t1 (-> c1 INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,-> c2 CHAR(1)-> ) ENGINE = INNODB;现在,考虑以下 “ 混合模式插入 “ 声明: mysql>
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');与 innodb_autoinc_lock_mode设置为0( “ 传统 “ ),四个新的行: mysql>
SELECT c1, c2 FROM t1 ORDER BY c2;+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+下一个可用的自动增量的数值是103,自动增加值分配一次,不能一下子在语句执行的开始。这个结果是真的是否有并发执行 “ INSERT喜欢 “ 2 . Statements(of any type). 与 innodb_autoinc_lock_mode设置为1( “ 连续的 “ ),四行也: mysql>
SELECT c1, c2 FROM t1 ORDER BY c2;+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+然而,在这种情况下,下一个可用的自动增量值为105,不是103,因为四自动增量值分配在时间的语句的处理,但只有两个用于。这个结果是真的是否有并发执行 “ INSERT喜欢 “ 2 . Statements(of any type). 与 innodb_autoinc_lock_mode设置为方式2( “ 交错 “ ),四个新的行: mysql>
SELECT c1, c2 FROM t1 ORDER BY c2;+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | |x| b | | 5 | c | |y| d | +-----+------+价值观 x和 y是独一无二的,比任何先前生成的行。然而,具体的值 x和 y取决于并发执行的语句生成的自动增量值的数目。 最后,考虑下面的语句,发出最近生成的序列号是100: mysql>
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (101,'c'), (NULL,'d');与任何 innodb_autoinc_lock_mode设置,该语句将生成一个重复键错误23000( 不能写;重复键表 101)由于分配给排 (NULL, 'b')与行插入 (101、C) 失败. 修改 AUTO_INCREMENT在一个序列中的列值 INSERT声明 在MySQL 5.7和更早的版本,修改 AUTO_INCREMENT在一个序列中的列值 INSERT声明可能导致 “ 重复的条目 “ 错误.例如,如果你进行了 UPDATE手术改变了 汽车 一个值大于最大电流自动增量值的列的值,随后 INSERT操作,没有指定一个未使用的自动增量值可能会遇到 “ 重复的条目 “ 错误.在MySQL 8后,如果修改 AUTO_INCREMENT一个值大于最大电流自动增量值的列的值,新值是坚持,和随后的 INSERT操作将自动增加值从新的、更大的价值。这种行为是下面的例子演示了。 MySQL的> CREATE TABLE t1 (-> c1 INT NOT NULL AUTO_INCREMENT,-> PRIMARY KEY (c1)-> ) ENGINE = InnoDB;MySQL的> INSERT INTO t1 VALUES(0), (0), (3);MySQL的> SELECT c1 FROM t1;噢,| C1 | - | | | 1 2 3 | | | - MySQL > UPDATE t1 SET c1 = 4 WHERE c1 = 1;MySQL的> SELECT c1 FROM t1;噢,| C1 | - | | | 2 3 4 | | | - MySQL > INSERT INTO t1 VALUES(0);MySQL的> SELECT c1 FROM t1;- | C1 | - | | | 2 3 4 5 | | | | | -
InnoDB
AUTO_INCREMENT
InnoDB
SELECT MAX(ai_col) FROM table_name FOR UPDATE;
InnoDB
InnoDBINSERTUPDATE
InnoDBtable_name.cfg
AUTO_INCREMENT = NALTER TABLEAUTO_INCREMENT = N
ALTER TABLE ...
AUTO_INCREMENT = N
ROLLBACK
SHOW TABLE STATUSInnoDB
InnoDB
InnoDB
auto_increment_offset
auto_increment_increment
InnoDB
InnoDB
InnoDB允许一个外键引用的任何索引列或一组列。然而,在所引用的表,必须有一个索引引用的列列为 第一 在同一顺序的列 InnoDB目前不支持外键与用户定义的分区表。这意味着没有用户分区 InnoDB 表格可能包含外键引用或列的外键引用。 InnoDB允许外键约束引用唯一的密钥。 这是一个 InnoDB标准的SQL扩展
InnoDB
而 SET DEFAULT由MySQL服务器允许的,它拒绝无效的 InnoDB CREATE TABLE和 ALTER TABLE使用这一条款的声明是不容许的InnoDB表。 如果有在父表中具有相同关键值引用几行, InnoDB行为在外键检查如果其他母行相同的键值不存在。例如,如果你定义了一个 限制 类型约束,并有几个父行子行, InnoDB不允许任何人父行删除。 InnoDB进行级联操作通过深度优先算法,基于记录在对应的外键约束指标。 如果 ON UPDATE CASCADE或 在更新设置空 递归更新 相同的表 它已在级联更新,就像 RESTRICT。这意味着你不能使用自我参照 级联更新 或 ON UPDATE SET NULL运营这是为了防止无限循环产生的级联更新。一个自我指涉 删除设置空 ,另一方面,是可能的,是一种自我参照 ON DELETE CASCADE。连锁经营不能嵌套超过15层。 像MySQL,SQL语句中插入、删除或更新的行数, InnoDB检查 独特 和 FOREIGN KEY约束排排。执行外键检查时, InnoDB 设置共享行级锁在孩子或父母记录它看看。 InnoDB外键约束立即检查;检查不推迟提交事务。根据SQL标准,违约行为应暂缓检查。那是,约束只检查后 整个SQL语句 已被处理。直到 InnoDB实现了延迟约束检查,有些事情是不可能的,如删除一个记录,是指本身使用外键。
InnoDB
InnoDB
一个表最多可包含1017列。虚拟生成的列都包含在这个极限。 一个表最多可包含64 二级指标 索引键前缀长度限制为3072字节 InnoDB表使用 动态 或 COMPRESSED行格式 索引键前缀长度限制为767字节 InnoDB表使用 冗余 或 COMPACT行格式。例如,你可能有一个达到这个极限 列前缀 超过191个字符的索引上 TEXT或 varchar 柱,假设 utf8mb4字符集和每个字符4字节的最大。 尝试使用一个索引键前缀长度超过限制返回一个错误。 适用于索引键前缀也适用于全列索引键的限制。 如果你减少 InnoDB页面大小 对8kb即4KB通过指定 innodb_page_size选择创建MySQL实例时,索引键的最大长度是降低比例,基于16KB的页面大小为3072字节的限制。即最大索引键的长度为1536字节时,页面大小为8KB,768字节时,页面大小是4KB。 最大的16列是多列索引允许。超过限制将返回一个错误。 ERROR 1070 (42000): Too many key parts specified; max 16 parts allowed
最大的行长度,除了可变长度列( VARBINARY, VARCHAR, BLOB和 TEXT),略少于一半的一页为4KB,8KB,16KB、32KB的页面大小。例如,在默认的最大行长度 innodb_page_size16kb的大约是8000字节。对于一个 InnoDB 64KB页面大小,最大长度为16000字节的行。 LONGBLOB和 LONGTEXT列必须小于4GB,和总的行长度,包括 BLOB和 TEXT列,必须小于4GB 如果行不到半页,都是本地存储页面内的。如果超过半页,可变长度列选择外部关闭页面存储到行符合半页描述 第15.11.2,“文件管理” 虽然 InnoDB支持行的大小大于65535字节的内部,MySQL本身施加一个65535行大小限制的所有列的大小: MySQL的> CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),-> c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),-> f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;(4):错误1118排尺寸太大。对于二手台式的行大小的最大值,不可计数的斑点,是65536。你必须改变带来的一些列的文本或斑点 在一些老的操作系统,文件必须小于2GB。这不是一个限制 InnoDB本身,但是如果你需要一个大的空间,配置它使用几个较小的数据文件,而不是一个大的数据文件。 该组合尺寸 InnoDB日志文件可以高达512GB。 最小空间尺寸略大于10MB。最大的表空间的大小取决于 InnoDB页面大小 最大设置尺寸的也是最大尺寸的桌子。 默认的页大小 InnoDB16KB。你可以增加或减少页面大小配置 innodb_page_size选择创建MySQL实例时。 32kb和64KB页面大小的支持,但 ROW_FORMAT=COMPRESSED不支持的页面大小大于16kb。为32kb和64KB页面大小,最大记录大小为16KB。为 innodb_page_size=32k,大小为2MB。为 innodb_page_size=64k,大小为4MB 使用特定的MySQL实例 InnoDB页面大小不能使用数据文件或日志文件的一个实例,使用不同的页面大小。
ANALYZE TABLE确定指标的基数(如显示在 基数 柱 SHOW INDEX通过输出) 随机跳水 在每个索引树并更新相应指标的基数估计。因为这些都只是估计,重复运行 ANALYZE TABLE可以产生不同的数字。这使得 ANALYZE TABLE快 InnoDB 表而不是100%准确的因为它不需要考虑所有的行。 你能做的 统计 收集的 ANALYZE TABLE通过打开更精确、更稳定 innodb_stats_persistent配置选项,解释 第15.6.11.1”配置,持续优化统计参数 。当这个设置被启用,它是重要的是要跑 ANALYZE TABLE在索引列数据的重大变化,因为统计数字是不是周期性地重新计算(如在服务器重启)。 如果持续的统计设置是启用的,你可以改变随机跳数的修改 innodb_stats_persistent_sample_pages系统变量。如果持续的统计设置被禁用,修改 innodb_stats_transient_sample_pages系统变量来代替 MySQL使用索引的基数估计在连接优化。如果一个连接是不正确的方法进行优化,尽量使用 ANALYZE TABLE。在少数情况下, ANALYZE TABLE不产生价值的足够好,你的特殊的表,你可以使用 力量指数 你的疑问迫使某一指标的使用,或者设置 max_seeks_for_key系统变量以确保MySQL喜欢查找索引在表扫描。看到 第b.5.5,“优化问题” 如果语句或事务表上的运行,并 ANALYZE TABLE是运行在同一台再进行一次 ANALYZE TABLE操作,第二 ANALYZE TABLE操作被阻塞直到报表或交易完成。发生此行为的原因 ANALYZE TABLE标志着当前加载的表定义为过时的时候 ANALYZE TABLE完成后运行。新的报表或交易(包括二 ANALYZE TABLE声明)必须加载新的表定义为表缓存,不能发生,直到目前运行报表或交易的完成和旧表的定义被清除。加载多个并发表定义是不支持的。 SHOW TABLE STATUS不提供准确的统计 InnoDB 表除物理尺寸由表保留。行计数仅用于SQL优化的粗略估计。 InnoDB不保持在一个表中的行数可能会因为内部事务 “ 看见 “ 同时行不同的号码。因此, SELECT COUNT(*)陈述只算行到当前事务可见。 有关 InnoDB过程 select count(*) 报表,请参阅 COUNT()描述 第12.19.1,“总(集团)功能描述 在Windows, InnoDB在小写总是存储数据库和表的名称。移动数据库在从UNIX到Windows二进制格式或从Windows到Unix,创建数据库和表使用小写的名字。 一个 AUTO_INCREMENT专栏 ai_col必须定义为一个指数,它是可能执行索引的等值部分 选择最大( ai_col) 在查表获得最大的列值。通常,这是通过使列一些表索引的第一列实现。 InnoDB设置关联的指标最终独占锁 汽车 初始化时预先指定的列 AUTO_INCREMENT在表列 与 innodb_autoinc_lock_mode=0, InnoDB 使用一种特殊的 AUTO-INC表锁模式锁的所在取得并持有到当前的SQL语句结束访问自动递增计数器而。其他客户不能插入表时 auto-inc 表锁。同样的行为发生 “ 批量插入 “ 与 innodb_autoinc_lock_mode=1。表级 auto-inc 锁是没有用的 innodb_autoinc_lock_mode=2。有关更多信息,参见 第15.8.1.5,”auto_increment InnoDB”处理 当一个 AUTO_INCREMENT整数列运行的值,随后 插入 操作返回重复键错误。这是一般的MySQL的行为。 DELETE FROMtbl_name不再生,而是删除表的所有行,一个接一个。 级联外键动作不激活触发器。 你不能创建一个列名称相匹配的内部名称表 InnoDB柱(包括 _分贝_ ROW ID , DB_TRX_ID, _辊_ PTR分贝 ,和 DB_MIX_ID)。这个限制适用于在任何情况下使用字母的名字。 MySQL的> CREATE TABLE t1 (c1 INT, db_row_id INT) ENGINE=INNODB;结论:正确错误(4)列名“db_row_id”
LOCK TABLES获得每桌两锁如果 innodb_table_locks=1(默认)。除了对MySQL层表锁,它还获得了 InnoDB表锁。在没有获得MySQL版本4.1.2 InnoDB 表锁;旧的行为可以选择设置 innodb_table_locks=0。如果没有 InnoDB 表锁了, LOCK TABLES完成即使一些表记录被其他事务锁定。 在MySQL 5.0, innodb_table_locks=0没有效果明确锁定表 LOCK TABLES ... WRITE。它有一个效果表锁定为读或写的 LOCK TABLES ... WRITE隐式(例如,通过触发)或 LOCK TABLES ... READ全部 InnoDB由一个事务持有的锁被释放时,事务提交或中止。因此,它不调用多大意义 LOCK TABLES打开(放) InnoDB 表 autocommit=1因为收购模式 InnoDB 表锁将被立即释放 你不能锁定附加表在一个事务中因为 LOCK TABLES执行隐式 COMMIT和 UNLOCK TABLES对数据的修改交易的限制是96×1023并发事务产生撤销记录。32 128回滚段分配给非重做事务修改临时表和相关对象的日志。这意味着并发修改数据交易的最大数量是96K职业。96k的限制是交易不修改临时表。如果所有的数据修改事务也修改临时表,极限是32k并发事务。
InnoDB
InnoDBInnoDB
当你定义一个 PRIMARY KEY在你的桌子上, InnoDB 使用它作为聚集索引。定义一个主键的每个表的创建。如果没有逻辑的独特的和非空的列或列集,添加一个新的 自增量 列,其值是自动填充 如果未定义 PRIMARY KEY你的表,MySQL定位第一 独特 索引所有键列在哪里 NOT NULL和 InnoDB 使用它作为聚集索引 如果表没有 PRIMARY KEY或合适的 独特 指数, InnoDB在内部产生一个隐藏的聚集索引的命名 gen_clust_index 在合成塔含行ID值。行命令的ID InnoDB指定在这样的表中的行。行ID是一个6字节字段的单调增加,在插入新行。因此,由行ID命令行插入时的物理顺序。
InnoDB
InnoDB
InnoDB
InnoDBInnoDB
InnoDBinnodb_fill_factorinnodb_fill_factor
InnoDBInnoDB
InnoDBinnodb_page_size32k8k
InnoDB
InnoDB
未来的指数增长树页预留空间
innodb_fill_factorinnodb_fill_factorTEXTBLOBinnodb_fill_factor
排序的索引建立全文索引支持
排序的索引生成和压缩表
排序的索引生成重做日志
排序的索引建立和优化统计
FULLTEXTCHARVARCHARTEXT
FULLTEXTCREATE TABLEALTER
TABLECREATE INDEX
MATCH()
... AGAINST
InnoDB
InnoDB
mysql>CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200),FULLTEXT idx (opening_line)) ENGINE=InnoDB;mysql>SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLESWHERE name LIKE 'test/%';+----------+----------------------------------------------------+-------+ | table_id | name | space | +----------+----------------------------------------------------+-------+ | 333 | test/fts_0000000000000147_00000000000001c9_index_1 | 289 | | 334 | test/fts_0000000000000147_00000000000001c9_index_2 | 290 | | 335 | test/fts_0000000000000147_00000000000001c9_index_3 | 291 | | 336 | test/fts_0000000000000147_00000000000001c9_index_4 | 292 | | 337 | test/fts_0000000000000147_00000000000001c9_index_5 | 293 | | 338 | test/fts_0000000000000147_00000000000001c9_index_6 | 294 | | 330 | test/fts_0000000000000147_being_deleted | 286 | | 331 | test/fts_0000000000000147_being_deleted_cache | 287 | | 332 | test/fts_0000000000000147_config | 288 | | 328 | test/fts_0000000000000147_deleted | 284 | | 329 | test/fts_0000000000000147_deleted_cache | 285 | | 327 | test/opening_lines | 283 | +----------+----------------------------------------------------+-------+
DOC_ID
innodb_ft_sort_pll_degree
fts_table_idtest/opening_linestest/opening_lines
index_idtest/fts_0000000000000147_00000000000001c9_index_1opening_linesINFORMATION_SCHEMA.INNODB_INDEXES
MySQL的> SELECT index_id, name, table_id, space from INFORMATION_SCHEMA.INNODB_INDEXESWHERE index_id=457;我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,
FULLTEXT
FTS_DOC_IDFTS_DOC_ID
fts_*_deleted和 (FTS)* * * * * * * * * * * * * * * * 包含文档ID(doc_id),删除,但其数据尚未从全文索引中删除文件。这个 fts_*_deleted_cache是在记忆版 fts_ * _deleted 表 fts_*_being_deleted和 fts_ * _being_deleted_cache 包含文档ID(doc_id),被删除的数据正在被从全文索引删除程序文件。这个 fts_*_being_deleted_cache表是在记忆版 fts_ * _being_deleted 表 fts_*_config商店的内部状态的信息 FULLTEXT指数最重要的是,它的商店 fts_synced_doc_id ,确定被解析并刷新到磁盘文件。崩溃恢复的情况下, FTS_SYNCED_DOC_ID值是用来确定尚未刷新到磁盘,文件可以重新解析和重新添加到文件 全文 索引缓存。这个表中查看数据,查询 INFORMATION_SCHEMA.INNODB_FT_CONFIG表
FULLTEXTFULLTEXTINFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE
innodb_ft_cache_sizeinnodb_ft_total_cache_size
InnoDBFTS_DOC_IDInnoDB
FTS_DOC_ID
MySQL的> CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200)) ENGINE=InnoDB;
CREATE FULLTEXT INDEXFTS_DOC_ID
MySQL的> CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);查询好,0行受影响,警告(0.19秒)记录:0 0副本:警告:1mysql > SHOW WARNINGS;--------- ------ -------------------------------------------------- |水平|代码|消息| --------- ------ -------------------------------------------------- |警告| 124 | InnoDB表添加列fts_doc_id重建| --------- ------ --------------------------------------------------
ALTER TABLECREATE TABLEInnoDB
FTS_DOC_IDCREATE TABLECREATE FULLTEXT
INDEXInnoDBFTS_DOC_IDFTS_DOC_IDBIGINT UNSIGNED NOT NULL
FTS_DOC_IDAUTO_INCREMENT
MySQL的> CREATE TABLE opening_lines (FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200)) ENGINE=InnoDB;
FTS_DOC_IDFTS_DOC_ID
FTS_DOC_ID_INDEX
mysql> CREATE UNIQUE INDEX FTS_DOC_ID_INDEX on opening_lines(FTS_DOC_ID);
FTS_DOC_ID_INDEX
FTS_DOC_ID_INDEX
FTS_DOC_ID
FTS_DOC_ID
DOC_IDFTS_*_DELETEDinnodb_optimize_fulltext_only=ON
InnoDBFULLTEXTFULLTEXT
MySQL的> CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200),FULLTEXT idx (opening_line)) ENGINE=InnoDB;MySQL的> BEGIN;MySQL的> INSERT INTO opening_lines(opening_line,author,title) VALUES('Call me Ishmael.','Herman Melville','Moby-Dick'),('A screaming comes across the sky.','Thomas Pynchon','Gravity\'s Rainbow'),('I am an invisible man.','Ralph Ellison','Invisible Man'),('Where now? Who now? When now?','Samuel Beckett','The Unnamable'),('It was love at first sight.','Joseph Heller','Catch-22'),('All this happened, more or less.','Kurt Vonnegut','Slaughterhouse-Five'),('Mrs. Dalloway said she would buy the flowers herself.','Virginia Woolf','Mrs. Dalloway'),('It was a pleasure to burn.','Ray Bradbury','Fahrenheit 451');MySQL的> SELECT COUNT(*) FROM opening_lines WHERE MATCH(opening_line) AGAINST('Ishmael');---------- |计数(*)| ---------- | 0 | ---------- MySQL > COMMIT;MySQL的> SELECT COUNT(*) FROM opening_lines WHERE MATCH(opening_line) AGAINST('Ishmael');---------- |计数(*)| ---------- | 1 | ----------
InnoDBINFORMATION_SCHEMA
FULLTEXTINNODB_INDEXESINNODB_TABLES
InnoDB
InnoDB
InnoDBROW_FORMAT=COMPRESSEDCREATE TABLEALTER TABLE
InnoDBROW_FORMAT=COMPRESSEDinnodb_page_size
CREATE TABLEALTER TABLE
KEY_BLOCK_SIZEKEY_BLOCK_SIZECREATE TABLEALTER TABLE
KEY_BLOCK_SIZE
创建一个压缩的表每表表空间
innodb_file_per_tablemy.iniSET
innodb_file_per_tableROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZECREATE TABLEALTER TABLE
SET GLOBAL innodb_file_per_table=1; CREATE TABLE t1 (c1 INT PRIMARY KEY) ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
创建一个压缩的表中的一个通用表
FILE_BLOCK_SIZEinnodb_page_sizeCREATE TABLEALTER TABLEFILE_BLOCK_SIZE/1024innodb_page_size=16384FILE_BLOCK_SIZE=8192KEY_BLOCK_SIZE
innodb_page_sizeKEY_BLOCK_SIZE
MySQL的> CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的> CREATE TABLE t4 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
笔记
在MySQL 8,用于压缩的表的表空间文件使用的物理页面大小而创建的 InnoDB页面大小,使空压表比在以前的MySQL释放表空间文件的初始大小。 如果你指定 ROW_FORMAT=COMPRESSED,你可以省略 key_block_size ;的 KEY_BLOCK_SIZE设置默认值的一半 innodb_page_size价值 如果你指定一个有效的 KEY_BLOCK_SIZE价值,可以省略 ROW_FORMAT=COMPRESSED压缩是自动启用 确定最佳值 KEY_BLOCK_SIZE,通常你创建同一桌几份与此条款不同的值,然后测量所得到的尺寸 鸡传染性法氏囊病 文件和查看每个执行与现实 工作量 。对于一般的表空间,记住删除表不减少一般表空间的大小 .ibd文件,也不能返回到操作系统的磁盘空间。有关更多信息,参见 第15.7.10”一般,InnoDB表空间” 这个 KEY_BLOCK_SIZE价值作为一个提示;不同的大小可以用 InnoDB 如果需要的话。For File - per-table Tableaces,the KEY_BLOCK_SIZE只能小于或等于 innodb_page_size价值。如果你指定一个值大于 innodb_page_size值,指定的值将被忽略,一个警告,并 key_block_size 将一半的 innodb_page_size价值。如果 innodb_strict_mode=ON,指定一个无效的 KEY_BLOCK_SIZE值返回一个错误。对于一般的表空间,有效 key_block_size 值取决于 FILE_BLOCK_SIZE表空间的设置。有关更多信息,参见 第15.7.10”一般,InnoDB表空间” InnoDB支持为32K和64K的页大小,但这些页面大小不支持压缩。有关更多信息,请参阅 innodb_page_size文档 默认的压缩大小 InnoDB数据 网页 16KB。根据期权价值的组合,MySQL使用1KB,2KB,4KB,8kb页面大小,16KB的表空间的数据文件( .ibd文件)。实际的压缩算法不受影响 key_block_size 价值;价值决定每个压缩块有多大,这反过来又影响了多少行可以装入每个压缩页。 创建压缩表每表表空间文件时,设置 KEY_BLOCK_SIZE等于 InnoDB 页面大小 通常不在多,压缩效果。例如,设置 KEY_BLOCK_SIZE=16通常不会造成多大的压缩,因为正常 InnoDB 页面大小为16KB。此设置还可以与许多长表是有用的 BLOB, VARCHAR或 TEXT列,因为这样的价值观往往做压缩,因此可能需要更少的 溢出页 描述 第15.9.1.5,“如何压缩InnoDB表” 。For General Tableaces,a KEY_BLOCK_SIZE价值等于 InnoDB 页面大小是不允许的。有关更多信息,参见 第15.7.10”一般,InnoDB表空间” 一个表的所有指标(包括 聚集索引 )都使用相同的页面大小压缩,指定的 CREATE TABLE或 修改表 声明。表格的属性,如 ROW_FORMAT和 key_block_size 是不是部分的 CREATE INDEX语法 InnoDB 表,并且如果他们指定的忽视(虽然,如果指定,它们将出现在输出 SHOW CREATE TABLE声明) 性能相关的配置选项,看 第15.9.1.3,“调整压缩InnoDB表”
压缩表的限制
压缩表不能存储在 InnoDB系统表空间 一般的表空间可以包含多个表,但压缩和非压缩表不能共存于相同的表空间。 压缩应用于整个表和所有相关的指标,而不是个人的行,尽管条款名称 ROW_FORMATInnoDB不支持压缩的临时表。什么时候 innodb_strict_mode启用(默认), CREATE TEMPORARY TABLE如果返回错误 ROW_FORMAT=COMPRESSED或 KEY_BLOCK_SIZE指定。如果 innodb_strict_mode是残疾人,发出警告和临时表是使用非压缩行格式创建。同样的限制适用于 ALTER TABLE对临时表的操作
当使用压缩
数据特性和压缩
CHARTEXT
gzip
.ibd
USE test;SET GLOBAL innodb_file_per_table=1;SET GLOBAL autocommit=0;-- Create an uncompressed table with a million or two rows.CREATE TABLE big_table AS SELECT * FROM information_schema.columns;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;INSERT INTO big_table SELECT * FROM big_table;COMMIT;ALTER TABLE big_table ADD id int unsigned NOT NULL PRIMARY KEY auto_increment;SHOW CREATE TABLE big_table\Gselect count(id) from big_table;-- Check how much space is needed for the uncompressed table.\! ls -l data/test/big_table.ibdCREATE TABLE key_block_size_4 LIKE big_table;ALTER TABLE key_block_size_4 key_block_size=4 row_format=compressed;INSERT INTO key_block_size_4 SELECT * FROM big_table;commit;-- Check how much space is needed for a compressed table-- with particular compression settings.\! ls -l data/test/key_block_size_4.ibd
-rw-rw---- 1 cirrus staff 310378496 Jan 9 13:44 data/test/big_table.ibd -rw-rw---- 1 cirrus staff 83886080 Jan 9 15:10 data/test/key_block_size_4.ibd
简单的测试,使用无压缩表MySQL实例并运行查询 INFORMATION_SCHEMA.INNODB_CMP表 更详细的测试涉及多个压缩表的工作量,运行查询 INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表因为在统计 每_ _ CMP _ InnoDB索引 表格收集成本,您必须启用配置选项 innodb_cmp_per_index_enabled在查询表,你可能会限制这种测试开发服务器或非关键 从服务器 运行一些典型的SQL语句对压缩表你测试。 考察成功的压缩操作比整体压缩操作通过查询 INFORMATION_SCHEMA.INNODB_CMP或 INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表,比较 compress_ops 到 COMPRESS_OPS_OK如果高比例压缩操作成功完成,表可能是一个压缩的很好的候选人。 如果你得到一个高比例 压缩失败 ,你可以调整 innodb_compression_level, innodb_compression_failure_threshold_pct,和 innodb_compression_pad_pct_max选项中所描述的 第15.9.1.6,“压缩的OLTP工作负载” 进一步的试验和尝试
应用数据库的压缩与压缩
在数据库压缩
LIKE
在应用压缩
混合的方法
负载特性和压缩
BLOBINSERTDELETE
形态特征和压缩
选择压缩页面的大小
KEY_BLOCK_SIZE=8
INNODB_CMP
INNODB_CMP_PER_INDEXINNODB_CMP_PER_INDEXinnodb_cmp_per_index_enabledINNODB_CMP_PER_INDEX
INNODB_CMPINNODB_CMP_PER_INDEX
INSERTDELETE
COMPRESS_OPS_OKKEY_BLOCK_SIZE
压缩算法
InnoDB
.idbinnodb_compression_level
InnoDB存储和数据压缩
VARCHARTEXT
B树的页面压缩
innodb_compression_failure_threshold_pctinnodb_compression_pad_pct_max
innodb_strict_modeCREATE TABLECREATE INDEX
innodb_strict_modeUPDATEALTER TABLEROW_FORMAT=DYNAMICROW_FORMAT=COMPACT
innodb_strict_modeinnodb_strict_mode
压缩的blob,VARCHAR和文本列
BLOBVARCHARTEXT
ROW_FORMAT=DYNAMICROW_FORMAT=COMPRESSEDBLOBTEXTVARCHAR
ROW_FORMAT=REDUNDANTROW_FORMAT=COMPACTBLOBVARCHARTEXT
COMPRESSEDBLOBVARCHAR
BLOBVARCHARTEXT
压缩和InnoDB缓冲池
InnoDBinnodb_page_sizeInnoDB
压缩和InnoDB重做日志文件
zlib
innodb_file_per_tableinnodb_file_per_table
InnoDBOLTPINSERTUPDATEDELETE
innodb_compression_level让你把压力上升或下降的程度。较高的值可以容纳更多的数据到一个存储设备,在更多的CPU开销的费用在压缩。一个较低的值可以减少CPU开销在存储空间并不重要,或者你期望的数据是不可压缩的。 innodb_compression_failure_threshold_pct指定一个截止点 压缩失败 在更新到一个压缩的表。当通过此阈值,MySQL开始在每一个新的压缩页面留下更多的自由空间,动态调整量的自由空间到页面大小指定的百分比 innodb_compression_pad_pct_maxinnodb_compression_pad_pct_max让你调整最大金额的预留空间,在每个 网页 记录压缩的行,而不需要再压缩整个页面。更高的价值,更可以记录变化没有recompressing页。MySQL使用自由空间变量的金额为每个压缩表内页,只有当指定的比例压缩操作 “ 失败 “ 在运行时,需要一个昂贵的操作拆分压缩页。 innodb_log_compressed_pages让你禁用图片写作 再compressed 网页 到 重做日志文件 。重新压缩时可能发生的变化对压缩后的数据。这个选项是默认启用的预防腐败可能发生的,如果一个不同版本的 zlib压缩算法应用在恢复。如果你是肯定的 zlib 版本将不会改变,禁用 innodb_log_compressed_pages为了减少工作量,修改压缩数据重做日志生成。
innodb_buffer_pool_size
文件压缩合成器与误差
innodb_strict_modeROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZECREATE
TABLEALTER TABLEinnodb_file_per_table
错误1031(hy000):“T1”不表的存储引擎有这个选项
innodb_strict_modeROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZECREATE
TABLEALTER TABLEinnodb_file_per_table
MySQL的> SHOW WARNINGS;+---------+------+---------------------------------------------------------------+| Level | Code | Message |+---------+------+---------------------------------------------------------------+| Warning | 1478 | InnoDB: KEY_BLOCK_SIZE requires innodb_file_per_table. || Warning | 1478 | InnoDB: ignoring KEY_BLOCK_SIZE=4. || Warning | 1478 | InnoDB: ROW_FORMAT=COMPRESSED requires innodb_file_per_table. || Warning | 1478 | InnoDB: assuming ROW_FORMAT=DYNAMIC. |+---------+------+---------------------------------------------------------------+
mysqldumpROW_FORMAT=DYNAMIC
innodb_file_per_table
KEY_BLOCK_SIZECOMPRESSEDROW_FORMATKEY_BLOCK_SIZE
InnoDB: ignoring KEY_BLOCK_SIZE= |
innodb_strict_modeROW_FORMAT
ROW_FORMATCREATE TABLEALTER TABLE
ROW_FORMAT=?REDUNDANT | ROW_FORMAT=COMPACT | |
ROW_FORMAT=?COMPACT | ||
ROW_FORMAT=?DYNAMIC | ||
ROW_FORMAT=?COMPRESSED | ||
KEY_BLOCK_?SIZE= | ROW_FORMAT=COMPRESSEDInnoDB |
CREATE TABLEALTER TABLE
innodb_strict_modeinnodb_strict_modeSHOW ERRORS
MySQL的> CREATE TABLE x (id INT PRIMARY KEY, c INT)-> ENGINE=INNODB KEY_BLOCK_SIZE=33333;错误1005(hy000):无法创建表测试。X”(错误:1478)MySQL > SHOW ERRORS;+-------+------+-------------------------------------------+| Level | Code | Message |+-------+------+-------------------------------------------+| Error | 1478 | InnoDB: invalid KEY_BLOCK_SIZE=33333. || Error | 1005 | Can't create table 'test.x' (errno: 1478) |+-------+------+-------------------------------------------+
ROW_FORMAT | ||
|---|---|---|
ROW_FORMAT=REDUNDANT | REDUNDANT | |
ROW_FORMAT=COMPACT | COMPACT | |
ROW_FORMAT=COMPRESSEDROW_FORMAT=DYNAMICKEY_BLOCK_SIZE | innodb_file_per_table | the default row format for file-per-table tablespaces; the
specified row format for general tablespaces |
KEY_BLOCK_SIZE | KEY_BLOCK_SIZE | |
ROW_FORMAT=COMPRESSED | KEY_BLOCK_SIZE | COMPRESSED |
KEY_BLOCK_SIZECOMPACT | KEY_BLOCK_SIZE | REDUNDANTDYNAMIC |
ROW_FORMATCOMPACTCOMPRESSED |
innodb_strict_modeROW_FORMATONOFF
KEY_BLOCK_SIZESHOW CREATE
TABLE
SQL压缩语法警告和错误一般表空间
如果 FILE_BLOCK_SIZE不是一般的表空间定义在表空间创建表空间不能包含压缩表。如果你想添加一个压缩表,返回一个错误,如下面的示例所示: MySQL的> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;MySQL的> CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8;错误1478(hy000):InnoDB表空间TS1:` `不能包含一个压缩的表 试图添加一个无效的表 KEY_BLOCK_SIZE一个总的表空间返回一个错误,如下面的示例所示: MySQL的> CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;MySQL的> CREATE TABLE t2 (c1 INT PRIMARY KEY) TABLESPACE ts2 ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=4;错误1478(hy000):InnoDB:表空间` TS2 `采用块大小为8192 cannotcontain物理页面大小4096桌 表空间(tablespace)for general,the KEY_BLOCK_SIZE该表必须是相等的 file_block_size 该表分为1024。例如,如果 FILE_BLOCK_SIZE该表空间的8192, key_block_size 该表必须是8 试图添加一个压缩行格式一般表空间用于存储压缩表表返回一个错误,如下面的示例所示: mysql>
CREATE TABLESPACE `ts3` ADD DATAFILE 'ts3.ibd' FILE_BLOCK_SIZE = 8192 Engine=InnoDB;mysql>CREATE TABLE t3 (c1 INT PRIMARY KEY) TABLESPACE ts3 ROW_FORMAT=COMPACT;ERROR 1478 (HY000): InnoDB: Tablespace `ts3` uses block size 8192 and cannot contain a table with physical page size 16384
innodb_strict_modeinnodb_strict_mode
InnoDBCOMPRESSIONCREATE TABLEALTER TABLELZ4
支持的平台
RHEL 7和来源的分布,使用的内核版本3.10.0-123或更高 有机电致发光(uek2)内核版本5.10或更高2.6.39 OEL 6.5(uek3)内核版本3.8.13或更高 OEL 7内核版本3.8.13或更高 sle11 3.0-x内核版本 sle12 3.12-x内核版本 3.0-x oes11内核版本 14.0.4 LTS Ubuntu内核版本3.13或更高版本 12.0.4 LTS Ubuntu内核版本3.2或更高版本 Debian 7内核版本3.2或更高版本
如何压缩网页作品
孔的大小对Linux
InnoDBinnodb_page_size=16K
孔的大小在Windows
InnoDB
innodb_page_size
innodb_page_sizeinnodb_page_size
使页面压缩
COMPRESSIONCREATE TABLE
CREATE TABLE t1 (c1 INT) COMPRESSION="zlib";
ALTER TABLEALTER TABLE ...
COMPRESSIONOPTIMIZE TABLE
ALTER TABLE t1 COMPRESSION="zlib";OPTIMIZE TABLE t1;
禁用页面压缩
COMPRESSION=NoneALTER TABLECOMPRESSION=NoneOPTIMIZE TABLECOMPRESSION=None
ALTER TABLE t1 COMPRESSION="None"; OPTIMIZE TABLE t1;
网页压缩元数据
INFORMATION_SCHEMA.INNODB_TABLESPACES
FS_BLOCK_SIZE文件系统:the block size,which is the unit size used for孔穿孔。 FILE_SIZE:文件的大小,它代表了文件的最大大小,压缩。 ALLOCATED_SIZE“The actual size of the file,which is the amount of space alloated on disk .”
ls -l
tablespace_name.ibdALLOCATED_SIZEdu --block-size=1tablespace_name.ibd--block-size=1ls -l
SHOW CREATE TABLELz4
INFORMATION_SCHEMA.INNODB_TABLESPACES
# Create the employees table with Zlib page compressionCREATE TABLE employees ( emp_no INT NOT NULL, birth_date DATE NOT NULL, first_name VARCHAR(14) NOT NULL, last_name VARCHAR(16) NOT NULL, gender ENUM ('M','F') NOT NULL, hire_date DATE NOT NULL, PRIMARY KEY (emp_no)) COMPRESSION="zlib";# Insert data (not shown) # Query page compression metadata in INFORMATION_SCHEMA.INNODB_TABLESPACES mysql>SELECT SPACE, NAME, FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE FROMINFORMATION_SCHEMA.INNODB_TABLESPACES WHERE NAME='employees/employees'\G*************************** 1。行***************************空间:45name:员工/ employeesfs_block_size:4096file_size:23068672allocated_size:19415040 网页压缩的局限性和使用说明
网页压缩被禁用,如果文件系统的块大小(或Windows压缩单元尺寸)* 2 > innodb_page_size网页压缩不是驻留在共享表空间,表支持,包括系统表空间,临时表空间,和一般的表空间。 网页压缩不撤销表空间支持日志。 网页压缩不支持日志页。 R树的页面,这是用于空间索引,不压缩。 属于压缩表页( ROW_FORMAT=COMPRESSED)留下的是 在恢复过程中,更新页面写入非压缩格式。 加载一个页面压缩空间的服务器上不支持压缩算法被用来使I/O错误。 在降级到较早版本的MySQL不支持网页压缩,解压缩,使用页面压缩功能表。解压缩一个表,运行 ALTER TABLE ... COMPRESSION=None和 OPTIMIZE TABLE页面压缩的表空间可以复制Windows和Linux服务器之间如果压缩算法被用来提供服务器。 保存网页压缩时压缩空间移动页面文件从一个主机到另一个需要保留稀疏文件的效用。 更好的网页压缩可实现对Fusion-io的硬件nvmfs比在其他平台上,为nvmfs利用冲孔功能。 使用页面压缩功能与大 InnoDB页面大小和相对较小的文件系统块的大小可能会导致写入放大。例如,一个最大的 InnoDB 有一个4KB的文件系统的块大小64KB页面可以提高压缩也可以增加缓冲池的需求,从而增加了I / O和潜在的写入放大。
InnoDB
BLOB
InnoDB
innodb_default_row_formatROW_FORMATROW_FORMAT=DEFAULT
ROW_FORMATCREATE TABLEALTER TABLE
CREATE TABLE t1 (c1 INT) ROW_FORMAT=DYNAMIC;
ROW_FORMATROW_FORMAT=DEFAULT
innodb_default_row_format
MySQL的> SET GLOBAL innodb_default_row_format=DYNAMIC;
innodb_default_row_formatCOMPACTCOMPRESSEDCREATE TABLEALTER TABLEinnodb_default_row_format
mysql> SET GLOBAL innodb_default_row_format=COMPRESSED;
ERROR 1231 (42000): Variable 'innodb_default_row_format'
can't be set to the value of 'COMPRESSED'
innodb_default_row_formatROW_FORMAT=DEFAULTCREATE TABLEinnodb_default_row_format
创建表T1(C1型);
CREATE TABLE t2 (c1 INT) ROW_FORMAT=DEFAULT;
ROW_FORMATROW_FORMAT=DEFAULTinnodb_default_row_format
ALTER
TABLEALGORITHM=COPYALTER
TABLEALGORITHM=INPLACEOPTIMIZE TABLE
mysql>SELECT @@innodb_default_row_format;+-----------------------------+ | @@innodb_default_row_format | +-----------------------------+ | dynamic | +-----------------------------+ mysql>CREATE TABLE t1 (c1 INT);mysql>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE 'test/t1' \G*************************** 1. row *************************** TABLE_ID: 54 NAME: test/t1 FLAG: 33 N_COLS: 4 SPACE: 35 ROW_FORMAT: Dynamic ZIP_PAGE_SIZE: 0 SPACE_TYPE: Single mysql>SET GLOBAL innodb_default_row_format=COMPACT;mysql>ALTER TABLE t1 ADD COLUMN (c2 INT);mysql>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE 'test/t1' \G*************************** 1. row *************************** TABLE_ID: 55 NAME: test/t1 FLAG: 1 N_COLS: 5 SPACE: 36 ROW_FORMAT: Compact ZIP_PAGE_SIZE: 0 SPACE_TYPE: Single
REDUNDANTDYNAMIC
这个 REDUNDANT和 粉盒 行格式支持的最大索引键前缀长度767字节,而 DYNAMIC和 压缩的 行格式支持一个索引键前缀长度为3072字节。在复制的环境,如果 innodb_default_row_format是集 动态 在主设置 COMPACT对奴隶,以下DDL语句,而没有显式定义行格式,成功在主但失败的奴隶: 创建表T1(C1主关键字,C2 varchar(5000),关键I1(C2(3070))); 相关的信息,看 第15.8.1.7”限制,InnoDB表” 进口表不在一个模式失配误差定义行格式结果明确如果 innodb_default_row_format设置在源服务器和目标服务器上的设置。更多信息,参考大纲中的局限性 第15.7.6,“每表表空间文件复制到另一个实例”
SHOW TABLE STATUSINFORMATION_SCHEMA.TABLES
SELECT * FROM information_schema.innodb_tables,名字像“试验/T1的G
InnoDB
ROW_FORMAT=DYNAMICROW_FORMAT=COMPRESSEDInnoDBVARCHARVARBINARYBLOBTEXTCHAR(255)
InnoDBTEXTBLOB
DYNAMICREDUNDANTDYNAMIC
COMPRESSEDCOMPRESSEDCOMPRESSED
DYNAMIC
COMPRESSEDCOMPRESSEDinnodb_file_per_tableinnodb_file_per_table
DYNAMICinnodb_file_per_tableALTER
TABLETABLESPACE [=] innodb_systemCREATE
TABLEinnodb_file_per_tableinnodb_file_per_tableTABLESPACE [=] innodb_systemDYNAMIC
InnoDBinnodb_strict_modeCREATE TEMPORARY
TABLEROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZEinnodb_strict_mode
DYNAMICCOMPACTCHAR
InnoDBREDUNDANTVARCHARVARBINARYBLOBTEXTInnoDButf8mb4
COMPACTBLOB
DYNAMICinnodb_default_row_format
REDUNDANT
InnoDB
InnoDB
背景控制的金额所使用的I / O,以改善查询性能。 启用或禁用功能,提供额外的耐用性,以增加我的费用/ O. 组织表成许多小文件,几个大的文件,或两者的组合。 平衡大小的重做日志文件,对I/O活动发生时,日志文件变满。 如何识别一个最优的查询性能表。
InnoDBInnoDB
InnoDB
在顺序读吧,如果 InnoDB注意,顺序在表空间段的访问模式,它提前上岗一批读取数据库页的I/O系统。 在随机读吧,如果 InnoDB注意到在一个表空间的一些地区似乎被完全读入缓冲池的过程中,揭示了剩余的读取I/O系统。
InnoDBinnodb_doublewrite=ON
InnoDBInnoDB
innodb_flush_method
innodb_data_file_pathInnoDB
innodb_file_per_table
CREATE TABLESPACE
页,extents,段,和tablespaces
innodb_page_sizeinnodb_page_size
InnoDB
InnoDBInnoDB
InnoDB
InnoDB
SHOW TABLE STATUSInnoDB
InnoDB
如何页表行
innodb_page_size
紧凑和多余的行格式 当可变长度列为对外关闭的页面存储, InnoDB商店的前768个字节的局部在列,其余的外部为溢出页。每一列都有自己的页表溢出。768字节的前缀是伴随着一个20字节的值存储的真正的列长度和点到溢出的列表,其余的储存的价值。看到 第15.10.4,紧凑和多余的行格式” 动态压缩行格式 当可变长度列为对外关闭的页面存储, InnoDB存储一个20字节指针在排,其余的外部为溢出页。看到 第15.10.3,动态压缩行格式”
如何检查处理工作
InnoDBInnoDB
InnoDB
InnoDB
SELECT COUNT(*) FROM t WHERE non_indexed_column <> 12345;
ALTER TABLE
修改表 tbl_nameENGINE=INNODB
ALTER TABLE
tbl_name FORCE
ALTER TABLE
tbl_name ENGINE=INNODBALTER TABLE
tbl_name FORCE
InnoDB
InnoDBinnodb_file_per_tableTRUNCATE TABLE
.ibdInnoDBinnodb_file_per_table=OFFInnoDB
innodb_file_per_table=OFF
在繁忙的生产环境,提高响应速度和可用性,在做一张桌子不可数分钟或数小时是不实际的。 就地操作,能够调节性能和并发性之间的平衡在DDL操作使用 LOCK条款.看到 锁定条款 更少的磁盘空间的使用和I/O开销比表复制方法。
ALGORITHM=INSTANT
ALGORITHMALTER TABLE
修改表 tbl_name添加主键( column), ALGORITHM=INPLACE, LOCK=NONE;
LOCKLOCK=DEFAULTALGORITHM
为了避免不小心使表无法读取,写入,或两者,在一个地方 ALTER TABLE操作时,指定的条款 ALTER TABLE声明如 LOCK=NONE(允许读取和写入)或 LOCK=SHARED(允许读取)。运行停止立即如果并发请求的水平是不可用的。 比较性能之间的算法,运行一个语句 ALGORITHM=INSTANT, ALGORITHM=INPLACE和 ALGORITHM=COPY。你也可以运行的声明 old_alter_table配置选项允许使用武力 ALGORITHM=COPY为了避免服务器与 ALTER TABLE复制表的操作,包括 ALGORITHM=INSTANT或 ALGORITHM=INPLACE。声明停止立即如果它不能使用指定的算法。
FULLTEXT | |||||
SPATIAL | |||||
语法和用法说明
创建或添加辅助索引 CREATE INDEX
nameONtable(col_list);修改表 tbl_name添加索引 name( col_list); 桌子上仍然可以阅读并在创建索引时,写操作。这个 CREATE INDEX声明结束后,所有的交易都访问表的完成,使索引的初始状态反映表最新内容。 加二级指标在线DDL支持意味着你可以创建和加载速度表和相关的索引创建的表没有二级指标的全过程,然后将二级指标后加载数据。 新创建的辅助索引只包含下表中的数据时 CREATE INDEX或 ALTER TABLE语句执行完毕。它不包含任何未提交的值,值的老版本,或值标记为删除,但尚未从旧的索引中删除。 一些因素影响性能,空间的使用,以及该操作语义。详情见 第15.12.6,“在线DDL的局限性” 删除索引 DROP INDEX
nameONtable;修改表 tbl_name删除索引 name; 桌子上仍然可以读取,而指数正在下降的写操作。这个 DROP INDEX声明结束后,所有的交易都访问表的完成,使索引的初始状态反映表最新内容。 重命名索引 ALTER TABLE
tbl_nameRENAME INDEXold_index_nameTOnew_index_name, ALGORITHM=INPLACE, LOCK=NONE;添加一个 FULLTEXT指数 【解释】:Create FullText Index name在表( column); 添加第一 FULLTEXT索引重建表如果没有定义 _ FTS _ doc ID 专栏额外的 FULLTEXT所述的反应可能不复存在。 添加一个 SPATIAL指数 CREATE TABLE geom (g GEOMETRY NOT NULL);ALTER TABLE geom ADD SPATIAL INDEX(g), ALGORITHM=INPLACE, LOCK=SHARED;
添加第一 FULLTEXT索引重建表如果没有定义 _ FTS _ doc ID 专栏额外的 FULLTEXT所述的反应可能不复存在。 不断变化的指数型( USING {BTREE | HASH}) 修改表 tbl_name索引I1,添加索引I1( key_part,...) USING BTREE, ALGORITHM=INSTANT;
语法和用法说明
添加主键 ALTER TABLE
tbl_nameADD PRIMARY KEY (column), ALGORITHM=INPLACE, LOCK=NONE;重建表的地方。数据重组的基本上,使它成为一个昂贵的操作。 ALGORITHM=INPLACE不允许在一定条件下,如果列必须转换成 不为空 重组 聚集索引 总是需要表的数据复制。因此,它是最好的定义 primary key 当你创建一个表,而不是发行 ALTER TABLE ... ADD PRIMARY KEY后来 当你创建一个 UNIQUE或 主键 索引,MySQL必须做一些额外的工作。为 UNIQUE索引,MySQL检查表不包含重复的值的关键。对于一个 主键 索引,MySQL也检查没有的 PRIMARY KEY列包含一个 无效的 当你添加一个主键使用 ALGORITHM=COPY子句,MySQL转换 无效的 在相关的列值为默认值:0数字、字符的列和斑点空字符串,并为0000-00-00 00:00:00 DATETIME。这是一种不规范的行为,Oracle建议你不依赖。添加一个主键使用 ALGORITHM=INPLACE只允许当 SQL_MODE设置包括 strict_trans_tables 或 strict_all_tablesWhen the标志; sql_mode 设置严格的, ALGORITHM=INPLACE是允许的,但声明仍然可以如果要求主键列包含失败 无效的 价值观。这个 ALGORITHM=INPLACE行为更加符合标准 如果你创建一个表没有主键, InnoDB选择一个你可以第一 独特 关键定义 NOT NULL列,或一个系统生成的密钥。为了避免不确定性和一个额外的隐藏列的潜在空间要求,指定 主键 条款的一部分 CREATE TABLE声明 MySQL通过现有的数据从原表复制到一个临时表,需要创建一个新的聚集索引的索引结构。一旦数据完全复制到临时表,原表被不同的临时表的名字。临时表的聚集索引包含新更名为与原表的名称,和原来的表从数据库中删除了。 网络性能增强,适用于操作的二级指标不适用于主键索引。InnoDB表的行存储在 聚集索引 组织基于 主键 ,形成了一些数据库系统调用 “ 索引组织表 “ 。因为表结构是紧密联系在一起的主键,重新定义主键仍然需要复制的数据。 当对主键的操作使用 ALGORITHM=INPLACE,尽管数据仍然是复制,它比使用更高效 ALGORITHM=COPY因为: 没有撤消或重做日志记录相关要求 ALGORITHM=INPLACE。这些操作DDL语句,使用添加开销 ALGORITHM=COPY二次索引项进行预排序,因此可以加载顺序。 改变缓冲区是没有用的,因为没有随机访问插入辅助索引。
在落水primary key ALTER TABLE
tbl_nameDROP PRIMARY KEY, ALGORITHM=COPY;只有 ALGORITHM=COPY支持删除主键不需要增加一个新的一样 修改表 声明 删除主键和添加另一个 ALTER TABLE
tbl_nameDROP PRIMARY KEY, ADD PRIMARY KEY (column), ALGORITHM=INPLACE, LOCK=NONE;数据重组的基本上,使它成为一个昂贵的操作。
VARCHAR | |||||
NULL | |||||
NOT NULL | |||||
ENUM |
语法和用法说明
添加列 ALTER TABLE
tbl_nameADD COLUMNcolumn_namecolumn_definition, ALGORITHM=INSTANT;当将不允许并行DML 自增量 专栏数据重组的基本上,使它成为一个昂贵的操作。在最低限度, ALGORITHM=INPLACE, LOCK=SHARED是必需的 以下限制适用于当 INSTANT算法是用来添加列: 添加一个列不能组合在同一语句与其他 ALTER TABLE行动不支持 ALGORITHM=INSTANT一列只能添加作为表格的最后一列。添加列的任何其他位置的其他列不支持。 不能将列添加到表的使用 ROW_FORMAT=COMPRESSED不能将列添加到表中,包括 FULLTEXT指数 不能将列添加到临时表。临时表仅支持 ALGORITHM=COPY不能将列添加到驻留在数据字典表空间表。 行大小限制是不添加列时评价。然而,行大小限制进行DML操作,插入和更新表中的行。
多个列可以在相同的加 ALTER TABLE声明。例如: ALTER TABLE t1 ADD COLUMN c2 INT, ADD COLUMN c3 INT, ALGORITHM=INSTANT;
INFORMATION_SCHEMA.INNODB_TABLES和 INFORMATION_SCHEMA.INNODB_COLUMNS即时添加列提供元数据。 information_schema.innodb_tables.instant_cols 显示表中的列数增加的第一瞬间列前。 INFORMATION_SCHEMA.INNODB_COLUMNS.HAS_DEFAULT和 default_value 提供即时添加列元数据的默认值。 删除列 ALTER TABLE
tbl_nameDROP COLUMNcolumn_name, ALGORITHM=INPLACE, LOCK=NONE;数据重组的基本上,使它成为一个昂贵的操作。 重命名一个列 ALTER TABLE
tblCHANGEold_col_namenew_col_namedata_type, ALGORITHM=INPLACE, LOCK=NONE;允许并行DML,保持相同的数据类型,只改变列的名称。 当你把相同的数据类型和 [NOT] NULL属性,只改变列的名字,都可以进行网上操作。 你也可以重命名为外键约束部分列。外键定义自动更新为使用新的列名称。重命名一个列参与外键只能与 ALGORITHM=INPLACE。如果你使用 ALGORITHM=COPY条款,或其他一些条件,使命令的使用 ALGORITHM=COPY幕后的 修改表 语句失败 ALGORITHM=INPLACE不能重命名的支持 生成的列 重排列 对列重新排序,使用 FIRST或 后 进入 CHANGE或 修改 运营 ALTER TABLE
tbl_nameMODIFY COLUMNcol_namecolumn_definitionFIRST, ALGORITHM=INPLACE, LOCK=NONE;数据重组的基本上,使它成为一个昂贵的操作。 更改列的数据类型 ALTER TABLE
tbl_nameCHANGE c1 c1 BIGINT, ALGORITHM=COPY;更改列的数据类型只支持 ALGORITHM=COPY延伸 VARCHAR柱尺寸 修改表 tbl_nameCHANGE COLUMN c1 c1 VARCHAR(255), ALGORITHM=INPLACE, LOCK=NONE;所需要的长度字节数 VARCHAR列必须是相同的。为 VARCHAR0到255字节大小的列,一个长度字节编码所需的价值。为 VARCHAR在尺寸或超过256字节的列,两个长度字节是必需的。因此,在的地方 ALTER TABLE只支持增加 VARCHAR柱的大小从0到255字节,256字节或更大尺寸的。在的地方 ALTER TABLE不支持增加一个尺寸 VARCHAR柱从小于256字节的大小等于或大于256字节。在这种情况下,从1到2的所需长度字节数的改变,这是由一个表复制仅支持( ALGORITHM=COPY)。例如,试图改变 VARCHAR对于单字节字符集从VARCHAR列大小(255)到(256)使用varchar到位 ALTER TABLE返回此错误: 修改表 tbl_nameALGORITHM=INPLACE, CHANGE COLUMN c1 c1 VARCHAR(256);ERROR 0A000: ALGORITHM=INPLACE is not supported. Reason: Cannot changecolumn type INPLACE. Try ALGORITHM=COPY.笔记 一个字节的长度 VARCHAR柱是基于字符的字节长度设置依赖。 降低 VARCHAR大小用到位 ALTER TABLE不支持。降低 VARCHAR尺寸要求表复制( ALGORITHM=COPY) 设置列的默认值 ALTER TABLE
tbl_nameALTER COLUMNcolSET DEFAULTliteral, ALGORITHM=INSTANT;只修改表元数据。列默认值存储在 数据词典 删除列的默认值 ALTER TABLE
tblALTER COLUMNcolDROP DEFAULT, ALGORITHM=INSTANT;改变自动增量值 ALTER TABLE
tableAUTO_INCREMENT=next_value, ALGORITHM=INPLACE, LOCK=NONE;修改一个值存储在内存中,而不是数据文件。 在分布式系统中使用复制或分片,有时你会重置为一个表一个特定的值自动递增计数器。下一行插入表中使用的自动递增列指定值。你也可以使用在您定期清空所有表的数据仓库环境技术和加载它们,并重新启动自动递增序列从1。 制作一个柱 NULL修改表tbl_name修改列 column_namedata_typeNULL, ALGORITHM=INPLACE, LOCK=NONE;重建表的地方。数据重组的基本上,使它成为一个昂贵的操作。 制作一个柱 NOT NULL修改表 tbl_name修改列 column_namedata_typeNOT NULL, ALGORITHM=INPLACE, LOCK=NONE;《rebuilds表在的地方。 STRICT_ALL_TABLES或 strict_trans_tables SQL_MODE是成功的操作要求。如果该列包含空值的操作失败。服务器禁止更改外键列,就必须使参照完整性的潜在损失。看到 第13.1.8,“ALTER TABLE语法” 。数据重组的基本上,使它成为一个昂贵的操作。 修改一个定义 ENUM或 配置 专栏 CREATE TABLE t1 (c1 ENUM('a', 'b', 'c')); ALTER TABLE t1 MODIFY COLUMN c1 ENUM('a', 'b', 'c', 'd'), ALGORITHM=INSTANT;修改一个定义 ENUM或 SET通过添加新的枚举或组成员列 结束 对有效的成员值的列表可能立即发生或进行的,只要该数据类型的存储大小没有变化。例如,添加一个成员了 SET列有8名成员的变化所需的存储每值从1字节到2字节;这需要一个表复制。在列表中添加成员造成重编现有成员,这就需要一个表复制。
STORED | |||||
STORED | |||||
STORED | |||||
VIRTUAL | |||||
VIRTUAL | |||||
VIRTUAL |
语法和用法说明
添加一个 STORED专栏 ALTER TABLE t1 ADD COLUMN (c2 INT GENERATED ALWAYS AS (c1 + 1) STORED), ALGORITHM=COPY;
ADD COLUMN是不是到位操作存储列(没有使用临时表)因为表达必须由服务器计算。 修改 STORED列顺序 ALTER TABLE t1 MODIFY COLUMN c2 INT GENERATED ALWAYS AS (c1 + 1) STORED FIRST, ALGORITHM=COPY;
《rebuilds表在的地方。 落下 STORED专栏 ALTER TABLE t1 DROP COLUMN c2, ALGORITHM=INPLACE, LOCK=NONE;
《rebuilds表在的地方。 添加一个 VIRTUAL专栏 ALTER TABLE t1 ADD COLUMN (c2 INT GENERATED ALWAYS AS (c1 + 1) VIRTUAL), ALGORITHM=INSTANT;
添加一个虚拟柱可以进行即时或在非分区表。 添加一个 VIRTUAL是不是到位操作分区表。 修改 VIRTUAL列顺序 ALTER TABLE t1 MODIFY COLUMN c2 INT GENERATED ALWAYS AS (c1 + 1) VIRTUAL FIRST, ALGORITHM=COPY;
落下 VIRTUAL专栏 ALTER TABLE t1 DROP COLUMN c2, ALGORITHM=INSTANT;
落下 VIRTUAL柱可以进行即时或在非分区表。
语法和用法说明
添加外键约束 这个 INPLACE算法支持 foreign_key_checks被禁用。否则,只有 复制 算法支持 ALTER TABLE
tbl1ADD CONSTRAINTfk_nameFOREIGN KEYindex(col1) REFERENCEStbl2(col2)referential_actions;删除外键约束 ALTER TABLE
tblDROP FOREIGN KEYfk_name;删除外键可以进行在线的 foreign_key_checks选择启用或禁用 如果你不知道在一个特定的表的外键约束的名字,发出以下声明中找到约束名称 CONSTRAINT每个外键子句: 显示创建表 tableG 或者,查询 INFORMATION_SCHEMA.TABLE_CONSTRAINTS表和使用 约束_ name 和 CONSTRAINT_TYPE列外键名称识别 你也可以减少一个外键及其相关指标在一个语句中: ALTER TABLE
tableDROP FOREIGN KEYconstraint, DROP INDEXindex;
FOREIGN KEY ... REFERENCE
一个 ALTER TABLE在子表可以等待另一个事务提交,如果更改父表原因子表中相关的变化通过 在更新 或 ON DELETE从句的使用 级联 或 SET NULL参数. 以同样的方式,如果表是 父表 在外键关系,即使它不包含任何 FOREIGN KEY条款,它可以等待 ALTER TABLE完成如果 INSERT, UPDATE,或 DELETE表原因 在更新 或 ON DELETE子表中的作用
ROW_FORMAT | |||||
KEY_BLOCK_SIZE | |||||
FORCE | |||||
语法和用法说明
改变 ROW_FORMAT修改表 tbl_nameROW_FORMAT =row_format, ALGORITHM=INPLACE, LOCK=NONE;数据重组的基本上,使它成为一个昂贵的操作。 有关更多信息 ROW_FORMAT选项,看 表选项 改变 KEY_BLOCK_SIZE修改表 tbl_nameKEY_BLOCK_SIZE =value, ALGORITHM=INPLACE, LOCK=NONE;数据重组的基本上,使它成为一个昂贵的操作。 有关更多信息 KEY_BLOCK_SIZE选项,看 表选项 持续的统计表选项设置 ALTER TABLE
tbl_nameSTATS_PERSISTENT=0, STATS_SAMPLE_PAGES=20, STATS_AUTO_RECALC=1, ALGORITHM=INPLACE, LOCK=NONE;only修饰元数据表。 持续的统计数据包括 STATS_PERSISTENT, stats_auto_recalc ,和 STATS_SAMPLE_PAGES。有关更多信息,参见 第15.6.11.1”配置,持续优化统计参数 指定字符集 ALTER TABLE
tbl_nameCHARACTER SET =charset_name, ALGORITHM=INPLACE, LOCK=NONE;重建表如果新的字符编码是不同的。 转换字符集 ALTER TABLE
tbl_nameCONVERT TO CHARACTER SETcharset_name, ALGORITHM=COPY;重建表如果新的字符编码是不同的。 优化表 OPTIMIZE TABLE
tbl_name;在地方操作不表支持 FULLTEXT反应。手术刀 到位 算法,但 ALGORITHM和 锁具 语法是不允许的 启用或禁用表加密 ALTER TABLE
tbl_nameENCRYPTION='Y', ALGORITHM=COPY;在地方操作不表支持 FULLTEXT指标。手术采用适当的算法,但 算法 和 LOCK语法是不允许的 在重建一个表 FORCE选项 修改表 tbl_nameFORCE, ALGORITHM=INPLACE, LOCK=NONE;使用 ALGORITHM=INPLACE在MySQL 5.6.17 ALGORITHM=INPLACE是不是为表支持 全文 指标 “空”福音表演 ALTER TABLE
tbl_nameENGINE=InnoDB, ALGORITHM=INPLACE, LOCK=NONE;使用 ALGORITHM=INPLACE在MySQL 5.6.17。 ALGORITHM=INPLACE是不是为表支持 FULLTEXT指标 重命名一个表 ALTER TABLE
old_tbl_nameRENAME TOnew_tbl_name, ALGORITHM=INSTANT;重命名一个表可以在瞬间或表现。MySQL将对应于表文件 tbl_name没有复制。(你也可以使用 RENAME TABLE语句重命名表。看到 第13.1.33,“重命名表语法” 权限。)专门为table没有迁移到新的名字。他们必须手动更改。
ALTER
TABLEInnoDB
ALTER TABLEALTER
TABLE
ALTER TABLE
ALTER TABLEALGORITHM=COPYALGORITHM=DEFAULT,
LOCK=DEFAULTALTER TABLE
PARTITION BY | ALGORITHM=COPYLOCK={DEFAULT|SHARED|EXCLUSIVE} | |||
ADD PARTITION | ALGORITHM=INPLACE,
LOCK={DEFAULT|NONE|SHARED|EXCLUSISVE}LISTALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSISVE}HASHALGORITHM=COPY,
LOCK={SHARED|EXCLUSIVE}LISTALGORITHM=COPYHASH | |||
DROP PARTITION |
| |||
DISCARD PARTITION | ALGORITHM=DEFAULTLOCK=DEFAULT | |||
IMPORT PARTITION | ALGORITHM=DEFAULTLOCK=DEFAULT | |||
TRUNCATE
PARTITION | ||||
COALESCE
PARTITION | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE} | |||
REORGANIZE
PARTITION | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE} | |||
EXCHANGE
PARTITION | ||||
ANALYZE PARTITION | ||||
CHECK PARTITION | ||||
OPTIMIZE
PARTITION | ALGORITHM | |||
REBUILD PARTITION | ALGORITHM=INPLACE, LOCK={DEFAULT|SHARED|EXCLUSIVE} | |||
REPAIR PARTITION | ||||
REMOVE
PARTITIONING | ALGORITHM=COPYLOCK={DEFAULT|SHARED|EXCLUSIVE} |
ALTER
TABLEALTER TABLE
ALTER
TABLE
访问表的应用更加敏感,因为在表查询和DML操作可以继续进行,而DDL操作正在进行中。减少锁等待MySQL服务器资源带来更大的可扩展性,即使是不涉及DDL操作。 即时操作只修改元数据在数据字典。没有元数据锁在表和表数据不受影响,使操作瞬时。并行DML不受影响。 在线操作,避免磁盘I/O和CPU周期与表相关的复制方法,最大限度地减少对数据库的整体负荷。最小负荷有助于维持在DDL操作的高性能和高吞吐量。 在线操作读取数据到缓冲池不比表复制操作,从而降低了频繁访问的数据从内存中清除。频繁访问的数据清除的DDL操作后造成暂时的性能下降。
LOCKLOCK
LOCK=NONE: 允许的并发查询和DML。 例如,使用此条款涉及客户注册或购买表,避免冗长的DDL操作时不可用的表。 LOCK=SHARED: 允许同时查询,但块DML。 例如,使用此条款对数据仓库表,在那里你可以延迟数据加载操作直到DDL操作完成,但查询不能长时间延迟。 LOCK=DEFAULT: 允许尽可能多的并发(并发查询,DML,或两者都有)。省略 LOCK条款是作为指定相同的 LOCK=DEFAULT使用这个条款,当你知道默认的锁定级别的DDL语句不会导致可用性问题的表。 LOCK=EXCLUSIVE: 块并行查询和DML 如果主要关心的是在最短的时间内完成DDL操作使用这一条款,和并行查询和DML访问是没有必要的。你也可能如果服务器是闲置的使用这一条款,以避免意外的表的访问。
1阶段:初始化 在初始化阶段,服务器确定多少并发术中允许的,考虑到存储引擎的功能,在声明中指定的操作,和用户指定的 ALGORITHM和 锁具 选项在这个阶段,一个共享锁升级元数据以保护电流表的定义。 2阶段:执行 在这一阶段,准备和执行语句。无论是元数据锁升级为独家取决于因素在初始化阶段评估。如果一个专属元数据锁是必需的,它只是被简单地在表的编制。 3阶段:提交表定义 在提交表格定义阶段,元数据锁升级为独家驱逐旧表定义并提交新的一。一旦获准,独家的元数据锁的持续时间是短暂的。
mysql> CREATE TABLE t1 (c1 INT) ENGINE=InnoDB; mysql> START TRANSACTION; mysql> SELECT * FROM t1;
SELECT
mysql> ALTER TABLE t1 ADD COLUMN x INT, ALGORITHM=INPLACE, LOCK=NONE;
mysql> SELECT * FROM t1;
SELECTALTER TABLE
SHOW FULL
PROCESSLIST
MySQL的> SHOW FULL PROCESSLIST\G...*************************** 2. row *************************** Id: 5 User: root Host: localhost db: testCommand: Query Time: 44 State: Waiting for table metadata lock Info: ALTER TABLE t1 ADD COLUMN x INT, ALGORITHM=INPLACE, LOCK=NONE...*************************** 4. row *************************** Id: 7 User: root Host: localhost db: testCommand: Query Time: 5 State: Waiting for table metadata lock Info: SELECT * FROM t14 rows in set (0.00 sec)
metadata_locks
ALGORITHM=INSTANTALGORITHM=INPLACEALGORITHM=COPYold_alter_tableALGORITHM=COPY
更改列的默认值(快速、不影响表中的数据): Query OK, 0 rows affected (0.07 sec)
添加索引(需要时间,但 0 rows affected显示表不复制): 查询行,0行受影响(21.42秒) 更改列的数据类型(需要大量的时间,需要重建表中的所有行): Query OK, 1671168 rows affected (1 min 35.54 sec)
系表结构 用少量的数据填充克隆表。 在克隆表运行DDL操作。 检查是否 “ 受影响的行 “ 值为零或不。一个非零值意味着操作复制表中的数据,这可能需要特殊的规划。例如,你可能会一段时间预计在做DDL操作,或在每个复制从服务器在同一时间。
INFORMATION_SCHEMA
ALTER TABLE
临时日志文件空间 一个临时日志文件记录并发DML当在线DDL操作创建一个索引或改变表。临时日志文件扩展的价值要求 innodb_sort_buffer_size到一个指定的最大的 innodb_online_alter_log_max_size。如果一个临时日志文件超过大小限制,在线DDL操作失败,并提交并行DML操作的回滚。一个大的 innodb_online_alter_log_max_size设置允许在线DDL DML操作过程中,但它也延伸一段时间在DDL操作结束时,表锁定申请登录DML。 如果操作需要很长的时间和并行DML修改表这么多的临时日志文件的大小超过此值 innodb_online_alter_log_max_size,在线DDL操作失败与 db_online_log_too_big 误差 临时文件排序空间 在线DDL操作重建表写入临时文件排序的MySQL临时目录( $TMPDIR在UNIX, %temp% 在Windows中,或者指定的目录 --tmpdir)在创建索引。临时排序文件不包含原始表的目录中创建。每个临时排序文件足以容纳所有次级索引列的聚集索引和主键列。临时排序文件被删除等内容合并到最终的表或索引。临时排序文件可能需要空间等于表中加上索引的数据量。一个在线DDL操作,重建表报告错误如果它使用所有可用的磁盘空间在数据目录所在的文件系统。 如果MySQL临时目录不足以容纳排序文件,设置 tmpdir到不同的目录。另外,定义一个单独的临时目录使用在线DDL操作 innodb_tmpdir。这个选项是为了帮助避免临时目录溢出可能发生大的临时文件排序。 为一个中间表文件空间 一些在线DDL操作重建表创建相同目录中的临时文件作为原始表中间表。中间表文件可能需要空间等于原表的大小。中间表文件名的开始 #sql-ib前缀只出现在在线DDL操作简单。 这个 innodb_tmpdir选项不适用于中间表文件。
ALTER TABLEALTER TABLEALTER
TABLE
ALTER TABLE
修改表T1添加索引I1(C1),添加唯一索引I2(C2),改变c4_old_name c4_new_name整数的符号;
ALTER TABLE t1 ADD INDEX i1(c1); ALTER TABLE t1 ADD UNIQUE INDEX i2(c2); ALTER TABLE t1 CHANGE c4_old_name c4_new_name INTEGER UNSIGNED NOT NULL;
ALTER
TABLE
操作必须在一个特定的顺序进行,如创建一个索引,其次是外键约束,利用指数。 操作使用相同的特异性 LOCK条款,你想成功或失败作为一组。 无法进行网上操作,即,仍然使用表复制方法。 操作中指定 ALGORITHM=COPY或 old_alter_table=1,力表复制行为如果在专业场景需要精确的向后兼容性。
一个 ALGORITHM子句指定一个算法,不兼容的特定类型的DDL操作或存储引擎。 一 LOCK子句指定了一个低程度的锁定( 共享 或 NONE),是不是跟DDL操作特定类型兼容。 在等待一个发生超时 独占锁 在桌子上,这可能的初始和最终的DDL操作阶段中需要简单。 这个 tmpdir或 innodb_tmpdir文件系统的磁盘空间耗尽,而MySQL写入临时文件排序在磁盘中创建索引。有关更多信息,参见 第15.12.3,“在线DDL空间要求” 该操作需要很长的时间和并发DML修改表这么多,临时在线日志的大小超过了价值 innodb_online_alter_log_max_size配置选项。这一条件的原因 db_online_log_too_big 误差 并行DML修改,允许与原表的表定义,但不符合新的。操作失败,在最后,当MySQL试图运用并行DML语句的所有变化。例如,您可以插入重复的值为柱而唯一索引被创建,或者您可以插入 NULL值为柱而创造一种 主键 在列的索引。通过并行DML更改的优先,和 ALTER TABLE手术是有效的 回滚
表复制时创建一个索引上 TEMPORARY TABLE这个 ALTER TABLE条款 LOCK=NONE是不是如果有允许 ON...CASCADE或 在...set零 constraints on the table。 在一个地方在线DDL操作就能完成的,它必须等待交易持有的元数据锁表提交或回滚。一个在线DDL操作可能会短暂的在执行阶段需要在表专用元数据锁,总是需要一个在最后阶段的操作更新表定义时。因此,交易保持元数据锁表会导致在线DDL操作块。把元数据锁桌上的交易可能已经开始前或在线DDL操作期间。长时间运行或不活跃的交易将桌上的元数据锁会导致在线DDL操作超时。 当运行在在线DDL操作,线程的运行 ALTER TABLE声明应用,同时运行在同一台从其他连接螺纹DML操作的在线日志。当DML操作的应用,可能会遇到重复的键输入错误( 错误1062(23000):重复的条目 ),即使重复的条目仅仅是暂时的,会被在网上登录后进入。这是类似于一个外键约束检查的想法 InnoDB在交易过程中的约束,必须持有。 OPTIMIZE TABLE对于一个 InnoDB 表映射到 ALTER TABLE手术重建表和聚集索引更新索引统计和未使用的空间。次要指标不产生有效因为钥匙还插在他们出现在主键。 OPTIMIZE TABLE支持与重建正则在线DDL支持添加和分区 InnoDB 表 创建表之前,MySQL 5.6,包括时间列( DATE, DATETIME或 TIMESTAMP)并没有被重建使用 ALGORITHM=COPY不支持 ALGORITHM=INPLACE。在这种情况下,一个 ALTER TABLE ... ALGORITHM=INPLACE操作返回以下错误: ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported.Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
以下的限制,一般适用于在线DDL操作大表涉及重建表: 没有暂停在线DDL操作或节流的I / O或CPU使用一个在线DDL操作机制。 一个在线DDL操作回滚可以是昂贵的手术应不。 长时间运行的在线DDL操作会导致复制滞后。一个在线DDL操作必须完成在主运行在运行前的奴隶。另外,DML是在掌握并行处理是处理奴隶在奴隶的DDL操作完成。
对大型表运行在线DDL操作相关的更多信息,参见 第15.12.2,“在线DDL性能和并发性”
这是真的还是假的系统变量可以启用在服务器启动命名,或残疾人使用 --skip-前缀.例如,启用或禁用 InnoDB 自适应哈希索引,您可以使用 --innodb_adaptive_hash_index或 --skip-innodb_adaptive_hash_index在命令行上,或 innodb_adaptive_hash_index或 skip-innodb_adaptive_hash_index 在一个文件的选择 系统变量取值可以指定为 --var_name=value在命令行或 var_name=value在选项文件 许多系统变量可以在运行时改变(见 第5.1.8.3,动态的“系统变量” ) 有关 GLOBAL和 会话 modifiers可变范围,参考。 SET13 . Statement documentation . 某些选项控制位置和布局的 InnoDB数据文件 第15.6.1,“InnoDB启动配置” 解释如何使用这些选项。 一些选项,你可能不会使用最初,帮助调整 InnoDB基于机器的能力和你的数据库的性能特点 工作量 有关指定选项和系统变量的更多信息,参见 4.2.3节”指定程序选项”
InnoDB的命令选项
财产 价值 命令行格式 --ignore-builtin-innodb过时的 是的(除去8.0.3) 系统变量 ignore_builtin_innodb范围 全球 动态 否 set_var 提示应用 否 类型 布尔 在MySQL 5.1中,这个选项会造成服务器的行为如果内置 InnoDB不存在,使 InnoDB Plugin 可用于代替。在MySQL 5.0, InnoDB是默认的存储引擎 InnoDB插件 不使用。此选项是为删除MySQL。 财产 价值 命令行格式 --innodb[=value]过时的 是 类型 枚举 默认值 ON有效值 OFFONFORCE控制加载的 InnoDB存储引擎,如果服务器编译 InnoDB 支持这个选项有一个三态格式,可能的值 OFF, 打开(放) ,或 FORCE。看到 第5.6.1,“安装和卸载插件” 禁用 InnoDB,使用 --innodb=OFF或 --skip-innodb。在这种情况下,因为默认的存储引擎 InnoDB服务器无法启动,除非你同时使用 --default-storage-engine和 --default-tmp-storage-engine设置默认的一些其他引擎的永久和 临时 表 这个 InnoDB存储引擎可以不再被禁用,和 --innodb=OFF和 --skip-innodb选项是过时的、没有效果。在警告他们的使用效果。这些选项将在未来的MySQL版本中删除。 财产 价值 命令行格式 --innodb-status-file类型 布尔 默认值 OFF控制是否 InnoDB创建一个文件名为 _ InnoDB的地位。 pid在MySQL数据目录。如果启用, InnoDB 定期写输出 SHOW ENGINE INNODB STATUS这个文件 默认情况下,则不创建文件。去创造它,开始 mysqld 与 --innodb-status-file=1选项该文件是在正常关机删除。 禁用 InnoDB存储引擎。看到的描述 --innodb
InnoDB系统变量
daemon_memcached_enable_binlog财产 价值 命令行格式 --daemon-memcached-enable-binlog=#系统变量 daemon_memcached_enable_binlog范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 false启用这个选项 主服务器 使用 InnoDBmemcached (插件 daemon_memcached)与MySQL 二进制日志 。此选项只能设置在服务器启动。你还必须使MySQL二进制日志在主服务器上使用 --log-bin选项 有关更多信息,参见 第15.19.7,“InnoDB Memcached插件和复制” daemon_memcached_engine_lib_name财产 价值 命令行格式 --daemon-memcached-engine-lib-name=library系统变量 daemon_memcached_engine_lib_name范围 全球 动态 否 set_var 提示应用 否 类型 文件名 默认值 innodb_engine.so指定的共享库的实现 InnoDBmemcached 插件 有关更多信息,参见 第15.19.3,设置innodb memcached插件” daemon_memcached_engine_lib_path财产 价值 命令行格式 --daemon-memcached-engine-lib-path=directory系统变量 daemon_memcached_engine_lib_path范围 全球 动态 否 set_var 提示应用 否 类型 目录名称 默认值 NULL路径的目录包含共享库的实现 InnoDBmemcached 插件默认值为空,表示MySQL插件目录。你不需要修改这个参数,除非指定 memcached对于不同的存储引擎,位于MySQL插件目录以外的插件。 有关更多信息,参见 第15.19.3,设置innodb memcached插件” 财产 价值 命令行格式 --daemon-memcached-option=options系统变量 daemon_memcached_option范围 全球 动态 否 set_var 提示应用 否 类型 字符串 默认值 用于传递空间分离的缓存选项标 memcached 内存对象缓存守护进程启动。例如,你可能会改变端口 memcached 听,减少同时连接的最大数目,换一个键/值对的最大内存大小,或启用调试的错误日志消息。 看到 第15.19.3,设置innodb memcached插件” 使用细节。有关 memcached 选项,请参阅 memcached 个人网页 财产 价值 命令行格式 --daemon-memcached-r-batch-size=#系统变量 daemon_memcached_r_batch_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 1指定多少 memcached 读操作( get操作)执行之前做的 COMMIT开始一个新的交易。副本 daemon_memcached_w_batch_size这个值是默认设置,使表格通过SQL语句的任何改变都是立即可见的 memcached 运营你可能会增加减少频繁的开销有一个系统,基础表才被通过 memcached 接口如果设置的值太大,大量撤消或重做数据可以施加一定的存储开销,对于任何长期的交易。 有关更多信息,参见 第15.19.3,设置innodb memcached插件” 财产 价值 命令行格式 --daemon-memcached-w-batch-size=#系统变量 daemon_memcached_w_batch_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 1指定多少 memcached 写操作,如 add, 配置 ,和 incr执行前,做一个 COMMIT开始一个新的交易。副本 daemon_memcached_r_batch_size这个值是默认设置为1,在假设数据存储是在断电时保存重要的应立即提交。当存储非关键数据,你可能会增加这个值减少频繁的开销犯;但最后一 N1未提交的写操作可以在发生崩溃时丢失。 有关更多信息,参见 第15.19.3,设置innodb memcached插件” 财产 价值 命令行格式 --ignore-builtin-innodb过时的 是的(除去8.0.3) 系统变量 ignore_builtin_innodb范围 全球 动态 否 set_var 提示应用 否 类型 布尔 看到的描述 --ignore-builtin-innodb在下面 “ InnoDB的命令选项 “ 在本节前面。这个变量是在MySQL 8中移除。 财产 价值 命令行格式 --innodb-adaptive-flushing=#系统变量 innodb_adaptive_flushing范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON指定是否动态调整冲洗速度 脏页 在 InnoDB缓冲池 基于工作量。刷新率动态调整的目的是为了避免爆发的I/O活动。默认启用。看到 第15.6.3.6,“配置InnoDB缓冲池冲洗” 更多信息。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-adaptive-flushing-lwm=#系统变量 innodb_adaptive_flushing_lwm范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 10最小值 0最大值 70定义了低水位代表比例 重做日志文件 的能力, 自适应刷新 启用。有关更多信息,参见 第15.6.3.7,“微调InnoDB缓冲池冲洗” 财产 价值 命令行格式 --innodb-adaptive-hash-index=#系统变量 innodb_adaptive_hash_index范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON是否 InnoDB自适应哈希索引 启用或禁用。它可能是可取的,这取决于你的工作量,动态地启用或禁用 自适应哈希索引 为了提高查询性能。由于自适应哈希索引不可能为所有的工作负载是有用的,它都启用和禁用进行基准测试,使用真实的工作负载。看到 第15.4.3,“自适应哈希索引” 详情 默认启用。你可以修改这个参数的使用 SET GLOBAL声明中,无需重新启动服务器。改变设置要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权。你也可以使用 --skip-innodb_adaptive_hash_index在服务器启动时禁用它。 禁用自适应哈希索引的哈希表立即清空。正常操作可以在哈希表是空的继续,和执行查询,使用哈希表而不是直接访问索引B树。当自适应哈希索引被重新启用,哈希表是稠密的再次正常运行时。 innodb_adaptive_hash_index_parts财产 价值 命令行格式 --innodb-adaptive-hash-index-parts=#系统变量 innodb_adaptive_hash_index_parts范围 全球 动态 否 set_var 提示应用 否 类型 数字 默认值 8最小值 1最大值 512将自适应哈希索引检索系统。每个指标是绑定到特定的分区,每个分区由一个单独的闩锁保护。 自适应哈希索引搜索系统默认分为8个部分。最大值设置为512。 相关的信息,看 第15.4.3,“自适应哈希索引” innodb_adaptive_max_sleep_delay财产 价值 命令行格式 --innodb-adaptive-max-sleep-delay=#系统变量 innodb_adaptive_max_sleep_delay范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 150000最小值 0最大值 1000000许可证 InnoDB自动调整值 innodb_thread_sleep_delay向上或向下,根据目前的工作量。任何非零的值可以自动的动态调整 innodb_thread_sleep_delay 值,达到指定的最大值 innodb_adaptive_max_sleep_delay选项此值表示的微秒数。这个选项可以在繁忙的系统是有用的,大于16 InnoDB 螺纹。(在实践中,有成百上千的同时连接MySQL数据库系统,它是最有价值的) 有关更多信息,参见 第15.6.5,“配置InnoDB线程并发 财产 价值 命令行格式 --innodb-api-bk-commit-interval=#系统变量 innodb_api_bk_commit_interval范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 5最小值 1最大值 1073741824多久自动提交空闲连接使用 InnoDBmemcached 接口,在秒。有关更多信息,参见 第15.19.6.4,“控制InnoDB Memcached插件”的交易行为 财产 价值 命令行格式 --innodb-api-disable-rowlock=#系统变量 innodb_api_disable_rowlock范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF使用此选项来禁用行锁时 InnoDBmemcached 执行DML操作。默认情况下, innodb_api_disable_rowlock是残疾人,这意味着 memcached 请求行锁 get和 配置 运营什么时候 innodb_api_disable_rowlock启用, memcached 请求而不是行锁表锁 innodb_api_disable_rowlock不动。它必须被指定在 mysqld 在MySQL的配置文件或命令行输入。配置生效的插件安装,发生时,MySQL服务器启动。 财产 价值 命令行格式 --innodb-api-enable-binlog=#系统变量 innodb_api_enable_binlog范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF让您使用 InnoDBmemcached 与MySQL的插件 二进制日志 。有关更多信息,参见 使InnoDB Memcached二进制日志 财产 价值 命令行格式 --innodb-api-enable-mdl=#系统变量 innodb_api_enable_mdl范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF锁表使用的 InnoDBmemcached 插件,因此无法删除或改变 DDL 通过SQL接口。有关更多信息,参见 第15.19.6.4,“控制InnoDB Memcached插件”的交易行为 财产 价值 命令行格式 --innodb-api-trx-level=#系统变量 innodb_api_trx_level范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0控制事务 隔离级别 我们是在一起的 memcached 接口。相应的常量的名称是:家庭 财产 价值 命令行格式 --innodb-autoextend-increment=#系统变量 innodb_autoextend_increment范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 64最小值 1最大值 1000增量的大小(以兆字节)的大小自动扩展延伸 InnoDB系统片 文件当它变得完整。默认值是64。相关的信息,看 系统表空间的数据文件的配置 ,和 第15.7.1,“调整InnoDB系统表空间” 这个 innodb_autoextend_increment设置不影响 文件表 表空间文件或 烟草公司 文件这些文件是自动延伸的 innodb_autoextend_increment设置最初的扩展是由少量,之后扩展发生在增量4MB。 财产 价值 命令行格式 --innodb-autoinc-lock-mode=#系统变量 innodb_autoinc_lock_mode范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 (>= 8.0.3)2默认值 (<= 8.0.2)1有效值 012这个 锁模式 用于生成 自增量 价值观。允许的值为0, 1,或2,为传统的,连续的,或交错,分别。 默认设置为2(交错)在MySQL 8和1(连续)之前。变化交错锁模式为默认设置反映了从表为基础的基于行的复制作为默认的复制型的转变,在MySQL 5.7发生。基于语句的复制需要连续自动增量的锁模式确保自动增量值在可预测和可重复的顺序分配给SQL语句序列,而基于行的复制不到SQL语句的执行顺序的敏感。 对于每个锁模式的特点,看 InnoDB auto_increment锁模式 innodb_background_drop_list_empty财产 价值 命令行格式 --innodb-background-drop-list-empty=#系统变量 innodb_background_drop_list_empty范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF使 innodb_background_drop_list_empty调试选项有助于延缓表创建到背景下拉列表是空的避免测试用例失败。例如,如果测试用例的一个地方台 T1 背景上的下拉列表,测试用例B等在创建表的背景下拉列表是空的 t1财产 价值 命令行格式 --innodb-buffer-pool-chunk-size系统变量 innodb_buffer_pool_chunk_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 134217728最小值 1048576最大值 innodb_buffer_pool_size / innodb_buffer_pool_instancesinnodb_buffer_pool_chunk_size定义块的大小 InnoDB 缓冲池大小调整操作。这个 innodb_buffer_pool_size参数是动态的,它允许您调整缓冲池,无需重新启动服务器。 为了避免复制所有缓冲池页面在调整操作,操作完成 “ 块 “ 。默认情况下, innodb_buffer_pool_chunk_size为128MB(134217728字节)。包含在一个块的页面数量取决于价值 innodb_page_sizeinnodb_buffer_pool_chunk_size 可以增加或减少单位1MB(1048576字节)。 下列条件时改变 innodb_buffer_pool_chunk_size价值: 如果 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances比目前更大的缓冲池大小的缓冲池初始化时, innodb_buffer_pool_chunk_size截断 innodb_buffer_pool_size/ innodb_buffer_pool_instances缓冲池的大小必须等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances。如果你改变 innodb_buffer_pool_chunk_size, innodb_buffer_pool_size自动圆一个值等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances。调整发生时,缓冲池初始化。
重要 护理时应更换 innodb_buffer_pool_chunk_size,为改变这个值可以自动增加缓冲池的大小。在改变 innodb_buffer_pool_chunk_size,计算它会对影响 innodb_buffer_pool_size为确保缓冲池的大小是可以接受的。 为了避免潜在的性能问题,块的数量( innodb_buffer_pool_size/ innodb_buffer_pool_chunk_size)应不超过1000 财产 价值 命令行格式 --innodb-buffer-pool-debug=#系统变量 innodb_buffer_pool_debug范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF启用此选项允许多个缓冲池的情况下,缓冲池小于1GB,忽略1GB的最小缓冲池大小限制 innodb_buffer_pool_instances。这个 innodb_buffer_pool_debug 选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 innodb_buffer_pool_dump_at_shutdown财产 价值 命令行格式 --innodb-buffer-pool-dump-at-shutdown=#系统变量 innodb_buffer_pool_dump_at_shutdown范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON指定是否记录页面缓存在 InnoDB缓冲池 当MySQL服务器关闭,缩短 热身 在下一个过程的启动。通常结合使用 innodb_buffer_pool_load_at_startup。这个 innodb_buffer_pool_dump_pct选项定义最近使用的缓冲池页面转储的百分比。 两 innodb_buffer_pool_dump_at_shutdown和 innodb_buffer_pool_load_at_startup 默认情况下启用 有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” 财产 价值 命令行格式 --innodb-buffer-pool-dump-now=#系统变量 innodb_buffer_pool_dump_now范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF立即记录页面缓存在 InnoDB缓冲池 。通常结合使用 innodb_buffer_pool_load_now有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” 财产 价值 命令行格式 --innodb-buffer-pool-dump-pct=#系统变量 innodb_buffer_pool_dump_pct范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 25最小值 1最大值 100指定最近使用的每个缓冲池的读出并转储页的百分比。范围是1到100。默认值是25。例如,如果有4个缓冲池的100页,和 innodb_buffer_pool_dump_pct设置为25,25最近使用的每个缓冲池页面被甩了。 财产 价值 命令行格式 --innodb-buffer-pool-filename=file系统变量 innodb_buffer_pool_filename范围 全球 动态 是 set_var 提示应用 否 类型 文件名 默认值 ib_buffer_pool指定保存表空间ID和网页ID的列表中的文件的名称 innodb_buffer_pool_dump_at_shutdown或 innodb_buffer_pool_dump_now。表空间ID和网页ID保存在以下格式: 空间,page_id 。默认情况下,文件名为 ib_buffer_pool位于 InnoDB 数据目录。必须指定非默认位置相对于数据目录。 文件名可以在运行时指定使用 SET声明: SET GLOBAL innodb_buffer_pool_filename=
'file_name'; 你也可以在启动时指定一个文件名,在启动字符串或MySQL的配置文件。当指定一个文件名在启动时,该文件必须存在或 InnoDB将返回一个启动错误说明没有这样的文件或目录。 有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” 财产 价值 命令行格式 --innodb-buffer-pool-instances=#系统变量 innodb_buffer_pool_instances范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 (其他) 8 (or 1 if innodb_buffer_pool_size < 1GB默认值 (Windows 32位平台) (autosized)最小值 1最大值 64在一些地区, InnoDB缓冲池 分为。在多字节范围的缓冲池系统,将缓冲池为单独的实例可以提高并发性,减少争用不同的线程读写缓存页。每一页都存储在缓冲池中读取或被分配到一个缓冲池的情况下,随机,使用哈希函数。每个缓冲池管理自己的自由列表, 刷新列表 , LRU ,和所有其他数据结构连接缓冲池,并由它自己的缓冲池的保护 互斥 此选项仅当设置生效 innodb_buffer_pool_size1GB以上。总的缓冲池大小的缓冲池中分。最佳的效率,指定一个组合 innodb_buffer_pool_instances和 innodb_buffer_pool_size所以,每个缓冲池实例至少1GB。 在32位Windows系统的默认值取决于值 innodb_buffer_pool_size下面,我described: 如果 innodb_buffer_pool_size大于1.3gb,默认为 innodb_buffer_pool_instances是 innodb_buffer_pool_size/ 128MB,为每一块单独的内存分配请求。1.3gb为边界,有32位Windows无法分配一个缓冲池所需的连续地址空间的重大风险。 否则,默认的是1
在所有其他平台,默认值是8的时候 innodb_buffer_pool_size大于或等于1GB。否则,默认是1。 相关的信息,看 第15.6.3.2,“配置InnoDB缓冲池大小” 财产 价值 命令行格式 --innodb-buffer-pool-load-abort=#系统变量 innodb_buffer_pool_load_abort范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF中断恢复过程 InnoDB缓冲池 触发器 innodb_buffer_pool_load_at_startup或 innodb_buffer_pool_load_now有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” innodb_buffer_pool_load_at_startup财产 价值 命令行格式 --innodb-buffer-pool-load-at-startup=#系统变量 innodb_buffer_pool_load_at_startup范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 ON指定MySQL服务器启动时,的, InnoDB缓冲池 自动 热身 通过加载它在早些时候同一页。通常结合使用 innodb_buffer_pool_dump_at_shutdown两 innodb_buffer_pool_dump_at_shutdown和 innodb_buffer_pool_load_at_startup 默认情况下启用 有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” 财产 价值 命令行格式 --innodb-buffer-pool-load-now=#系统变量 innodb_buffer_pool_load_now范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF立即 热身 这个 InnoDB缓冲池 通过加载的数据页,无需等待服务器重启。可以将缓存返回到已知状态在标杆有用,或准备好的MySQL服务器运行报告或维护查询后恢复其正常的工作量。 有关更多信息,参见 第15.6.3.8,“保存和恢复缓冲池的状态” 财产 价值 命令行格式 --innodb-buffer-pool-size=#系统变量 innodb_buffer_pool_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 134217728最小值 5242880最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1在字节的大小 缓冲池 记忆的地方, InnoDB缓存表和索引数据。默认值是134217728字节(128MB)。最大值取决于CPU的体系结构;最大值为4294967295(2 三十二 -1)在32位系统和18446744073709551615(2 六十四 1)64位系统。在32位系统,CPU架构和操作系统可以处以较低的实际最大尺寸比规定的最大值。当缓冲池的大小大于1GB,设置 innodb_buffer_pool_instances一个大于1的值可以提高在一个繁忙的服务器的可扩展性。 一个更大的缓冲池需要更少的磁盘I/O访问同一个表中的数据超过一次。在一个专用的数据库服务器,你可以设置缓冲池大小的百分之八十的机器的物理内存的大小。请注意以下潜在的问题,当配置缓冲池的大小,并准备缩减缓冲池的大小如果有必要。 物理内存的竞争会导致操作系统分页。 InnoDB储备额外的内存缓冲区和控制结构,使总分配空间是比指定的缓冲池大小约10%.。 地址缓冲池空间必须是连续的,它可以是一个问题,在Windows系统的DLL特定地址的负载。 时间初始化缓冲池的大小成正比。对大缓冲池的情况下,初始化的时间可能是重要的。减少初始化期间,你可以保存在缓冲池的状态服务器的关闭和恢复它在服务器启动。看到 第15.6.3.8,“保存和恢复缓冲池的状态”
当你增加或减少缓冲池的大小,执行运算块。块的大小是确定的 innodb_buffer_pool_chunk_size配置选项,其中有一个默认的128 MB。 缓冲池的大小必须等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances。如果你更改缓冲池的尺寸值不等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instances缓冲池的大小,自动调整到一个值等于或多 innodb_buffer_pool_chunk_size* innodb_buffer_pool_instancesinnodb_buffer_pool_size可动态设置,可让您调整缓冲池,无需重新启动服务器。这个 Innodb_buffer_pool_resize_status状态变量的报告在线缓冲池大小操作的状态。看到 第15.6.3.2,“配置InnoDB缓冲池大小” 更多信息 如果 innodb_dedicated_server启用的 innodb_buffer_pool_size值是自动配置如果它没有明确的定义。有关更多信息,参见 第15.6.13,“启用自动配置一个专用的MySQL服务器” 财产 价值 命令行格式 --innodb-change-buffer-max-size=#系统变量 innodb_change_buffer_max_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 25最小值 0最大值 50为最大尺寸 InnoDB变化的缓冲 ,作为总的大小的百分比 缓冲池 。你可以增加这个值为重的插入、更新和删除MySQL服务器,活动,或减少这一不变的MySQL服务器用于报告数据。有关更多信息,参见 第15.4.2,“Change Buffer” ,和 第15.6.4配置变化,InnoDB缓冲” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-change-buffering=#系统变量 innodb_change_buffering范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 all有效值 noneinsertsdeleteschangespurgesall是否 InnoDB执行 变化的缓冲 ,优化延迟写操作的次要指标,使I/O操作可以按顺序执行。允许值如下表描述。值也可以指定数值。 表15.20的允许值innodb_change_buffering 价值 数字值 描述 none0没有缓冲区的任何操作。 inserts1缓冲器插入操作 deletes2缓冲区删除标记操作;严格地说,写,标记索引记录后删除清洗操作过程。 changes3缓冲器插入和删除标记操作。 purges4缓冲区的物理删除操作发生在后台。 all5默认的。缓冲区插入,删除标记操作和清洗。 有关更多信息,参见 第15.4.2,“Change Buffer” ,和 第15.6.4配置变化,InnoDB缓冲” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-change-buffering-debug=#系统变量 innodb_change_buffering_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最大值 2设置一个调试标志 InnoDB变化的缓冲。1值的力量改变缓冲区的所有变化。2值导致崩溃在合并。默认值0表示变化的缓冲调试标志没有设置。此选项仅当调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-checkpoint-disabled=#介绍 8.0.2 系统变量 innodb_checkpoint_disabled范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF这是一个调试选项只用于专家调试使用。它禁用检查站,故意服务器出口一直倡导 InnoDB恢复它应该只是一个短的间隔功能,通常在运行DML操作写入重做日志条目,需要恢复服务器退出。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-checksum-algorithm=#系统变量 innodb_checksum_algorithm范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 crc32有效值 innodbcrc32nonestrict_innodbstrict_crc32strict_none指定如何生成和验证 校验和 存储在磁盘块 InnoDB表空间 。默认值为 innodb_checksum_algorithm是 CRC32 版本 MySQL企业备份 到3.8.0不支持备份表空间使用crc32校验。 MySQL企业备份 在3.8.1添加CRC32校验的支持,具有一定的局限性。指的是 MySQL企业备份 3.8.1改变历史的更多信息。 的价值 innodb向后兼容早期版本的MySQL。的价值 CRC32 使用一个更快的计算每一个修改过的块的校验算法,并检查校验和为每个磁盘的读。它扫描块32位一次,这是速度比 innodb校验算法,扫描块在8位的时间。的价值 无 写一个定值的校验和字段而不是计算值基于数据块。在一个表空间的块可以混合使用旧的,新的,没有校验值,作为数据被修改,逐步更新;一旦在一个表空间的块被修改为使用 crc32算法,相关的表不能由早期版本的MySQL读。 一个校验和算法的严格形式报告错误,如果遇到一个有效的而非一个表空间中的校验和值匹配。建议你在一个新的实例只能使用严格的设置,设置为第一次的表空间。严格的设置是稍快,因为他们不需要计算校验值在所有磁盘读取。 下表显示之间的差异 none, InnoDB ,和 crc32选项的值,和他们的严格的同行。 无 , innodb,和 CRC32 写入指定的类型为每个数据块的校验值,但兼容性接受其他校验值验证时一块读操作期间。严格的设置也接受有效的校验值但打印错误消息时,一个有效的非匹配校验值时。使用严格的形式能使验证更快如果所有 InnoDB在一个实例的数据文件在相同的创建 innodb_checksum_algorithm 价值 表15.21允许innodb_checksum_algorithm值 价值 生成的校验(写作时) 允许校验(读书的时候) 无 一个常数 生成的任何校验和 none, InnoDB ,或 crc32InnoDB 校验和的计算软件,使用原来的算法 InnoDB生成的任何校验和 none, InnoDB ,或 crc32CRC32 校验和计算 crc32算法,可能做一个硬件辅助。 生成的任何校验和 none, InnoDB ,或 crc32strict_none 一个常数 生成的任何校验和 none, InnoDB ,或 crc32InnoDB 打印一个错误信息如果有效但不匹配的校验和时。 strict_innodb 校验和的计算软件,使用原来的算法 InnoDB生成的任何校验和 none, InnoDB ,或 crc32InnoDB 打印一个错误信息如果有效但不匹配的校验和时。 strict_crc32 校验和计算 crc32算法,可能做一个硬件辅助。 生成的任何校验和 none, InnoDB ,或 crc32InnoDB 打印一个错误信息如果有效但不匹配的校验和时。 财产 价值 命令行格式 --innodb-cmp-per-index-enabled=#系统变量 innodb_cmp_per_index_enabled范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF有效值 OFFON使每个索引中的相关统计数据压缩 INFORMATION_SCHEMA.INNODB_CMP_PER_INDEX表因为这些数据可以是昂贵的收集,只有启用此选项在开发,测试,或从实例中的性能调优相关 InnoDB 压缩的 表 有关更多信息,参见 第24.35.7,“information_schema innodb_cmp_per_index和innodb_cmp_per_index_reset表” ,和 第15.9.1.4,“运行时”InnoDB表压缩监控 财产 价值 命令行格式 --innodb-commit-concurrency=#系统变量 innodb_commit_concurrency范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 1000数 螺纹 可以 犯罪 在同一时间。值0(默认值)允许任意数量的 交易 同时承诺 价值 innodb_commit_concurrency不能在运行时改变从零到零或反之亦然。该值可以从一个非零的值更改为另一个。 财产 价值 命令行格式 --innodb-compress-debug=#系统变量 innodb_compress_debug范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 none有效值 nonezliblz4lz4hc把所有的表没有定义一个使用指定的压缩算法 COMPRESSION每个表的属性。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 相关的信息,看 第15.9.2,“InnoDB页面压缩” innodb_compression_failure_threshold_pct财产 价值 命令行格式 --innodb-compression-failure-threshold-pct=#系统变量 innodb_compression_failure_threshold_pct范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 5最小值 0最大值 100定义一个表的压缩失效率的门槛,作为一个百分比,此时开始添加填充在MySQL 压缩的 网页避免昂贵的 压缩失败 。当通过此阈值,MySQL开始在每一个新的压缩页面留下更多的自由空间,动态调整量的自由空间到页面大小指定的百分比 innodb_compression_pad_pct_max。零值禁用机制监视压缩效率和动态调整填充量。 有关更多信息,参见 第15.9.1.6,“压缩的OLTP工作负载” 财产 价值 命令行格式 --innodb-compression-level=#系统变量 innodb_compression_level范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 6最小值 0最大值 9指定使用zlib压缩水平 InnoDB压缩的 表和索引。较高的值可以容纳更多的数据到一个存储设备,在更多的CPU开销的费用在压缩。一个较低的值可以减少CPU开销在存储空间并不重要,或者你期望的数据是不可压缩的。 有关更多信息,参见 第15.9.1.6,“压缩的OLTP工作负载” innodb_compression_pad_pct_max财产 价值 命令行格式 --innodb-compression-pad-pct-max=#系统变量 innodb_compression_pad_pct_max范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 50最小值 0最大值 75指定可以保留在每个压缩自由空间的最大百分比 网页 ,让房间整理数据和修改日志内页时 压缩的 表或索引的更新和数据可能被压缩。只适用于当 innodb_compression_failure_threshold_pct设置为非零值,并率 压缩失败 通过临界点 有关更多信息,参见 第15.9.1.6,“压缩的OLTP工作负载” 财产 价值 命令行格式 --innodb-concurrency-tickets=#系统变量 innodb_concurrency_tickets范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 5000最小值 1最大值 4294967295determines the number of 螺纹 能进入 InnoDB同时。一个线程被放置在一个队列时,它试图进入 InnoDB 如果线程数已经达到并发上限。当一个线程被允许进入 InnoDB,它是一个特定的数 “ 票 “ 相等的价值 innodb_concurrency_tickets,和线程可以进入和离开 InnoDB 在使用之前都可以自由的门票。在这一点上,线程再次被并发检查约束(和可能的排队)下一次试图进入 InnoDB。默认值是5000 用一个小的 innodb_concurrency_tickets值,只需要几行过程公平竞争与较大的交易过程中的许多行小交易。一个小的缺点 innodb_concurrency_tickets 价值是大的交易必须通过循环队列多次才可以完成,扩展需要完成任务的时间。 有一个大的 innodb_concurrency_tickets大的交易价值,花更少的时间等待排在最后一位(控制 innodb_thread_concurrency)和更多的时间检索行。大的交易也需要更少的旅行通过队列来完成他们的任务。一个大的缺点 innodb_concurrency_tickets 价值是,太多的交易在同一时间运行能使较小的交易让他们等待更长的时间才执行。 一个非零 innodb_thread_concurrency值,你可能需要调整 innodb_concurrency_tickets 价值上升或下降到较大和较小的交易之间的最佳平衡。这个 SHOW ENGINE INNODB STATUS报告显示,其余为执行交易的电流通过排队购票数量。这个数据也可以得到 trx_concurrency_tickets 列的 INFORMATION_SCHEMA.INNODB_TRX表 有关更多信息,参见 第15.6.5,“配置InnoDB线程并发 财产 价值 命令行格式 --innodb-data-file-path=name系统变量 innodb_data_file_path范围 全球 动态 否 set_var 提示应用 否 类型 字符串 默认值 ibdata1:12M:autoextend定义名称,大小,和属性 InnoDB系统片 数据文件 。如果你不指定一个值 innodb_data_file_path,默认行为是创建一个单一的自动扩展数据文件,略大于12MB的,命名为 ibdata1 一个数据文件规范完整的语法包括文件名,文件大小,和 autoextend和 最大值 属性: file_name:file_size[:autoextend[:max:max_file_size]]文件大小指定KB、MB或GB(即1024MB)通过添加 K, M 或 G的大小值。如果指定字节的数据文件大小(KB),倍数的1024这样做。否则,KB值舍入到最近的兆字节(MB)的边界。对文件的大小的总和至少要稍大于12mb。 最小的文件大小是强制的 第一 SYSTEM表空间的数据文件,以确保有足够的空间doublewrite缓冲页: 对于一个 innodb_page_size16Kb或价值较小,最小的文件大小为3MB。 对于一个 innodb_page_size值32KB,最小的文件大小为6MB。 对于一个 innodb_page_size值为64KB,最小的文件大小是12mb。
单个文件的大小限制是由操作系统决定的。你可以设置文件的大小超过4GB,支持大文件的操作系统。你也可以 使用原始磁盘分区的数据文件 这个 autoextend和 最大值 属性可以只用于指定数据文件中的最后一个 innodb_data_file_path设置。例如: [mysqld]innodb_data_file_path=ibdata1:50M;ibdata2:12M:autoextend:max:500MB
如果您指定的 autoextend选项, InnoDB 扩展数据文件,如果它运行的自由空间。这个 autoextend增量64mb默认。修改增加,改变 innodb_autoextend_increment系统变量 系统表空间的数据文件的完整目录路径是通过连接定义的路径的形成 innodb_data_home_dir和 innodb_data_file_path 有关配置系统表空间的数据文件的更多信息,参见 第15.6.1,“InnoDB启动配置” 财产 价值 命令行格式 --innodb-data-home-dir=dir_name系统变量 innodb_data_home_dir范围 全球 动态 否 set_var 提示应用 否 类型 目录名称 对于目录路径的共同部分 InnoDB系统片 数据文件。此设置不影响定位 文件表 表空间时 innodb_file_per_table启用。默认值是MySQL 数据 目录如果你指定的值为空字符串,你可以指定一个绝对文件路径 innodb_data_file_path一个斜线,需要指定一个值时 innodb_data_home_dir。。。。。。。例如: [mysqld]innodb_data_home_dir = /path/to/myibdata/
相关的信息,看 第15.6.1,“InnoDB启动配置” innodb_ddl_log_crash_reset_debug财产 价值 命令行格式 --innodb-ddl-log-crash-reset-debug=#介绍 8.0.3 系统变量 innodb_ddl_log_crash_reset_debug范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 False启用调试选项重置DDL日志碰撞喷油柜1。此选项仅当调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-deadlock-detect系统变量 innodb_deadlock_detect范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON使用此选项来禁用死锁检测。在高并发系统中,死锁检测可以造成经济放缓时多线程等待同一个锁。有时,它可能是更有效地禁用死锁检测和依靠 innodb_lock_wait_timeout设置事务回滚时,死锁发生。 相关的信息,看 第15.5.5.2,“死锁检测和回滚” 财产 价值 命令行格式 --innodb-dedicated-server=#介绍 8.0.3 系统变量 innodb_dedicated_server范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF什么时候 innodb_dedicated_server启用, InnoDB 自动配置选项,根据服务器上检测到的内存量: 只考虑启用这个选项如果你的MySQL实例运行在一个专用的服务器,MySQL服务器能够消耗所有可用的系统资源。启用此选项不如果你的MySQL实例共享系统资源和其他应用的建议。 有关更多信息,参见 第15.6.13,“启用自动配置一个专用的MySQL服务器” 财产 价值 命令行格式 --innodb-default-row-format=#系统变量 innodb_default_row_format范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 DYNAMIC有效值 DYNAMICCOMPACTREDUNDANT这个 innodb_default_row_format选项定义默认行格式 InnoDB 表和用户创建的临时表。默认设置是 DYNAMIC。其他的允许值 粉盒 和 REDUNDANT。这个 压缩的 行格式,这是不使用的支持 系统片 ,不能定义为默认 新创建的表用来定义行格式 innodb_default_row_format当一个 row_format 选项不明确指定或当 ROW_FORMAT=DEFAULT使用 当一个 ROW_FORMAT选项不明确指定或当 ROW_FORMAT=DEFAULT使用任何操作,重建表也默默地改变表格的行格式定义的格式 innodb_default_row_format。有关更多信息,参见 第15.10.2,“指定行格式为表” 内部 InnoDB临时表创建由服务器处理查询的使用 动态 行格式,不管的 innodb_default_row_format设置 财产 价值 命令行格式 --innodb-directories=#介绍 8.0.4 系统变量 innodb_directories范围 全球 动态 否 set_var 提示应用 否 类型 字符串 定义目录扫描表空间文件启动。使用此选项,当移动或恢复表空间文件到一个新的位置,当服务器脱机。它还用于指定使用绝对路径创建表空间文件目录或驻留的数据目录之外。 目录定义 innodb_data_home_dir, innodb_undo_directory,和 datadir自动添加到 innodb_directories论点价值,毫不留情地 innodb_directories选项指定明确的 innodb_directories可以指定在启动命令或在MySQL选项文件选项。行情是在参数值用否则分号(;)是由一些命令解释器解释为一个特殊的字符。(UNIX shell作为命令终止符,例如。) 启动命令: mysqld --innodb-directories="
directory_path_1;directory_path_2"MySQL选项文件: [mysqld] innodb_directories="
directory_path_1;directory_path_2"通配符表达式不能用于指定目录。 这个 innodb_directories扫描指定的目录的子目录也穿越。复制目录和子目录被丢弃从目录列表进行扫描。 有关更多信息,参见 第15.7.7,“移动表空间文件,当服务器脱机” innodb_disable_sort_file_cache财产 价值 命令行格式 --innodb-disable-sort-file-cache=#系统变量 innodb_disable_sort_file_cache范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF禁用操作系统的文件系统缓存归并排序的临时文件。效果与相当于打开这个文件 O_DIRECT财产 价值 命令行格式 --innodb-doublewrite系统变量 innodb_doublewrite范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 ONWhen enabed(The default), InnoDB存储所有数据两次,先 doublewrite缓冲 而现在 数据文件 。这个变量可以关闭 --skip-innodb_doublewrite为基准或案件时,最高性能的需要而不是关注数据完整性或可能出现的故障。 如果系统表空间的数据文件( ibdata*文件)位于融合IO设备支持原子写道,doublewrite缓冲自动禁用,Fusion-io原子将用于所有数据文件。因为doublewrite缓冲的设置是全局的,doublewrite缓冲也是数据文件驻留在非融合IO硬件禁用。此功能仅对Fusion-io硬件只启用了Fusion-io nvmfs Linux支持。要充分利用这一特点, innodb_flush_method设置 直接_ O 推荐 相关的信息,看 第15.4.6,“Doublewrite Buffer” 财产 价值 命令行格式 --innodb-fast-shutdown[=#]系统变量 innodb_fast_shutdown范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 1有效值 012这个 InnoDB关机 模式。如果值为0, InnoDB做一个 缓慢关闭 ,全 净化 和改变缓冲区合并前关闭。如果该值为-1(默认), InnoDB跳过这些操作在关闭时,这个过程称为 快速关机 。如果该值为2, InnoDB将其日志和关闭冷,如果MySQL撞;没有提交的事务都失去了,但 崩溃恢复 操作使得下一次启动需要更长的时间。 慢关机可能需要几分钟,甚至几小时在极端情况下,大量的数据仍然是缓冲。MySQL的主要版本之间升级或降级使用前慢关断技术,使所有的数据文件都在升级更新文件格式的充分准备。 使用 innodb_fast_shutdown=2在急救或故障的情况下,如果数据损坏风险获取最快关机。 innodb_fil_make_page_dirty_debug财产 价值 命令行格式 --innodb-fil-make-page-dirty-debug=#系统变量 innodb_fil_make_page_dirty_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最大值 2**32-1默认情况下,设置 innodb_fil_make_page_dirty_debug在一个表空间ID立即垢表空间的第一页。如果 innodb_saved_page_number_debug设置为非默认值,设置 让_ InnoDB _费尔_ _调试_脏页 垢指定页。这个 innodb_fil_make_page_dirty_debug选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-file-per-table系统变量 innodb_file_per_table范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON什么时候 innodb_file_per_tableThe default . InnoDB 存储数据和索引的每个新创建的表在一个单独的 .ibd文件 而不是SYSTEM表空间。这些表的存储回收当表删除或截断。此设置启用 InnoDB 如表特征 压缩 。看到 第15.7.4“InnoDB文件,每个表的表空间” 更多信息 有可能 innodb_file_per_table也意味着一个 ALTER TABLE操作动作 InnoDB 从系统表空间到一个单独的表 .ibd文件的情况下 ALTER TABLErebuilds(the table ALGORITHM=COPY)。这个规则的一个例外是放置在系统表空间表的使用 TABLESPACE=innodb_system选项 CREATE TABLE或 ALTER TABLE。这些表是不受影响的 innodb_file_per_table 设置只能移动到文件的每个表的表空间使用 ALTER TABLE ... TABLESPACE=innodb_file_per_table什么时候 innodb_file_per_table被禁用, InnoDB 存储在表和索引数据 ibdata文件 构成 系统片 。这个设置可以减少操作如文件系统操作的性能开销 DROP TABLE或 TRUNCATE TABLE。这是最合适的服务器环境,整个存储设备致力于MySQL数据。因为SYSTEM表空间没有缩小,并共享所有数据库中 实例 ,避免加载大量在空间受限的系统临时数据时 innodb_file_per_table被禁用。在这种情况下,建立一个单独的实例,这样就可以降低整个实例的回收空间。 innodb_file_per_table默认情况下启用。考虑禁用如果mysql 5.5或更早的向后兼容性是一个问题。这将防止 ALTER TABLE从运动 InnoDB表空间到个人from the system 鸡传染性法氏囊病 文件 innodb_file_per_table是动态的,可以设置 打开(放) 或 OFF使用 设置全局 。你也可以在MySQL设置这个选项 配置文件 ( my.cnf或 my.ini )但这需要关闭和重新启动服务器。 动态变化的价值要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权和立即影响所有连接的操作。 这个 innodb_file_per-table设置不影响创作 InnoDB 临时表。在 InnoDB临时表在共享临时表空间中创建。 财产 价值 命令行格式 --innodb-fill-factor=#系统变量 innodb_fill_factor范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 100最小值 10最大值 100InnoDB执行大容量加载创建或重新生成索引时。这个索引创建的方法称为 “ 排序的索引构建 “ innodb_fill_factor定义空间的百分比在每个树页填充排序索引建立的过程,用剩余的空间留给未来的指数增长。例如,设置 innodb_fill_factor 80储量的空间为未来的指数增长各树20%页。实际的比例可能会有所不同。这个 innodb_fill_factor设置被解释为暗示而不是硬限制。 一个 innodb_fill_factor100叶簇自由未来的指数增长的索引页1/16的空间设置。 innodb_fill_factor适用于B树的叶与非叶级页。它不适用于用于外部页 TEXT或 BLOB条目. 有关更多信息,参见 第15.8.2.3,“分类指标” 财产 价值 系统变量 innodb_flush_log_at_timeout范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 1最小值 1最大值 2700写日志都冲洗 N秒 innodb_flush_log_at_timeout允许在冲超时时间要增加以减少冲洗和避免二进制日志组影响性能的承诺。设置为默认 innodb_flush_log_at_timeout是每秒一次 innodb_flush_log_at_trx_commit财产 价值 命令行格式 --innodb-flush-log-at-trx-commit[=#]系统变量 innodb_flush_log_at_trx_commit范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 1有效值 012严格控制之间的平衡 酸 依从性 犯罪 操作和更高的性能,可能当提交相关的I/O操作的重组和分批进行。你可以实现更好的性能,通过改变默认值,但你可能会失去多达二在交易的崩溃。 一个值为0的内容, InnoDB日志缓冲区写入到日志文件约每秒一次日志文件刷新到磁盘。没有写日志缓冲区的日志文件进行事务提交。每秒一次冲洗不100%保证发生的每一秒,由于进程调度问题。因为磁盘操作只发生约每秒一次的刷新,你可以失去了一次交易的任何 mysqld 进程崩溃 一个值为2的内容, InnoDB日志缓冲区写入到日志文件的每个事务的提交和日志文件刷新到磁盘后约每秒一次。每秒一次冲洗是不能保证每天都会发生二由于进程调度问题。因为磁盘操作只发生约每秒一次的刷新,你可以失去了一次在操作系统崩溃的交易或停电。 InnoDB日志冲洗频率控制 innodb_flush_log_at_timeout,它允许你设置日志冲洗频率 N秒(其中 N是 1…二千七百 ,用默认值1)。然而,任何 mysqld 进程崩溃可以抹去了 N第二交易 DDL更改和其他内部 InnoDB活动冲洗 InnoDB independently的日志 innodb_flush_log_at_trx_commit设置DDL日志总是冲在提交事务。 InnoDB崩溃恢复 作品无论在 innodb_flush_log_at_trx_commit设置交易都是采用完全或完全删除。
在复制设置,使用耐久性和一致性 InnoDB与交易: 如果启用了二进制日志,设置 sync_binlog=1总是设置 innodb_flush_log_at_trx_commit=1
注意安全 许多操作系统和磁盘硬件傻瓜刷新到磁盘操作。他们可能会告诉 mysqld ,冲洗已经发生,即使它没有。在这种情况下,交易的耐久性是不是推荐的设置保证,在最坏的情况下,停电可以腐败 InnoDB数据在SCSI磁盘控制器或磁盘本身加快文件刷新使用电池备份磁盘高速缓存,使操作更安全。你也可以尝试禁用缓存写入磁盘的硬件高速缓存。 财产 价值 命令行格式 --innodb-flush-method=name系统变量 innodb_flush_method范围 全球 动态 否 set_var 提示应用 否 类型 字符串 默认值 (Windows) unbuffered默认值 (UNIX) fsync有效值 (Windows) unbufferednormal有效值 (UNIX) fsyncO_DSYNClittlesyncnosyncO_DIRECTO_DIRECT_NO_FSYNC用来定义的方法 脸红 数据 InnoDB数据文件 和 日志文件 ,从而影响I/O吞吐量。 在类Unix系统,默认值是 fsync。在Windows中,默认值是 无缓冲 笔记 在MySQL 5.0, innodb_flush_method选项可以指定数值 这个 innodb_flush_method类UNIX系统的选项包括: fsync或 零 : InnoDB使用 fsync() 系统调用同花顺的数据文件和日志文件。 fsync是默认设置 O_DSYNC或 一 : InnoDB使用 法语语法语法 打开并刷新日志文件,和 fsync()将数据文件 InnoDB 不使用 O_DSYNC正因为有问题在许多的Unix变种。 littlesync或 二 :此选项用于内部性能测试,目前不支持。使用您自己的风险。 nosync或 三 :此选项用于内部性能测试,目前不支持。使用您自己的风险。 O_DIRECT或 四 : InnoDB使用 直接_ O (或 directio()在Solaris)打开数据文件,并使用 fsync() 刷新的数据和日志文件。这个选项是FreeBSD,一些GNU / Linux和Solaris版本,可用。 O_DIRECT_NO_FSYNC或 五 : InnoDB使用 直接_ O 在冲洗的I / O,但跳过 fsync()系统调用之后。此设置适用于某些类型的文件系统,而不是其他。例如,它不适用于XFS。如果你不确定你是否使用文件系统需要一个 fsync() ,例如保存所有文件的元数据,使用 O_DIRECT相反
这个 innodb_flush_methodWindows系统选项包括: unbuffered或 零 : InnoDB利用模拟异步I/O和非缓冲的I / O. normal或 一 : InnoDB利用模拟异步I/O和缓冲我/ O.
每个设置如何影响性能取决于硬件配置和工作量。基准您的特定配置来决定设置使用,或是否保留默认设置。检查 Innodb_data_fsyncs状态变量看整体数量 fsync() 为每个呼叫。混读和写操作会影响你的工作表现如何设置。例如,在一个硬件RAID控制器和电池备份系统的写缓存, O_DIRECT可以帮助避免双缓冲间 InnoDB 缓冲池和操作系统的文件系统缓存。在一些系统中 InnoDB数据和日志文件位于三、默认值或 o_dsync 可能是快读的工作量多 SELECT声明.一直以硬件和工作量,反映您的生产环境试验参数。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 如果 innodb_dedicated_server启用的 innodb_flush_method值是自动配置如果它没有明确的定义。有关更多信息,参见 第15.6.13,“启用自动配置一个专用的MySQL服务器” 财产 价值 命令行格式 --innodb-flush-neighbors系统变量 innodb_flush_neighbors范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 (>= 8.0.3)0默认值 (<= 8.0.2)1有效值 012指定是否 冲洗 从一个页面 InnoDB缓冲池 所以其他的冲 脏页 在相同的 程度 在弯曲的背景 innodb_flush_neighbors从没有其他脏页从缓冲池冲洗。 设置1冲连续在同一程度的脏页从缓冲池。 从缓冲池在同一程度上设置2冲脏页。
表中的数据时,存储在一个传统的 硬盘 存储装置、冲洗等 邻居页 在一个操作中减少I/O开销(主要用于磁盘寻道操作)相比,在不同时代的个人页面冲洗。存储在表中的数据 SSD ,寻找时间不是一个重要的因素,你可以设置这个选项为0展开写操作。相关的信息,看 第15.6.3.7,“微调InnoDB缓冲池冲洗” 财产 价值 命令行格式 --innodb-flush-sync=#系统变量 innodb_flush_sync范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON这个 innodb_flush_sync参数,默认情况下是启用的,原因 innodb_io_capacity设置被忽略阵阵I/O活动发生在 检查站 。坚持限制 InnoDB通过定义背景的I/O活动 innodb_io_capacity设置,禁用 InnoDB _冲_ sync 相关的信息,看 第15.6.8,“配置InnoDB主线程I/O率” 财产 价值 命令行格式 --innodb-flushing-avg-loops=#系统变量 innodb_flushing_avg_loops范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 30最小值 1最大值 1000迭代的次数 InnoDB保持先前计算的快照冲洗状态,控制如何快速 自适应刷新 响应变化 工作负载 。增加值率 脸红 业务工作量变化平稳,逐步改变。降低值进行自适应冲洗迅速适应工作负载的变化,从而导致尖峰冲洗活动如果工作量的增加和减少突然。 相关的信息,看 第15.6.3.7,“微调InnoDB缓冲池冲洗” 财产 价值 命令行格式 --innodb-force-load-corrupted系统变量 innodb_force_load_corrupted范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF许可证 InnoDB在启动时被标记为损坏的负荷表。使用只有在排除故障,恢复,否则无法访问数据。当故障排除是完整的,禁用此设置并重新启动服务器。 财产 价值 命令行格式 --innodb-force-recovery=#系统变量 innodb_force_recovery范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 6这个 崩溃恢复 模式,通常只发生在严重故障情况。可能的值是从0到6。这些值的意义和重要的信息 innodb_force_recovery,看到 第15.20.2,迫使InnoDB恢复” 财产 价值 命令行格式 --innodb-ft-aux-table=#系统变量 innodb_ft_aux_table范围 全球 动态 是 set_var 提示应用 否 类型 字符串 指定一个名称 InnoDB表包含一个 全文 指数这个变量是用于诊断目的。 当你设置这个变量名称的格式 db_name/table_name,的 information_schema 表 INNODB_FT_INDEX_TABLE, INNODB_FT_INDEX_CACHE, INNODB_FT_CONFIG, INNODB_FT_DELETED,和 INNODB_FT_BEING_DELETED关于搜索索引信息为指定的表。 财产 价值 命令行格式 --innodb-ft-cache-size=#系统变量 innodb_ft_cache_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 8000000最小值 1600000最大值 80000000内存分配,以字节为单位,为 InnoDB全文 搜索索引缓存,具有解析内存中的文档创建 InnoDB全文 指数索引的插入和更新只提交到磁盘时 innodb_ft_cache_size达到大小限制 innodb_ft_cache_size 定义缓存大小对每个表的基础。设置所有表全球极限,看 innodb_ft_total_cache_size有关更多信息,参见 InnoDB全文索引缓存 财产 价值 命令行格式 --innodb-ft-enable-diag-print=#系统变量 innodb_ft_enable_diag_print范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF是否启用额外的全文搜索(FTS)诊断输出。该选项主要用于先进的FTS调试并不会对大多数用户。打印输出到错误日志信息包括: FTS指数同步的进步(当FTS缓存达到极限)。例如: FTS SYNC for table test, deleted count: 100 size: 10000 bytes SYNC words: 100
FTS的优化进程。例如: FTS start optimize test FTS_OPTIMIZE: optimize "mysql" FTS_OPTIMIZE: processed "mysql"
CTS建立进度指标。例如: Number of doc processed: 1000
FTS的查询,查询的语法分析树,字的重量,查询处理时间和内存的使用,印刷。例如: FTS Search Processing time: 1 secs: 100 millisec: row(s) 10000 Full Search Memory: 245666 (bytes), Row: 10000
财产 价值 命令行格式 --innodb-ft-enable-stopword=#系统变量 innodb_ft_enable_stopword范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON指定一组 停用词 与一 InnoDB全文 当时创建索引。如果 innodb_ft_user_stopword_table选项设置、停用词是从那张桌子。否则,如果 innodb_ft_server_stopword_table选项设置、停用词是从那张桌子。否则,一个内置的设置应用默认的构建。 有关更多信息,参见 第12.9.4,“全文构建” 财产 价值 命令行格式 --innodb-ft-max-token-size=#系统变量 innodb_ft_max_token_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 84最小值 10最大值 84的话,都存储在一个最大字符长度 InnoDB全文 指数设置在这个价值限度减少索引的大小,从而加快查询,省去长关键词或字母的任意集合,不真实的话,是不可能的搜索词。 有关更多信息,参见 第12.9.6,“微调MySQL全文搜索” 财产 价值 命令行格式 --innodb-ft-min-token-size=#系统变量 innodb_ft_min_token_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 3最小值 0最大值 16的话,都存储在一个最小长度 InnoDB全文 指数增加这个值减少索引的大小,从而加快查询,通过省略常用字,不太可能在搜索方面是重要的,如英语单词 “ 一 “ 和 “ 到 “ 。使用CJK(中国、日本、韩国的内容)的字符集,指定值1。 有关更多信息,参见 第12.9.6,“微调MySQL全文搜索” 财产 价值 命令行格式 --innodb-ft-num-word-optimize=#系统变量 innodb_ft_num_word_optimize范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 2000在每个单词的进程数 OPTIMIZE TABLE操作上 InnoDB FULLTEXT指数因为批量插入或更新操作的表包含全文搜索索引可能需要大量的索引维护纳入所有的改变,你可能会做一系列的 OPTIMIZE TABLE报表,每次拿起最后离开了。 有关更多信息,参见 第12.9.6,“微调MySQL全文搜索” 财产 价值 命令行格式 --innodb-ft-result-cache-limit=#系统变量 innodb_ft_result_cache_limit范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 2000000000最小值 1000000最大值 2**32-1这个 InnoDB全文搜索查询结果缓存限制(定义字节)/全文搜索查询或每线程。中间和最后 InnoDB 全文搜索查询结果处理在内存中。使用 innodb_ft_result_cache_limit地方上的全文搜索查询结果缓存大小限制以避免在非常大的情况下过度消费的记忆 InnoDB 全文搜索查询结果(例如百万行,百万或数百个)。分配内存时的全文搜索的查询处理。如果结果缓存大小限制时,将返回一个错误提示查询超过了允许的最大内存。 最大值 innodb_ft_result_cache_limit所有平台的类型和位大小是2×32-1。 innodb_ft_server_stopword_table财产 价值 命令行格式 --innodb-ft-server-stopword-table=db_name/table_name系统变量 innodb_ft_server_stopword_table范围 全球 动态 是 set_var 提示应用 否 类型 字符串 默认值 NULL此选项用于指定您自己的 InnoDB全文 索引字列表 InnoDB表配置你自己的停用词表为特定 InnoDB 表,使用 innodb_ft_user_stopword_table配置 innodb_ft_server_stopword_table包含列表的停用词的表的名称,在格式 db_name/ table_name停用词表必须在配置存在 innodb_ft_server_stopword_tableinnodb_ft_enable_stopword 必须启用 innodb_ft_server_stopword_table选择之前必须配置你的创造 全文 指数 停用词表必须 InnoDB表,包含一个 varchar 命名列 value有关更多信息,参见 第12.9.4,“全文构建” 财产 价值 命令行格式 --innodb-ft-sort-pll-degree=#系统变量 innodb_ft_sort_pll_degree范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 2最小值 1最大值 32在一个并行索引和标记文本使用的线程数 InnoDB全文 当建立一个索引 搜索指数 财产 价值 命令行格式 --innodb-ft-total-cache-size=#系统变量 innodb_ft_total_cache_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 640000000最小值 32000000最大值 1600000000总内存分配,以字节为单位的 InnoDB所有表的全文检索索引缓存。创造了无数的表格,每一个 全文 搜索索引,可以使用可用内存的重要部分。 innodb_ft_total_cache_size对所有全文检索索引可以避免过度的内存消耗全球内存限制。如果全球的极限是由索引操作达到强制同步触发。 有关更多信息,参见 InnoDB全文索引缓存 财产 价值 命令行格式 --innodb-ft-user-stopword-table=db_name/table_name系统变量 innodb_ft_user_stopword_table范围 全球会议 动态 是 set_var 提示应用 否 类型 字符串 默认值 NULL此选项用于指定您自己的 InnoDB全文 在一个特定的表的索引词列表。配置你自己的停用词列表的所有 InnoDB表格的使用 innodb_ft_server_stopword_table配置 innodb_ft_user_stopword_table包含列表的停用词的表的名称,在格式 db_name/ table_name停用词表必须在配置存在 innodb_ft_user_stopword_tableinnodb_ft_enable_stopword 必须启用 innodb_ft_user_stopword_table必须配置在你创造的 全文 指数 停用词表必须 InnoDB表,包含一个 varchar 命名列 value有关更多信息,参见 第12.9.4,“全文构建” 财产 价值 命令行格式 --innodb-io-capacity=#系统变量 innodb_io_capacity范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 200最小值 100最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1这个 innodb_io_capacity参数设置一个上限的I/O操作次数,每秒钟完成的 InnoDB 后台任务,例如 冲洗 的页面 缓冲池 合并数据从 变化的缓冲 这个 innodb_io_capacity极限是所有缓冲池的情况下,总的限制。当脏页刷新,极限分缓冲池实例之间。 innodb_io_capacity应设置为I/O操作次数,系统每秒可以执行。理想情况下,保持设定的低的现实,但不能太低,背景活动落后。如果该值太高,数据从缓冲池和插入缓冲太快缓存提供显着的好处。 默认值是200。对于忙碌的能力较高的I/O速率的系统中,你可以设置一个更高的价值,帮助服务器处理高行的变化率相关的后台维护工作。 在一般情况下,你可以增加价值的驱动器用于数函数 InnoDBI/O。例如,你可以增加系统使用多个磁盘或固态硬盘(SSD)的价值。 默认设置200一般是足够的下端SSD。一个更高的目标,总线连接的SSD,考虑如1000更高的设置,例如。对于个别5400转或7200转硬盘系统,你可能会降低价值 100据估计,这代表比例的I/O操作每秒(IOPS)提供给老一代的磁盘驱动器,可以执行约100 IOPS。 虽然你可以指定一个很高的值如一百万,实践上这种大的价值已经几乎没有任何好处。一般而言,20000或更高的值是不推荐,除非你已经证明你的工作量不足的较低值。 考虑写负载时调整 innodb_io_capacity。大系统的写入工作负载可能会从一个更高的环境效益。较低的设置可能是足够的一个小的写入负载系统。 你可以设置 innodb_io_capacity任意数的100或最大的大 innodb_io_capacity_maxinnodb_io_capacity 可以设置在MySQL选项文件( my.cnf或 my.ini )或动态改变使用 SET GLOBAL声明,这就要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权 这个 innodb_flush_sync配置选择原因 innodb_io_capacity设置要爆发的I/O活动发生在关卡中忽略。 innodb_flush_sync默认情况下启用 看到 第15.6.8,“配置InnoDB主线程I/O率” 更多信息。关于一般信息 InnoDBI/O性能,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-io-capacity-max=#系统变量 innodb_io_capacity_max范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 see description最小值 100最大值 (Windows 64位平台) 2**32-1最大值 (UNIX,64-bit平台) 2**64-1最大值 (32位平台) 2**32-1如果冲洗活动落后, InnoDB能冲洗比施加的限制更积极 innodb_io_capacityinnodb_io_capacity_max 定义一个上限数量的I/O操作以每秒 InnoDB在这种情况下,后台任务。 这个 innodb_io_capacity_max设置所有缓冲池的情况下,总的限制。 如果你指定一个 innodb_io_capacity设置在启动但不指定值 innodb_io_capacity_max , innodb_io_capacity_max默认的值的两倍 innodb_io_capacity,与一个最小值2000。 当配置 innodb_io_capacity_max,twice the innodb_io_capacity往往是一个很好的起点。默认值2000是用于工作负载,使用固态硬盘(SSD)或多个磁盘驱动器。设定2000是工作量不使用SSD或多个磁盘驱动器可能太高,可以让太多的冲洗。一个常规的磁盘驱动器,200和400之间的设置建议。一个高端、总线连接的SSD,考虑如2500更高的设置。与 innodb_io_capacity设置,使设置低的现实,但不能太低, InnoDB 无法超越的 innodb_io_capacity的限制,如果有必要的话。 考虑写负载时调整 innodb_io_capacity_max。大系统的写入工作负载可以从一个更高的环境效益。较低的设置可能是足够的一个小的写入负载系统。 innodb_io_capacity_max不能设置为一个值低于 innodb_io_capacity价值 设置 innodb_io_capacity_max到 默认 使用 SET声明( SET GLOBAL innodb_io_capacity_max=DEFAULT集) innodb_io_capacity_max两个最大的价值 相关的信息,看 第15.6.3.7,“微调InnoDB缓冲池冲洗” innodb_limit_optimistic_insert_debug财产 价值 命令行格式 --innodb-limit-optimistic-insert-debug=#系统变量 innodb_limit_optimistic_insert_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 2**32-1限制记录数目 B-树 网页0意味着没有强加限制的默认值。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-lock-wait-timeout=#系统变量 innodb_lock_wait_timeout范围 全球会议 动态 是 set_var 提示应用 否 类型 整数 默认值 50最小值 1最大值 1073741824长时间在秒 InnoDB交易 等待 行锁 在放弃之前。默认值是50秒。一个事务试图访问一行,被另一个 InnoDB在大多数事务等待这许多秒之前发出下面的写访问错误的行: 错误1205(hy000):锁等待超时超标;尝试重新启动交易 当锁等待超时,当前语句 回滚 (不是整个交易)。有整个事务回滚,以启动服务器 --innodb_rollback_on_timeout选项参见 第15.20.4,“InnoDB错误处理” 你可能会降低这个值为高度交互的应用程序或 OLTP 系统,快速显示用户的反馈或将更新为队列处理后。你可以增加这个值对于长期运行的后台操作,如变换步骤在数据仓库等其他大的插入或更新操作完成。 innodb_lock_wait_timeout适用于 InnoDB 行锁。MySQL 表锁 不发生在 InnoDB这个暂停不适用于等待表锁。 锁等待超时值不适用于 死锁 什么时候 innodb_deadlock_detect启用(默认)因为 InnoDB 检测到死锁立即回滚一个僵持不下的交易。什么时候 innodb_deadlock_detect被禁用, InnoDB 依靠 innodb_lock_wait_timeout当事务回滚死锁发生。看到 第15.5.5.2,“死锁检测和回滚” innodb_lock_wait_timeout可以在运行时设置的 设置全局 或 SET SESSION声明。改变 全球 设置要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权和影响所有的客户,随后连接操作。任何客户端都可以改变 SESSION设置 innodb_lock_wait_timeout,这只影响客户端 财产 价值 命令行格式 --innodb-log-buffer-size=#系统变量 (>= 8.0.11)innodb_log_buffer_size系统变量 (<= 8.0.4)innodb_log_buffer_size范围 (>= 8.0.11)全球 范围 (<= 8.0.4)全球 动态 (>= 8.0.11)是 动态 (<= 8.0.4)否 set_var 提示应用 (>= 8.0.11)否 set_var 提示应用 (<= 8.0.4)否 类型 整数 默认值 16777216最小值 1048576最大值 4294967295大小的缓冲区字节 InnoDB用写的 日志文件 在磁盘。默认为16MB。一个大的 日志缓冲区 使大 交易 运行而不需要在事务日志写入磁盘 犯罪 。因此,如果你有交易,更新、插入或删除行,很多,使得日志缓冲区更大的节省了磁盘I/O相关的信息,看 InnoDB内存配置 ,和 8.5.4节,“优化InnoDB重做日志” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-log-checksums=#系统变量 innodb_log_checksums范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON启用或禁用和重做日志页。 innodb_log_checksums=ON使 crc-32c 校验算法重做日志页。什么时候 innodb_log_checksums是残疾人,重做日志的页面校验和字段的内容被忽略。 在重做日志标题页和重做日志检查点页面没有禁用校验。 财产 价值 命令行格式 --innodb-log-compressed-pages=#系统变量 innodb_log_compressed_pages范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON特异影像 再compressed 网页 写入 重做日志文件 。重新压缩时可能发生的变化对压缩后的数据。 innodb_log_compressed_pages默认情况下启用防止腐败可能发生的,如果一个不同版本的 zlib 压缩算法应用在恢复。如果你是肯定的 zlib版本将不会改变,你可以禁用 _ _ pages _ InnoDB日志压缩 为了减少工作量,修改压缩数据重做日志生成。 测量启用或禁用的影响 innodb_log_compressed_pages重做日志,比较代都设置同样的工作量下。选择测量重做日志生成包括观察 日志序列号 (lsn)在 LOG段 SHOW ENGINE INNODB STATUS输出,或监测 Innodb_os_log_written对于写入重做日志文件的字节数状态。 相关的信息,看 第15.9.1.6,“压缩的OLTP工作负载” 财产 价值 命令行格式 --innodb-log-file-size=#系统变量 innodb_log_file_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 50331648最小值 4194304最大值 512GB / innodb_log_files_in_group在每个字节的大小 日志文件 在一个 日志组 。日志文件的大小( innodb_log_file_size* innodb_log_files_in_group)不能超过一个,略小于最大值512gb。例如一对255 GB的日志文件,方法的限制,但不超过。默认值是48mb。 一般来说,对日志文件的大小应足够大,使服务器能够顺利的高峰和低谷负荷的活动,这通常意味着有足够的日志空间来处理一个多小时写作业。这个值越大,越检查点刷新活动在缓冲池的要求,节省磁盘I / O的日志文件也会更大 崩溃恢复 慢,虽然在MySQL 5.5和更高的回收性能使日志文件大小不一的考虑改进。 最小 innodb_log_file_size为4MB 相关的信息,看 InnoDB日志文件配置 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 如果 innodb_dedicated_server启用的 innodb_log_file_size值是自动配置如果它没有明确的定义。有关更多信息,参见 第15.6.13,“启用自动配置一个专用的MySQL服务器” 财产 价值 命令行格式 --innodb-log-files-in-group=#系统变量 innodb_log_files_in_group范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 2最小值 2最大值 100数 日志文件 在 日志组 InnoDB写在一个圆形的方式的文件。默认值是2(推荐)。该文件的位置指定 innodb_log_group_home_dir。日志文件的大小( innodb_log_file_size* innodb_log_files_in_group )可高达512GB 相关的信息,看 InnoDB日志文件配置 财产 价值 命令行格式 --innodb-log-group-home-dir=dir_name系统变量 innodb_log_group_home_dir范围 全球 动态 否 set_var 提示应用 否 类型 目录名称 的目录路径 InnoDB重做日志文件 文件,其数量是指定的 innodb_log_files_in_group。如果你不指定任何 InnoDB 日志的变量,默认是创建两个文件命名 ib_logfile0和 ib_logfile1 在MySQL数据目录。日志文件的大小是由 innodb_log_file_size系统变量 相关的信息,看 InnoDB日志文件配置 财产 价值 命令行格式 --innodb-log-spin-cpu-abs-lwm=#介绍 8.0.11 系统变量 innodb_log_spin_cpu_abs_lwm范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 80最小值 0最大值 4294967295定义了最小的CPU使用率低于该用户线程不再自旋等待刷新重做。该值表示为和CPU核心的使用。例如,80的默认值是80%的单CPU核心。在一个多核处理器系统,值为150表示一个CPU核心加上第二CPU核心50 % 100 %用途使用。 相关的信息,看 8.5.4节,“优化InnoDB重做日志” 财产 价值 命令行格式 --innodb-log-spin-cpu-pct-hwm=#介绍 8.0.11 系统变量 innodb_log_spin_cpu_pct_hwm范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 50最小值 0最大值 100定义了最大数量的CPU使用率,用户线程不再自旋等待刷新重做。该值表示为所有CPU核心处理能力的百分比总和。默认值是50%。例如,100%使用两个CPU核是50%的组合的CPU处理能力的服务器上有四个CPU核心。 这个 innodb_log_spin_cpu_pct_hwm配置选项方面处理器亲和。例如,如果一个服务器有48个内核,但 mysqld 过程是在只有四个CPU核心,其他44个CPU核心被忽略。 相关的信息,看 8.5.4节,“优化InnoDB重做日志” innodb_log_wait_for_flush_spin_hwm财产 价值 命令行格式 --innodb-log-wait-for-flush-spin-hwm=#介绍 8.0.11 系统变量 innodb_log_wait_for_flush_spin_hwm范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 400最小值 0最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1定义最大平均日志刷新时间超过该用户线程不再自旋等待刷新重做。默认值为400微秒。 相关的信息,看 8.5.4节,“优化InnoDB重做日志” 财产 价值 命令行格式 --innodb-log-write-ahead-size=#系统变量 innodb_log_write_ahead_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 8192最小值 512 (log file block size)最大值 Equal to innodb_page_size定义先写块大小的重做日志,在字节。为了避免 “ 读写 “ ,集 innodb_log_write_ahead_size匹配的操作系统或文件系统缓存块大小。默认设置是8192个字节。读写时,重做日志块不完全缓存的操作系统或文件系统由于不匹配之间提前写块大小为重做日志和操作系统或文件系统缓存块大小。 有效值为 innodb_log_write_ahead_size是的倍数 InnoDB 日志文件的块大小(2 N )。最小值是 InnoDB日志文件的块大小(512)。向前写时不会出现最小值是指定的。最大值是相等的 innodb_page_size价值。如果你指定一个值 innodb_log_write_ahead_size是大于 innodb_page_size的价值, innodb_log_write_ahead_size 设置截断的 innodb_page_size价值 设置 innodb_log_write_ahead_size太低的值与操作系统或文件系统的高速缓存块大小的结果 “ 读写 “ 。设置的值太高,可能会有轻微的影响 fsync对日志文件的写入性能由于被写在一块。 相关的信息,看 8.5.4节,“优化InnoDB重做日志” 财产 价值 命令行格式 --innodb-lru-scan-depth=#系统变量 innodb_lru_scan_depth范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 1024最小值 100最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1影响算法和启发式算法的参数 脸红 操作的 InnoDB缓冲池 。主要感兴趣的I/O密集型工作负载的性能专家整定。它规定,每个缓冲池的实例,多远了缓冲池的LRU页面列表页面清洁螺纹扫描寻找 脏页 冲洗。这是一个进行一次后台操作。 设置小于默认的通常是最适合的工作。的值是比需要更高性能的可能影响。只考虑增加价值,如果你有多余的I/O能力的典型工作负荷下。相反,如果一个写密集型工作量饱和你的I/O能力,减少的价值,特别是在一个大的缓冲池的情况。 当调整 innodb_lru_scan_depth,从一个低值和配置设置上很少看到的零页的目标。同时,考虑调整 innodb_lru_scan_depth 改变缓冲池的实例的数量时,自 innodb_lru_scan_depth* innodb_buffer_pool_instances定义由页面清洁螺纹每秒钟执行的工作量。 相关的信息,看 第15.6.3.7,“微调InnoDB缓冲池冲洗” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-max-dirty-pages-pct=#系统变量 innodb_max_dirty_pages_pct范围 全球 动态 是 set_var 提示应用 否 类型 数字 默认值 (>= 8.0.3)90默认值 (<= 8.0.2)75最小值 0最大值 99.99这个 innodb_max_dirty_pages_pct设置了冲洗活动目标。它不影响刷新率。有关管理冲洗率信息,看 第15.6.3.6,“配置InnoDB缓冲池冲洗” 相关的信息,看 第15.6.3.7,“微调InnoDB缓冲池冲洗” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” innodb_max_dirty_pages_pct_lwm财产 价值 命令行格式 --innodb-max-dirty-pages-pct-lwm=#系统变量 innodb_max_dirty_pages_pct_lwm范围 全球 动态 是 set_var 提示应用 否 类型 数字 默认值 (>= 8.0.3)10默认值 (<= 8.0.2)0最小值 0最大值 99.99定义一个代表比例的低水位 脏页 在这preflushing能够控制脏页率。值0禁用预冲洗行为完全。有关更多信息,参见 第15.6.3.7,“微调InnoDB缓冲池冲洗” 财产 价值 命令行格式 --innodb-max-purge-lag=#系统变量 innodb_max_purge_lag范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 4294967295定义清除队列的最大长度。默认值为0表示没有限制(无延迟)。 使用此选项将延迟 INSERT, UPDATE,和 DELETE操作时 净化 操作滞后(见 15.3节,“InnoDB的多版本” ) 这个 InnoDB交易系统维护一个列表,有删除标记的记录交易指数 UPDATE或 DELETE业务。the length of the list represents the purge_lag价值。什么时候 purge_lag超过 innodb_max_purge_lag, INSERT, UPDATE,和 DELETE操作被延迟 为了防止过多的延迟,在极端的情况下, purge_lag庞大,您可以限制延迟设置 innodb_max_purge_lag_delay配置选项。延迟计算在清洗批开始。 一个典型的设置问题的工作量可能是100万,假设交易是小,大小只有100个字节,它允许有100MB的unpurged InnoDB表中的行 滞后值显示在历史记录列表的长度 TRANSACTIONS段 InnoDB监视器输出 。This is the example滞后值输出:20 ------------ TRANSACTIONS ------------ Trx id counter 0 290328385 Purge done for trx's n:o < 0 290315608 undo n:o < 0 17 History list length 20
通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-max-purge-lag-delay=#系统变量 innodb_max_purge_lag_delay范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0指定由延时微秒的最大延迟 innodb_max_purge_lag配置选项。一个非零的值表示从基于价值的公式计算延迟时间的上限 innodb_max_purge_lag。零意味着默认是没有上限的延迟间隔施加。 通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-max-undo-log-size=#系统变量 innodb_max_undo_log_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 1073741824最小值 10485760最大值 2**64-1定义一个阈值大小的撤销表空间。如果一个undo表空间超过阈值,它可以被标记为截断时 innodb_undo_log_truncate启用。默认值是1073741824字节(1024 MIB)。 innodb_merge_threshold_set_all_debug财产 价值 命令行格式 --innodb-merge-threshold-set-all-debug=#系统变量 innodb_merge_threshold_set_all_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 50最小值 1最大值 50定义一个页面百分点值覆盖当前索引页 MERGE_THRESHOLD所有的指标,目前在数据字典缓存设置。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选择。Related information,see 第15.6.12,“配置合并阈值的索引页” 财产 价值 命令行格式 --innodb-monitor-disable=[counter|module|pattern|all]系统变量 innodb_monitor_disable范围 全球 动态 是 set_var 提示应用 否 类型 字符串 禁用 InnoDB度量计数器 。计数器数据可查询使用 INFORMATION_SCHEMA.INNODB_METRICS表使用的信息,参见 第15.14.6,“InnoDB information_schema度量表” innodb_monitor_disable='latch'禁用数据收集 SHOW ENGINE INNODB MUTEX。有关更多信息,参见 第13.7.6.15,“显示引擎语法” 财产 价值 命令行格式 --innodb-monitor-enable=[counter|module|pattern|all]系统变量 innodb_monitor_enable范围 全球 动态 是 set_var 提示应用 否 类型 字符串 使能够 InnoDB度量计数器 。计数器数据可查询使用 INFORMATION_SCHEMA.INNODB_METRICS表使用的信息,参见 第15.14.6,“InnoDB information_schema度量表” innodb_monitor_enable='latch'启用统计信息收集 SHOW ENGINE INNODB MUTEX。有关更多信息,参见 第13.7.6.15,“显示引擎语法” 财产 价值 命令行格式 --innodb-monitor-reset=[counter|module|pattern|all]系统变量 innodb_monitor_reset范围 全球 动态 是 set_var 提示应用 否 类型 字符串 重置计数值 InnoDB度量计数器 零。计数器数据可查询使用 INFORMATION_SCHEMA.INNODB_METRICS表使用的信息,参见 第15.14.6,“InnoDB information_schema度量表” innodb_monitor_reset='latch'重置统计报告 SHOW ENGINE INNODB MUTEX。有关更多信息,参见 第13.7.6.15,“显示引擎语法” 财产 价值 命令行格式 --innodb-monitor-reset-all=[counter|module|pattern|all]系统变量 innodb_monitor_reset_all范围 全球 动态 是 set_var 提示应用 否 类型 字符串 重置所有值(最小,最大,等等)为 InnoDB度量计数器 。计数器数据可查询使用 INFORMATION_SCHEMA.INNODB_METRICS表使用的信息,参见 第15.14.6,“InnoDB information_schema度量表” 财产 价值 命令行格式 --innodb-numa-interleave=#系统变量 innodb_numa_interleave范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF使用NUMA交织分配内存的政策 InnoDB缓冲池。什么时候 innodb_numa_interleave 启用NUMA内存策略设置为 MPOL_INTERLEAVE对于 mysqld 过程。后 InnoDB缓冲池分配,NUMA内存策略设置回 mpol_default 。对于 innodb_numa_interleave选项可用,MySQL必须启用NUMA编译Linux系统。 CMake 设置默认 WITH_NUMA基于当前平台的价值 NUMA 支持有关更多信息,参见 2.8.4”部分,MySQL源配置选项” 财产 价值 命令行格式 --innodb-old-blocks-pct=#系统变量 innodb_old_blocks_pct范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 37最小值 5最大值 95指定的近似百分比 InnoDB缓冲池 使用旧的块 子列表 。值的范围是5到95。默认值是37(即3/8的池)。经常结合使用 innodb_old_blocks_time有关更多信息,参见 第15.6.3.4,“缓冲池扫描耐” 。对缓冲池的管理信息, LRU 算法,并 驱逐 政策,看 第15.6.3.1,“InnoDB缓冲池” 财产 价值 命令行格式 --innodb-old-blocks-time=#系统变量 innodb_old_blocks_time范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 1000最小值 0最大值 2**32-1非零的值,防止 缓冲池 被那仅仅是一个短暂的时期引用的数据填充,如在 全表扫描 。增加这个值提供了对全表扫描干扰保护缓存中的数据缓冲池。 指定以毫秒为单位的块插入老多久 子列表 要移动到新的子表的首次访问后留在那里。如果该值为0,一块插入老子马上行动的新的子表的首次访问,无论多么快的访问发生后插入。如果该值大于0,块仍然在旧的子列表直到访问至少发生多少毫秒后首次访问。例如,一个价值1000块的原因在旧子表1秒才成为合格的移动到新的子列表的第一个访问后。 默认值是1000 此配置选项往往是结合使用 innodb_old_blocks_pct。有关更多信息,参见 第15.6.3.4,“缓冲池扫描耐” 。对缓冲池的管理信息, LRU 算法,并 驱逐 政策,看 第15.6.3.1,“InnoDB缓冲池” innodb_online_alter_log_max_size财产 价值 命令行格式 --innodb-online-alter-log-max-size=#系统变量 innodb_online_alter_log_max_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 134217728最小值 65536最大值 2**64-1指定过程中使用的临时日志文件的字节大小的上限 在线DDL 操作 InnoDB表有一个正在创建或改变各指标如表日志文件。此日志文件存储数据的插入、更新或删除表中的DDL操作期间。临时日志文件扩展时所需要的价值 innodb_sort_buffer_size,到指定的最大值 innodb_online_alter_log_max_size 。如果一个临时日志文件超过大小上限,这 ALTER TABLE操作失败,所有未提交的并发DML操作回滚。因此,一个大值这个选项允许更多的DML到在线DDL操作期间发生的,而且延长时间在DDL操作结束时,表被应用的数据从日志。 财产 价值 命令行格式 --innodb-open-files=#系统变量 innodb_open_files范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 -1(意味着调整;不转让本文字值) 最小值 10最大值 4294967295如果您使用多个配置选项是唯一相关的 InnoDB表空间 。。。。。。。它specifies的最大数 .ibd文件 MySQL可以一次保持开放。最小值是10。默认值是300如果 innodb_file_per_table未启用,和高300 table_open_cache否则 descriptors used for the file .ibd文件是 InnoDB 表。他们是独立于指定的 --open-files-limit服务器的选择,而不影响表的缓存操作。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-optimize-fulltext-only=#系统变量 innodb_optimize_fulltext_only范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF改变的方式 OPTIMIZE TABLE操作上 InnoDB 表为了使暂时在维护作业 InnoDB表 全文 指标 默认情况下, OPTIMIZE TABLE在reorganizes日期 聚集索引 该表。当启用此选项, OPTIMIZE TABLE跳表数据的重组过程,而新增,删除和更新数据,令牌 InnoDB FULLTEXT指标。有关更多信息,参见 InnoDB全文索引优化 财产 价值 命令行格式 --innodb-page-cleaners=#系统变量 innodb_page_cleaners范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 4最小值 1最大值 64那冲洗脏页从缓冲池的页面清洁的线程数。页面清洁螺纹进行冲洗和LRU刷新列表。当有多个线程缓冲池页面清洁,冲洗的任务,每个缓冲池的实例被派遣到空闲页面清洁螺纹。这个 innodb_page_cleaners默认值是4。如果一些页面清洁螺纹超过缓冲池的实例数, innodb_page_cleaners 自动设置为相同的值 innodb_buffer_pool_instances如果你的工作量是写IO绑定冲洗时从缓冲池的实例数据文件的脏页,如果您的系统硬件的可用容量,增加页面清洁螺纹可能有助于提高写IO吞吐量。 多线程网页吸尘器支持延伸到关闭和恢复阶段。 这个 setpriority()系统调用是使用Linux平台,它的支持,并在 mysqld 执行用户授权给 page_cleaner线程的优先级比其他MySQL InnoDB 线程的帮助页面冲洗与当前工作量保持同步。 setpriority()支持所显示的是这个 InnoDB 启动信息: [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().
对系统的启动和关闭服务器不是由系统, mysqld 执行用户授权可以配置 /etc/security/limits.conf。例如,如果 mysqld 是运行在 mysql用户可以授权 MySQL 通过增加这些线路的用户 /etc/security/limits.conf: MySQL硬好看的20mysql软好- 20 对于系统的管理系统,同样可以实现通过指定 LimitNICE=-20在一个局部的系统配置文件。例如,创建一个文件名为 override.conf 进入 /etc/systemd/system/mysqld.service.d/override.conf并将该条目: [Service]LimitNICE=-20
在创建或更改 override.conf,重装系统的配置,然后告诉系统重启mysql服务: systemctl守护reloadsystemctl重启mysqld #转platformssystemctl重启mysql # Debian平台 有关使用本地化的系统配置文件的更多信息,参见 MySQL的配置系统 经过授权的 mysqld 执行用户,使用 猫 命令来验证配置 Nice限制的 mysqld 过程: shell> cat /proc/
mysqld_pid/limits | grep nice Max nice priority 18446744073709551596 18446744073709551596财产 价值 命令行格式 --innodb-page-size=#k系统变量 innodb_page_size范围 全球 动态 否 set_var 提示应用 否 类型 枚举 默认值 16384有效值 4k8k16k32k64k40968192163843276865536指定 页面大小 所有 InnoDB表空间 在MySQL 实例 。你可以使用价值64k指定页面大小,32k, 16k(The default), 8K ,或 4k。或者,您可以指定页面大小(字节检测,再16384,2000,4096)。 innodb_page_size只能配置之前初始化MySQL实例并不能改变之后。如果没有指定任何值,实例是使用默认的页大小初始化。看到 第15.6.1,“InnoDB启动配置” 既为32K和64K的页面大小,最大的行长度大约是16000个字节。 ROW_FORMAT=COMPRESSED时不支持 innodb_page_size 设置32KB或64Kb。为 innodb_page_size=32k,大小为2MB。为 innodb_page_size=64k,大小为4MB innodb_log_buffer_size应设置至少16m(默认值)时,使用32K或64K的页面大小。 默认16kb页面大小或更大的适用范围广 工作负载 ,特别是涉及到的表扫描和DML操作涉及批量更新查询。较小的页大小可能更有效 OLTP 包括许多小的写入负载,可以在竞争的问题时,单页包含多行。较小的页面也可能是有效的 SSD 存储设备,通常使用小的块尺寸。保持 InnoDB页面大小接近存储设备的块大小不变,减少数据改写磁盘。 对于第一个系统表空间数据文件的最小文件大小( ibdata1)根据不同的 innodb_page_sizeValue。See the innodb_data_file_path选项描述的更多信息 通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-print-all-deadlocks=#系统变量 innodb_print_all_deadlocks范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF启用此选项时,所有的信息 死锁 进入 InnoDB用户的交易记录在 mysqld 错误日志 。否则,你看到的只有最后的死锁信息,使用 SHOW ENGINE INNODB STATUS命令。一个偶然的 InnoDB 僵局不一定是一个问题,因为 InnoDB检测条件立即回滚一个事务自动。你可以使用此选项来解决死锁的发生是为什么如果一个应用程序没有适当的错误处理逻辑检测回滚并重试操作。大量的死锁可能表明需要重组交易问题 DML 或 SELECT ... FOR UPDATE多表报表,使每一个事务访问表中的相同的顺序,从而避免死锁的条件。 相关的信息,看 第15.5.5,“会”Deadlocks 财产 价值 命令行格式 --innodb-print-ddl-logs=#介绍 8.0.3 系统变量 innodb_print_ddl_logs范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF启用此选项使MySQL写DDL日志 stderr。有关更多信息,参见 查看DDL日志 财产 价值 命令行格式 --innodb-purge-batch-size=#系统变量 innodb_purge_batch_size范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 300最小值 1最大值 5000定义了一些撤消清除日志页面解析和处理一批从 历史记录列表 。在一个多线程的清除配置,协调清除线程分 innodb_purge_batch_size由 innodb_purge_threads然后将该页面的数量每个清洗线。这个 innodb_purge_batch_size 期权也定义了一些UNDO日志页面,清除释放后每128次迭代通过UNDO日志。 这个 innodb_purge_batch_size选项用于先进的性能优化结合 innodb_purge_threads设置大多数的MySQL用户不需要改变 innodb_purge_batch_size 其默认值 相关的信息,看 第15.6.10,“配置InnoDB净化调度” 财产 价值 命令行格式 --innodb-purge-threads=#系统变量 innodb_purge_threads范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 4最小值 1最大值 32后台线程用于数 InnoDB净化 运营最小值1意味着清洗操作通常是由一个后台线程执行,永远的一部分 主线程 。在一个或多个后台线程有助于减少内部竞争在运行清除操作 InnoDB,提高可扩展性。增加值大于1,创造了许多单独的清洗线,可以提高效率的系统 DML 对多个表进行操作。最大的是32。 相关的信息,看 第15.6.10,“配置InnoDB净化调度” innodb_purge_rseg_truncate_frequency财产 价值 命令行格式 --innodb-purge-rseg-truncate-frequency=#系统变量 innodb_purge_rseg_truncate_frequency范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 128最小值 1最大值 128定义了频率与吹扫系统释放回滚段中的次数,清洗时。UNDO表空间不能被截断,直到它的回滚段被释放。通常情况下,吹扫系统释放回滚段每128次清洗时。默认值为128。减少该值增加的频率,清除线程释放回滚段。 innodb_purge_rseg_truncate_frequency目的是为使用 innodb_undo_log_truncate。有关更多信息,参见 第15.7.9,“Truncating Undo Tablespaces” 财产 价值 命令行格式 --innodb-random-read-ahead=#系统变量 innodb_random_read_ahead范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF使随机 读前 技术优化 InnoDB我/ O. 为详细了解性能考虑不同类型提前读请求,看 第15.6.3.5”配置,InnoDB缓冲池预取(预读)” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-read-ahead-threshold=#系统变量 innodb_read_ahead_threshold范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 56最小值 0最大值 64控制灵敏度线性 读前 那个 InnoDB使用预取页面进入 缓冲池 。如果 InnoDB至少读取 innodb_read_ahead_threshold 页面顺序从 程度 (64页),引发了整个异步读以下程度。值的允许范围是0到64。值0禁用预读。对于56的默认值, InnoDB必须至少读56页的程度依次为下列范围初始化一个异步读。 知道有多少页面浏览预读机制,如何对这些页面会被从缓冲池没有被访问,可能是有用的当微调 innodb_read_ahead_threshold设置 SHOW ENGINE INNODB STATUS输出显示计数器信息从 Innodb_buffer_pool_read_ahead和 Innodb_buffer_pool_read_ahead_evicted全局状态变量,该报告纳入页数 缓冲池 通过提前读请求,和这样的页面数 驱逐 从缓冲池没有被访问,分别。状态变量的全球价值报告自上次重新启动服务器。 SHOW ENGINE INNODB STATUS也显示了速度,预读页面读取和速率,这样的页面会被没有被访问。每秒平均值是基于自上次调用的统计 显示引擎INNODB STATUS 并显示在 BUFFER POOL AND MEMORY部分的 SHOW ENGINE INNODB STATUS输出 有关更多信息,参见 第15.6.3.5”配置,InnoDB缓冲池预取(预读)” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 财产 价值 命令行格式 --innodb-read-io-threads=#系统变量 innodb_read_io_threads范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 4最小值 1最大值 64数字I/O读操作的线程 InnoDB。其对应的写线程 innodb_write_io_threads。有关更多信息,参见 第15.6.6,“配置一些背景InnoDB I/O线程” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 笔记 在Linux系统上,运行多个MySQL服务器(通常超过12)的默认设置 innodb_read_io_threads, innodb_write_io_threads,和Linux AIO的最大NR 设置可以超过系统限制。理想的情况下,增加 aio-max-nr设置;作为一种替代方法,可以减少一个或两个MySQL的配置选项的设置。 财产 价值 命令行格式 --innodb-read-only=#系统变量 innodb_read_only范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF开始 InnoDB在只读模式。分布式数据库应用程序或只读媒体数据集。也可以使用数据仓库中的多个实例之间共享相同的数据目录。有关更多信息,参见 第15.6.2,“配置InnoDB只读操作” 此前,使 innodb_read_only系统变量不能创建和删除表只为 InnoDB 存储引擎。在MySQL 5.0,使 innodb_read_only防止这些操作对所有的存储引擎。表的创建和删除操作的任何存储引擎修改数据字典表 MySQL 系统的数据库,但这些表的使用 InnoDB存储引擎不能修改时 innodb_read_only启用。同样的原则也适用于其他表的操作,需要修改数据字典表。实例: 如果 innodb_read_only系统变量是启用, ANALYZE TABLE可能会失败,因为它不能在数据字典更新统计表,并使用 InnoDB 。为 ANALYZE TABLE操作更新密钥分配,即使操作更新表本身可能出现故障(例如,如果它是一个 MyISAM 表)。为了获得更新的统计分布,集 information_schema_stats_expiry=0ALTER TABLEtbl_nameENGINE=engine_name不能因为它更新存储引擎的设计,这是存储在数据字典。
此外,在其他表 mysql系统数据库使用 InnoDB 在MySQL 8的存储引擎。这些表的读操作,修改限制只有结果。实例: 账户管理报表等 CREATE USER和 GRANT失败是因为授权表的使用 InnoDB 这个 INSTALL PLUGIN和 UNINSTALL PLUGIN插件管理语句失败是因为 插件 表使用 InnoDB这个 CREATE FUNCTION和 DROP FUNCTIONUDF管理语句失败是因为 功能 表使用 InnoDB
财产 价值 命令行格式 --innodb-redo-log-encrypt=#介绍 8.0.1 系统变量 innodb_redo_log_encrypt范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF控制加密的重做日志数据表使用加密 InnoDB表空间加密功能 。加密的重做日志数据默认是禁用的。有关更多信息,参见 重做日志数据加密 财产 价值 命令行格式 --innodb-replication-delay=#系统变量 innodb_replication_delay范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 4294967295复制线程延迟毫秒在从服务器,如果 innodb_thread_concurrency达到 财产 价值 命令行格式 --innodb-rollback-on-timeout系统变量 innodb_rollback_on_timeout范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFFInnoDB回滚 在默认情况下,事务超时的最后声明。如果 --innodb_rollback_on_timeout指定事务超时的原因 InnoDB 中止并回滚整个事务 笔记 如果开始交易声明 START TRANSACTION或 BEGIN语句回滚不取消声明。进一步的SQL语句成为交易的一部分,直到发生 COMMIT, ROLLBACK,或一些SQL语句引起的隐式提交。 有关更多信息,参见 第15.20.4,“InnoDB错误处理” 财产 价值 命令行格式 --innodb-rollback-segments=#系统变量 innodb_rollback_segments范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 128最小值 1最大值 128innodb_rollback_segments定义了一些 回滚段 分配给临时表空间每个undo表空间。每个回滚段可以支持最多1023个数据修改事务。 对回滚段的更多信息,参见 15.3节,“InnoDB的多版本” 。关于撤销表空间,看 第15.7.8”配置,撤销表空间” 财产 价值 命令行格式 --innodb-scan-directories=#介绍 8.0.2 系统变量 innodb_scan_directories范围 全球 动态 否 set_var 提示应用 否 类型 字符串 默认值 NULL如果,在恢复, InnoDB遇到重做日志从上一个检查点的日志写的,必须应用到受影响的表空间。识别受影响的表空间的过程称为表空间的发现。表空间的发现取决于表空间地图文件,地图表空间ID在重做日志表空间文件。如果表空间地图文件丢失或损坏,该 innodb_scan_directories 启动选项可以用来指定表空间文件目录。此选项 InnoDB仔细阅读每个表空间文件的第一页中指定的目录并重新创建表空间地图文件,恢复过程可以应用重做日志到受影响的表空间。 innodb_scan_directories可以指定在启动命令或在MySQL选项文件选项。行情是在参数值用否则分号(;)是由一些命令解释器解释为一个特殊的字符。(UNIX shell作为命令终止符,例如。) 启动命令: mysqld --innodb-scan-directories="
directory_path_1;directory_path_2"MySQL选项文件: [mysqld] innodb_scan_directories="
directory_path_1;directory_path_2"有关更多信息,参见 丢失或损坏的文件表空间地图 innodb_saved_page_number_debug财产 价值 命令行格式 --innodb-saved-page-number-debug=#系统变量 innodb_saved_page_number_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最大值 2**23-1节省一个页码。设置 innodb_fil_make_page_dirty_debug选择垢定义的页面 innodb_saved_page_number_debug 。这个 innodb_saved_page_number_debug选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-sort-buffer-size=#系统变量 innodb_sort_buffer_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 1048576最小值 65536最大值 67108864指定排序缓冲区用来排序的数据建立一个在大小 InnoDB指数指定的大小定义,读入内存内部排序,然后写入磁盘的数据量。这个过程被称为 “ 运行 “ 。在合并阶段,对指定大小的缓冲区对阅读和合并。较大的设置、运行及合并有少。 这类地区仅用于合并排序在索引创建过程中,在以后的索引维护操作。缓冲区释放索引创建完成时。 此选项的值也控制量由临时日志文件记录并行DML延长期间 在线DDL 运营 在这之前的设置进行配置,大小为1048576字节的硬编码(1MB),这是默认的。 在一个 ALTER TABLE或 CREATE TABLE语句创建一个索引,三缓冲区分配的,每一个尺寸定义的这个选项。此外,辅助指针分配在排序缓冲区行指针使排序可以运行(与排序操作时移动行)。 对于一个典型的排序操作,如这一公式可以用来估算内存的消耗: (6 /*FTS_NUM_AUX_INDEX*/ * (3*@@global.innodb_sort_buffer_size) + 2 * number_of_partitions * number_of_secondary_indexes_created * (@@global.innodb_sort_buffer_size/dict_index_get_min_size(index)*/) * 8 /*64-bit sizeof *buf->tuples*/")
@@global.innodb_sort_buffer_size/dict_index_get_min_size(index)显示最大的图标 2 *(@ @全球。innodb_sort_buffer_size / * dict_index_get_min_size(指数)* /)* 8 / * 64位尺寸* buf ->元组* / 表明辅助指针分配 笔记 32位,乘以4而不是8。 并行在一个全文索引,乘 innodb_ft_sort_pll_degree设置 (6 / * FTS Proceed.Num Num Course on the Effect Index * / * @ @ @ @ @ @ @ @ @ @ @ @ 财产 价值 命令行格式 --innodb-spin-wait-delay=#系统变量 innodb_spin_wait_delay范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 6最小值 0最大值 (64位平台) 2**64-1最大值 (32位平台) 2**32-1一个民意调查之间的最大延迟 旋转 锁具这一机制的底层实现取决于硬件和操作系统的组合,所以延迟不符合一个固定的时间间隔。有关更多信息,参见 第15.6.9”配置,自旋锁投票” 财产 价值 命令行格式 --innodb-stats-auto-recalc=#系统变量 innodb_stats_auto_recalc范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON起因 InnoDB自动重新计算 持续的统计 在表中的数据发生了实质性的变化。该阈值是表中行的10%.。此设置适用于表时创建的 innodb_stats_persistent选项启用。自动统计计算,也可以通过指定配置 STATS_PERSISTENT=1在一个 CREATE TABLE或 ALTER TABLE声明。采样数据产生统计金额是由 innodb_stats_persistent_sample_pages配置选项 有关更多信息,参见 第15.6.11.1”配置,持续优化统计参数 innodb_stats_include_delete_marked财产 价值 命令行格式 --innodb-stats-include-delete-marked=#介绍 8.0.1 系统变量 innodb_stats_include_delete_marked范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF默认情况下, InnoDB读取未提交的数据在计算统计。在一个事务中删除行从表的情况, InnoDB 排除了删除标记时计算行估计和指数统计记录,从而导致非最优的执行计划的其他交易,操作上同时使用事务隔离级别以外 READ UNCOMMITTED。为了避免这一情况的发生, innodb_stats_include_delete_marked能够确保 InnoDB 包括删除标记的记录计算时持续优化统计。 什么时候 innodb_stats_include_delete_marked启用, ANALYZE TABLE考虑删除标记的记录时,重新计算统计。 innodb_stats_include_delete_marked是一个全球性的设置影响所有 InnoDB 表它只适用于持续优化统计。 相关的信息,看 第15.6.11.1”配置,持续优化统计参数 财产 价值 命令行格式 --innodb-stats-method=name系统变量 innodb_stats_method范围 全球 动态 是 set_var 提示应用 否 类型 枚举 默认值 nulls_equal有效值 nulls_equalnulls_unequalnulls_ignored服务器如何对待 NULL值时收集 统计 对指标值的分布 InnoDB表允许值 nulls_equal , nulls_unequal,和 nulls_ignored 。为 nulls_equal,所有的 无效的 指数值都是相同的,大小等于该数形成一个单值群 NULL价值观。为 nulls_unequal , NULL价值观是不平等的,每个 无效的 形成了一个鲜明的价值大小1组。为 nulls_ignored, 无效的 值将被忽略 用于生成表统计方法如何影响优化器选择查询执行的指标,如 第8.3.8,”InnoDB和MyISAM索引的统计信息收集” 财产 价值 命令行格式 --innodb-stats-on-metadata系统变量 innodb_stats_on_metadata范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF此选项仅适用于当优化器 统计 被配置为非持久性。优化器统计信息不保存到磁盘时 innodb_stats_persistent被禁用或当个人表创建或改变 STATS_PERSISTENT=0。有关更多信息,参见 第15.6.11.2,“配置非持续优化统计参数 什么时候 innodb_stats_on_metadata启用, InnoDB 更新非持久性 统计 当元数据报表等 SHOW TABLE STATUS或当访问 INFORMATION_SCHEMA.TABLES或 INFORMATION_SCHEMA.STATISTICS表(这些更新是类似于什么事情 ANALYZE TABLE当禁用。), InnoDB 不更新统计在这些操作中。离开设置残疾人可以提高,有大量的表或索引架构的访问速度。它也可以提高稳定性 执行计划 查询涉及 InnoDB表 要更改设置,问题的声明 SET GLOBAL innodb_stats_on_metadata=mode,在那里 mode要么是 打开(放) 或 OFF(或 一 或 0)。改变设置要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权和立即影响所有连接的操作。 财产 价值 命令行格式 --innodb-stats-persistent=setting系统变量 innodb_stats_persistent范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON有效值 OFFON01指定是否 InnoDB索引统计信息保存到磁盘。否则,统计数字可能会多次计算导致的变化 执行计划 。这个设置是保存在每个表创建表时。你可以设置 innodb_stats_persistent在全球层面,在创建一个表,或使用 _持久性数据 的条款 CREATE TABLE和 ALTER TABLE语句覆盖系统范围的设置和配置个人持续统计表。 有关更多信息,参见 第15.6.11.1”配置,持续优化统计参数 innodb_stats_persistent_sample_pages财产 价值 命令行格式 --innodb-stats-persistent-sample-pages=#系统变量 innodb_stats_persistent_sample_pages范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 20指标的数量 网页 样本估计 基数 和其他 统计 对于索引列,如计算 ANALYZE TABLE。增加值提高了指标统计的准确性,从而提高 查询执行计划 ,以增加I/O的执行过程 ANALYZE TABLE对于一个 InnoDB 表有关更多信息,参见 第15.6.11.1”配置,持续优化统计参数 笔记 设置较高的值 innodb_stats_persistent_sample_pages可能导致冗长的 ANALYZE TABLE执行时间。估计数据库访问的页面的数量 ANALYZE TABLE,看到 第15.6.11.3,“估计分析表的复杂性InnoDB表” innodb_stats_persistent_sample_pages只适用于当 innodb_stats_persistent是一个表时启用; innodb_stats_persistent被禁用, innodb_stats_transient_sample_pages适用于代替 innodb_stats_transient_sample_pages财产 价值 命令行格式 --innodb-stats-transient-sample-pages=#系统变量 innodb_stats_transient_sample_pages范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 8指标的数量 网页 样本估计 基数 和其他 统计 对于索引列,如计算 ANALYZE TABLE。默认值是8。增加值提高了指标统计的准确性,从而提高 查询执行计划 ,以增加I/O打开 InnoDB表或重新计算统计。有关更多信息,参见 第15.6.11.2,“配置非持续优化统计参数 笔记 设置较高的值 innodb_stats_transient_sample_pages可能导致冗长的 ANALYZE TABLE执行时间。估计数据库访问的页面的数量 ANALYZE TABLE,看到 第15.6.11.3,“估计分析表的复杂性InnoDB表” innodb_stats_transient_sample_pages只适用于当 innodb_stats_persistent是一个表时禁用; innodb_stats_persistent启用, innodb_stats_persistent_sample_pages适用于代替。需要的地方 _ InnoDB数据_ _ pages样品 。有关更多信息,参见 第15.6.11.2,“配置非持续优化统计参数 财产 价值 命令行格式 --innodb-status-output系统变量 innodb_status_output范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF启用或禁用的标准周期输出 InnoDB显示器同时结合使用 innodb_status_output_locks启用或禁用周期输出 InnoDB 锁监视器。有关更多信息,参见 第15.16.2,“启用InnoDB监视器” 财产 价值 命令行格式 --innodb-status-output-locks系统变量 innodb_status_output_locks范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF可使用或可转让 InnoDB锁监视器。When enabled,the InnoDB 指纹锁锁监视器中的附加信息 SHOW ENGINE INNODB STATUS输出和输出打印周期对MySQL错误日志。对于周期性输出 InnoDB 锁监视器是印刷作为标准的一部分 InnoDB监视器输出。茶叶标准 InnoDB 因此,必须启用的监控 InnoDB锁监视器打印数据到MySQL错误日志定期。有关更多信息,参见 第15.16.2,“启用InnoDB监视器” 财产 价值 命令行格式 --innodb-strict-mode=#系统变量 innodb_strict_mode范围 全球会议 动态 是 set_var 提示应用 否 类型 布尔 默认值 ON什么时候 innodb_strict_mode启用, InnoDB Returns Erles rather than wawnings for certain conditions . 严格模式 有助于防止忽略错别字和SQL语法错误,或其他意想不到的后果的各种组合的操作模式和SQL语句。什么时候 innodb_strict_mode启用, InnoDB 提出了在某些情况下的错误条件,而不是发出警告和处理指定的声明(也许是无意的行为)。这是类似于 sql_mode在MySQL中,控制MySQL接受SQL语法,并确定它默默地忽略错误,或者验证输入的语法和数据值。 这个 innodb_strict_mode设置影响语法错误的处理 CREATE TABLE, ALTER TABLE, CREATE INDEX,和 OPTIMIZE TABLE声明. innodb_strict_mode 也使一个记录大小检查,以便 INSERT或 更新 从来没有因为记录被选定的页面尺寸太大。 Oracle建议使 innodb_strict_mode当使用 row_format 和 KEY_BLOCK_SIZE条款 CREATE TABLE, ALTER TABLE,和 CREATE INDEX声明.什么时候 innodb_strict_mode 被禁用, InnoDB忽略了冲突的条款和创造在消息日志警告表或索引。结果表可能比预期的不同的特点,如压缩支持缺乏尝试创建一个压缩的表时。什么时候 innodb_strict_mode 启用,这样的问题产生立竿见影的误差和不创建表或索引。 您可以启用或禁用 innodb_strict_mode在命令行启动时 mysqld ,或在一个MySQL 配置文件 。您还可以启用或禁用 innodb_strict_mode在报表运行时 SET [GLOBAL|SESSION] innodb_strict_mode=mode,在那里 mode要么是 打开(放) 或 OFF。改变 全球 设置要求 SYSTEM_VARIABLES_ADMIN或 超级的 特权和影响所有的客户,随后连接操作。任何客户端都可以改变 SESSION设置 innodb_strict_mode ,并设置只影响客户端。 innodb_strict_mode不适用于 禁忌将军 。对于一般的表空间,表空间管理制度严格执行独立 innodb_strict_mode。有关更多信息,参见 第13.1.19,“创建表的语法” 财产 价值 命令行格式 --innodb-sync-array-size=#系统变量 innodb_sync_array_size范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 1最小值 1最大值 1024定义大小的互斥锁等待阵列/。增加值将内部数据结构用来协调线程,在大量等待的线程负载高并发。此设置必须配置MySQL实例启动时,不能改变之后。增加价值的建议,经常产生大量等待的线程的工作负载,通常大于768。 财产 价值 命令行格式 --innodb-sync-spin-loops=#系统变量 innodb_sync_spin_loops范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 30最小值 0最大值 4294967295一个线程等待的次数 InnoDB互斥锁被释放之前,线程被挂起。 财产 价值 命令行格式 --innodb-sync-debug=#系统变量 innodb_sync_debug范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 OFF使同步调试的检查 InnoDB存储引擎。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-table-locks系统变量 innodb_table_locks范围 全球会议 动态 是 set_var 提示应用 否 类型 布尔 默认值 TRUE如果 autocommit = 0, InnoDB 荣誉 LOCK TABLESMySQL不回来; 锁定表…写 直到所有其他线程释放所有的锁表。默认值 innodb_table_locks一,这意味着 LOCK TABLES导致InnoDB锁定表内如果 autocommit = 0在MySQL 5.0, innodb_table_locks = 0没有效果明确锁定表 LOCK TABLES ... WRITE。它有一个效果表锁定为读或写的 LOCK TABLES ... WRITE隐式(例如,通过触发)或 LOCK TABLES ... READ相关的信息,看 第15,“InnoDB锁和事务模型” 财产 价值 命令行格式 --innodb-temp-data-file-path=file系统变量 innodb_temp_data_file_path范围 全球 动态 否 set_var 提示应用 否 类型 字符串 默认值 ibtmp1:12M:autoextend定义了相对路径、名称、大小、属性 InnoDB临时表空间 数据文件 。如果你不指定一个值 innodb_temp_data_file_path,默认行为是创建一个自动扩展数据文件命名 ibtmp1 在MySQL数据目录,略大于12mb。 一个临时表空间的数据文件规范完整的语法包括文件名,文件大小,和 autoextend和 最大值 属性: file_name:file_size[:autoextend[:max:max_file_size]]临时表空间的数据文件不能作为另一个相同的名字 InnoDB数据文件。任何不能或错误创建临时表空间的数据文件被视为致命的和服务器启动时被拒绝。临时表空间是一个动态的生成空间ID,它可以改变每个服务器上重新启动。 文件大小指定KB、MB或GB(即1024MB)通过添加 K, M 或 G的大小值。对文件的大小的总和必须略大于12mb。 单个文件的大小限制是由操作系统决定的。你可以设置文件的大小超过4GB,支持大文件的操作系统。临时表空间的数据文件的磁盘分区不支持使用。 这个 autoextend和 最大值 属性可以只用于指定数据文件中的最后一个 innodb_temp_data_file_path设置。例如: [mysqld]innodb_temp_data_file_path=ibtmp1:50M;ibtmp2:12M:autoextend:max:500MB
如果您指定的 autoextend选项, InnoDB 扩展数据文件,如果它运行的自由空间。这个 autoextend增量64mb默认。修改增加,改变 innodb_autoextend_increment系统变量 临时表空间的数据文件的完整目录路径是通过连接定义的路径的形成 innodb_data_home_dir和 innodb_temp_data_file_path临时表空间是共享的 InnoDB临时表 在跑步前 InnoDB在只读模式,集 innodb_temp_data_file_path在数据目录以外的位置。路径必须相对于数据目录。例如: --innodb_temp_data_file_path=../../../tmp/ibtmp1:12M:autoextend
元数据的活性 InnoDB临时表位于 INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO相关的信息,看 第15.4.11,临时表空间” 财产 价值 命令行格式 --innodb-temp-tablespaces-dir=dir_name介绍 8.0.13 系统变量 innodb_temp_tablespaces_dir范围 全球 动态 否 set_var 提示应用 否 类型 目录名称 默认值 .#innodb_temp场的位置在哪里? InnoDB创建启动一池会话的临时表空间。默认位置是 # InnoDB _温度 在数据目录的目录。一个完全合格的路径或相对路径的数据可以指定目录。 什么时候 internal_tmp_disk_storage_engine=InnoDB,一个会话的临时表空间分配给会话的第一个请求创建一个用户或优化内部临时表。一个最大的两个临时表空间分配给每个会议,为用户创建临时表和其他优化的内部临时表。额外的临时表空间自动添加到池中是必要的。当一个会话断开连接,临时表空间被截断和放生池。临时表空间的池每次都重新创建服务器重新启动。会话的临时表空间的文件有 托福网考 文件扩展名 财产 价值 命令行格式 --innodb-thread-concurrency=#系统变量 innodb_thread_concurrency范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最小值 0最大值 1000InnoDB试图保持操作系统线程的数量,同时在 InnoDB 小于或等于该变量的极限( InnoDB使用操作系统的线程来处理用户事务)。一旦线程数达到此限制,额外的线程进入等待状态中 “ 第一,先出 “ (FIFO)队列执行。等待锁的线程不计算在许多并发执行的线程。 这一变量的范围是0到1000。值0(默认值)被解释为无限并发(无并发检查)。禁用线程并发检查使 InnoDB创建多线程需要。0值也禁用 在InnoDB查询 和 queries in queue counters在 行操作 段 SHOW ENGINE INNODB STATUS输出 考虑设置这个变量如果你的MySQL实例共享CPU资源与其他应用程序,或者如果你的工作量或并发用户数的增长。正确的设置取决于工作量,计算环境和版本的MySQL,你正在运行。你将需要测试的值的范围来确定设置,提供了最佳的性能。 innodb_thread_concurrency是一个动态的变量,它可以让你尝试不同的设置,在现场测试系统。如果一个特定的环境表现不佳,你可以快速的设置 innodb_thread_concurrency 回到0 使用以下指南帮助寻找和保持一个适当的设置: 如果一个工作量用户并发线程数小于64,集 innodb_thread_concurrency=0如果你的工作量是一贯重或偶尔穗状花序,先设定 innodb_thread_concurrency=128然后降低值为96, 80, 64,等等,直到找到你的线程提供了最佳的性能数。例如,假设你的系统通常有40到50的用户,但周期数增加到60, 70,甚至200。你会发现在80个并发用户的性能是稳定的而开始显示超过这个数量的回归。在这种情况下,你可以设置 innodb_thread_concurrency=80为了避免影响性能 如果你不想 InnoDB使用超过一定数量的虚拟CPU用户线程(20个虚拟CPU,例如),集 innodb_thread_concurrency 这个号码(或可能更低,根据绩效结果)。如果你的目标是将MySQL从其他应用程序,你可以考虑结合 mysqld过程完全虚拟CPU。但要注意,,,独家结合可能导致非最优的使用如果硬件 mysqld 过程是不是一直忙。在这种情况下,你可能会把 mysqld过程的虚拟CPU也允许其他应用程序使用的一些或所有的虚拟CPU。 笔记 从操作系统的角度来看,使用资源管理解决方案来管理应用程序之间共享CPU时间可能是最好的结合 mysqld过程。例如,你可以分配90%个虚拟CPU时间为一个给定的应用程序在其他关键流程 是不是 跑步,和规模,值回40%当其他关键流程 是 运行 innodb_thread_concurrency太高的值可能导致由于增加了对系统内部资源竞争绩效的回归。 在某些情况下,最佳的 innodb_thread_concurrency设置可以小于虚拟CPU数量。 定期系统分析。改变工作量,用户数,或计算环境可能需要你调整 innodb_thread_concurrency设置
相关的信息,看 第15.6.5,“配置InnoDB线程并发 财产 价值 命令行格式 --innodb-thread-sleep-delay=#系统变量 innodb_thread_sleep_delay范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 10000最小值 0最大值 1000000多久 InnoDB线程睡眠之前加入 InnoDB 队列,在微秒。默认值是一万。值为0时禁止。你可以设置配置选项 innodb_adaptive_max_sleep_delay你会允许的最高值 innodb_thread_sleep_delay ,和 InnoDB自动调整 innodb_thread_sleep_delay 向上或向下取决于当前线程调度活动。这种动态的调整有助于线程调度机制时,当系统负载较轻时顺利工作或接近满负荷运行。 有关更多信息,参见 第15.6.5,“配置InnoDB线程并发 财产 价值 命令行格式 --innodb-tmpdir=path系统变量 innodb_tmpdir范围 全球会议 动态 是 set_var 提示应用 否 类型 目录名称 默认值 NULL用于定义临时排序文件创建在网上另一个目录 ALTER TABLE作业是rebuild桌。 在线 ALTER TABLE操作重建表同时也创造了一个 媒介 在同一个目录表文件作为原始表。这个 innodb_tmpdir选项不适用于中间表文件。 一个有效的值不是MySQL数据目录路径的目录路径。如果值为空(默认),临时文件创建MySQL临时目录( $TMPDIR在UNIX, %temp% 在Windows中,或者指定的目录下 --tmpdir配置选项)。如果指定的目录,目录和权限存在只检查时 _ tmpdir InnoDB 被配置为使用一个 SET声明。如果一个链接是一个目录,链接是解决存储为一个绝对路径。路径不能超过512个字节。一个在线 ALTER TABLE运行报告错误如果 _ tmpdir InnoDB 设置为一个无效的目录。 innodb_tmpdir重写的MySQL tmpdir设置只有在线 ALTER TABLE运营 这个 FILE特权是需要配置 _ tmpdir InnoDB 这个 innodb_tmpdir期权的引入有助于避免溢出的临时文件目录位于 临时文件系统 文件系统。这种溢出可能由于大型临时排序文件创建在网上出现 ALTER TABLE操作重建表 复制环境中,只考虑复制 innodb_tmpdir如果所有的服务器都有相同的操作系统环境设置。否则,复制 _ tmpdir InnoDB 设置可能会导致复制失败在线运行时 ALTER TABLE操作重建表。如果服务器运行环境的不同,建议您配置 _ tmpdir InnoDB 在每个单独的服务器 有关更多信息,参见 第15.12.3,“在线DDL空间要求” 。关于在线 ALTER TABLE操作,看 15.12节,“InnoDB和在线DDL” innodb_trx_purge_view_update_only_debug财产 价值 命令行格式 --innodb-trx-purge-view-update-only-debug=#系统变量 innodb_trx_purge_view_update_only_debug范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF暂停删除标记的记录同时允许清除视图进行更新,清除。这个选项人为产生情况,清除视图更新但尚未完成清洗。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-trx-rseg-n-slots-debug=#系统变量 innodb_trx_rseg_n_slots_debug范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 0最大值 1024设置一个调试标记限制 TRX_RSEG_N_SLOTS一个给定的值为 trx_rsegf_undo_find_free 功能看起来免费的插槽,UNDO日志片段。此选项仅可如果调试支持编译使用 WITH_DEBUGCMake 选项 财产 价值 命令行格式 --innodb-undo-directory=dir_name系统变量 innodb_undo_directory范围 全球 动态 否 set_var 提示应用 否 类型 目录名称 路径 InnoDB创建撤销表空间。通常用于将撤消对不同存储设备的日志。配合使用 innodb_rollback_segments和 innodb_undo_tablespaces没有默认值(是空的)。如果没有指定路径,撤销表空间中创建MySQL数据目录,定义为 datadir有关更多信息,参见 第15.7.8”配置,撤销表空间” 财产 价值 命令行格式 --innodb-undo-log-encrypt=#介绍 8.0.1 系统变量 innodb_undo_log_encrypt范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 OFF控制加密撤消日志数据表使用加密 InnoDB表空间加密功能 。仅适用于撤销,放在单独的日志 基于还原表空间 。看到 第15.7.8”配置,撤销表空间” 。加密是不是撤消日志数据驻留在系统表空间支持。有关更多信息,参见 UNDO日志数据加密 财产 价值 命令行格式 --innodb-undo-log-truncate=#系统变量 innodb_undo_log_truncate范围 全球 动态 是 set_var 提示应用 否 类型 布尔 默认值 (>= 8.0.2)ON默认值 (<= 8.0.1)OFF当启用时,撤消超过定义的阈值的表空间 innodb_max_undo_log_size用于截断。只有撤销表空间可以被截断。截断撤消驻留在系统表空间的日志不支持。截断的发生,至少要有两个撤销表空间。 这个 innodb_purge_rseg_truncate_frequency配置选项可以用来加快撤消tablepaces截断。 财产 价值 命令行格式 --innodb-undo-logs=#过时的 是的(除去8.0.2) 系统变量 innodb_undo_logs范围 全球 动态 是 set_var 提示应用 否 类型 整数 默认值 128最小值 1最大值 128笔记 innodb_undo_logs在MySQL 8.0.2删除。 这个 innodb_undo_logs选项是一个别名 innodb_rollback_segments。更多信息,见描述 innodb_rollback_segments财产 价值 命令行格式 --innodb-undo-tablespaces=#过时的 8.0.4 系统变量 innodb_undo_tablespaces范围 全球 动态 (>= 8.0.2)是 动态 (<= 8.0.1)否 set_var 提示应用 否 类型 整数 默认值 (>= 8.0.2)2默认值 (<= 8.0.1)0最小值 (>= 8.0.3)2最小值 (<= 8.0.2)0最大值 (>= 8.0.2)127最大值 (<= 8.0.1)95数 基于还原表空间 用 InnoDB。默认的最小值为2 笔记 innodb_undo_tablespaces是过时的、将在未来的版本中删除。 UNDO日志可以在长期交易成为大。使用多个撤销表空间,减少任何一个undo表空间的大小。 在以前的版本, innodb_undo_tablespaces可以设置为0使用SYSTEM回滚段。大于0的值意味着在SYSTEM回滚段不再分配给交易。在MySQL 8,一个0的设置是不允许和回滚段不仅创造了在撤销表空间。 undo表空间文件中定义的位置创建 innodb_undo_directory。文件名的形式 undo _ NNN,在那里 NNN是撤销空间数 一个undo表空间文件取决于初始大小 innodb_page_size的价值。for the default 16K InnoDB 页面大小,初始的undo表空间的文件大小是10mib。4K,8K,32K、64K的页面大小,初始undo表空间文件大小7mib,8mib,20mib,和40mib,分别。 innodb_undo_tablespaces可配置在启动或在服务器正在运行。增加 innodb_undo_tablespaces设置创建指定数量的撤销表空间,并将其添加到列表主动撤销表空间。降低 innodb_undo_tablespaces设置删除撤销表空间从主动撤销表空间的表。然而,这些undo表空间仍然有效,直到他们不再使用现有的交易。撤销表空间是消极而不是删除,活动数量撤销表空间可以增加又容易。 有关更多信息,参见 第15.7.8”配置,撤销表空间” 财产 价值 命令行格式 --innodb-use-native-aio=#系统变量 innodb_use_native_aio范围 全球 动态 否 set_var 提示应用 否 类型 布尔 默认值 ON指定是否使用Linux的异步I/O子系统。这个变量适用于Linux系统,并且不能在服务器正在运行的改变。通常情况下,你不需要配置此选项,因为它是默认启用。 这个 异步I/O 的能力, InnoDB对Windows系统可在Linux系统。(其他Unix系统继续使用同步I/O调用。)这一功能提高了可扩展性的大量I/O密集型系统,这通常表明许多悬而未决的读/写 显示引擎INNODB STATUS \ G 输出 随着大量运行 InnoDBI/O线程,特别是运行多个这样的实例在同一台服务器的机器,可以超过对Linux系统的容量限制。在这种情况下,您可能会收到以下错误: EAGAIN:指定maxevents超过可用事件用户的限制。 你通常可以解决这个错误写一个更高的极限 /proc/sys/fs/aio-max-nr然而,如果使用异步I/O子系统在操作系统的问题,防止 InnoDB从一开始,你可以启动服务器 innodb_use_native_aio=0。这个选项也可以禁用自动启动时,如果 InnoDB 检测到一个潜在的问题,如组合 tmpdir位置, 临时文件系统 文件系统和Linux内核不支持AIO上 tmpfs有关更多信息,参见 第15.6.7,使用异步I/O的Linux” 这个 InnoDBversion number。在单独的MySQL版本为8.0,意大利 InnoDB 不适用,这个值是相同的 version服务器的数量 财产 价值 命令行格式 --innodb-write-io-threads=#系统变量 innodb_write_io_threads范围 全球 动态 否 set_var 提示应用 否 类型 整数 默认值 4最小值 1最大值 64数字I/O线程的写操作 InnoDB。默认值为4。读线程对应的是 innodb_read_io_threads。有关更多信息,参见 第15.6.6,“配置一些背景InnoDB I/O线程” 。通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O” 笔记 在Linux系统上,运行多个MySQL服务器(通常超过12)的默认设置 innodb_read_io_threads, innodb_write_io_threads ,和Linux aio-max-nr设置可以超过系统限制。理想的情况下,增加 AIO的最大NR 设置;作为一种替代方法,可以减少一个或两个MySQL的配置选项的设置。 同时考虑价值 sync_binlog,它控制的二进制日志同步到磁盘。 通用I/O调优建议,看 第8.5.8,“优化InnoDB的磁盘I / O”
15.14.1 InnoDB information_schema表压缩 15.14.2 InnoDB information_schema事务和锁定信息 15.14.3 InnoDB information_schema架构对象表 15.14.4 InnoDB表的架构信息_ fulltext index 15.14.5 InnoDB缓冲池表information_schema 15.14.6 InnoDB information_schema度量表 15.14.7 InnoDB information_schema临时表信息表 15.14.8 InnoDB表空间元数据检索information_schema.files
InnoDBINFORMATION_SCHEMA
InnoDBInnoDBINFORMATION_SCHEMASHOW TABLES
mysql> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB%';
MySQL
InnoDB
INNODB_CMP和 INNODB_CMP_RESET包含压缩操作的数量信息和所花费的时间进行压缩。 INNODB_CMPMEM和 INNODB_CMP_RESET包含有关内存分配的信息压缩方法。
INNODB_CMPINNODB_CMP_RESETPAGE_SIZE
INNODB_CMP_RESETINNODB_CMP_RESETINNODB_CMPINNODB_CMP_RESET
INNODB_CMPMEMINNODB_CMPMEM_RESETINNODB_CMPINNODB_CMP_RESET
内部细节
InnoDB
INNODB_CMPMEMINNODB_CMPMEM_RESETINNODB_CMPMEM_RESETINNODB_CMPMEM_RESETINNODB_CMPMEM_RESETINNODB_CMPMEM
INNODB_CMPINNODB_CMP_PER_INDEXINNODB_CMPMEM
INFORMATION_SCHEMA.INNODB_CMPCOMPRESS_TIME
INNODB_CMPMEMPAGE_SIZEINNODB_CMPMEM
INFORMATION_SCHEMA.INNODB_CMPMEMSUM(PAGE_SIZE*PAGES_FREE)=6784(SUM(RELOCATION_TIME)=0)
data_locksdata_lock_waitsINNODB_LOCKSINNODB_LOCK_WAITS
INFORMATION_SCHEMA
INNODB_TRX本: information_schema 表中包含的信息,对每一笔交易正在执行的内部 InnoDB,包括交易状态(例如,是否正在运行或等待一个锁),交易开始时,和特定的SQL语句的事务执行。 data_locks:这个性能模式表包含每一把锁的一行,每个锁请求被阻塞来等待持有的锁被释放: 对于每个持有锁一行,无论是持有锁的事务的状态( INNODB_TRX.TRX_STATE是 运行 , LOCK WAIT, 滚回去 或 COMMITTING) 每一笔交易在InnoDB,等待另一个事务释放锁( INNODB_TRX.TRX_STATE是 锁等待 )是完全由一个锁定请求被阻塞。阻塞锁请求的是一个行或表锁在一个不兼容的模式,另一个事务举行。一个锁定请求总是随着持有锁块的请求模式不兼容模式(读与写,共享与专属)。 阻塞的交易无法继续,直到其他事务提交或回滚,从而释放请求的锁。对于每一个阻止交易, data_locks包含一行描述每个锁的事务请求,并且它正在等待。
data_lock_waits:这个性能模式表表明交易正在等待一个特定的锁,或锁一个事务正在等待。这个表格包含一行或多行中每个阻止交易,说明锁请求和任何锁被阻断,请求。这个 requesting_engine_lock_id 价值是指一个事务请求的锁,和 BLOCKING_ENGINE_LOCK_ID价值是指锁(由另一个事务举行)防止第一交易的进行。对于任何给定的阻止交易,所有行 data_lock_waits有相同的价值 requesting_engine_lock_id 不同的价值观 BLOCKING_ENGINE_LOCK_ID
data_locksdata_lock_waitsINNODB_LOCKSINNODB_LOCK_WAITS
InnoDB
会话: BEGIN; SELECT a FROM t FOR UPDATE; SELECT SLEEP(100);
会话B: SELECT b FROM t FOR UPDATE;
会话C: SELECT c FROM t FOR UPDATE;
SELECT r.trx_id waiting_trx_id, r.trx_mysql_thread_id waiting_thread, r.trx_query waiting_query, b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread, b.trx_query blocking_query FROM performance_schema.data_lock_waits w INNER JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_engine_transaction_id INNER JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_engine_transaction_id;
sysinnodb_lock_waits
选择waiting_trx_id,waiting_pid,waiting_query,blocking_trx_id,blocking_pid,blocking_queryfrom sys.innodb_lock_waits;
A4 | 6 | SELECT b FROM t FOR UPDATE | A3 | 5 | SELECT SLEEP(100) |
A5 | 7 | SELECT c FROM t FOR UPDATE | A3 | 5 | SELECT SLEEP(100) |
A5 | 7 | SELECT c FROM t FOR UPDATE | A4 | 6 | SELECT b FROM t FOR UPDATE |
硫氧还蛋白B(会话ID A4,螺纹 六 )和会话C(TRX ID A5,螺纹 七 )都在等待会议(TRX ID A3,螺纹 五 ) 会话C等待会话B以及A阶段
INFORMATION_SCHEMAINNODB_TRXdata_locksdata_lock_waits
INNODB_TRX
A3 | RUN-NING | 2008-01-15 16:44:54 | NULL | NULL | 2 | 5 | SELECT SLEEP(100) |
A4 | LOCK WAIT | 2008-01-15 16:45:09 | A4:1:3:2 | 2008-01-15 16:45:09 | 2 | 6 | SELECT b FROM t FOR UPDATE |
A5 | LOCK WAIT | 2008-01-15 16:45:14 | A5:1:3:2 | 2008-01-15 16:45:14 | 2 | 7 | SELECT c FROM t FOR UPDATE |
data_locks
A3:1:3:2 | A3 | X | RECORD | test | t | PRIMARY | 0x0200 |
A4:1:3:2 | A4 | X | RECORD | test | t | PRIMARY | 0x0200 |
A5:1:3:2 | A5 | X | RECORD | test | t | PRIMARY | 0x0200 |
data_lock_waits
识别阻塞事务列表ID。在 sys.innodb_lock_waits表,阻塞的事务ID的列表 blocking_pid 价值 使用 blocking_pid,查询MySQL性能模式 threads表确定 thread_id 阻塞的交易。例如,如果 blocking_pid6、本查询问题: SELECT THREAD_ID FROM performance_schema.threads WHERE PROCESSLIST_ID = 6;
使用 THREAD_ID,查询性能架构 events_statements_current表确定的线程中执行的最后一个查询。例如,如果 thread_id 28、本查询问题: SELECT THREAD_ID, SQL_TEXT FROM performance_schema.events_statements_current WHERE THREAD_ID = 28\G
如果线程执行的最后一个查询没有足够的信息来确定为什么加锁,你可以查询性能模式 events_statements_history表观10个语句的线程中执行。 SELECT THREAD_ID, SQL_TEXT FROM performance_schema.events_statements_history WHERE THREAD_ID = 28 ORDER BY EVENT_ID;
InnoDB
INFORMATION_SCHEMAINNODB_TRXdata_locksdata_lock_waits
data_locksdata_lock_waits
INFORMATION_SCHEMAPROCESSLISTINNODB_TRX
PROCESSLIST
384 | root | localhost | test | Query | 10 | update | INSERT INTO t2 VALUES … |
257 | root | localhost | test | Query | 3 | update | INSERT INTO t2 VALUES … |
130 | root | localhost | test | Query | 0 | update | INSERT INTO t2 VALUES … |
61 | root | localhost | test | Query | 1 | update | INSERT INTO t2 VALUES … |
8 | root | localhost | test | Query | 1 | update | INSERT INTO t2 VALUES … |
4 | root | localhost | test | Query | 0 | preparing | SELECT * FROM PROCESSLIST |
2 | root | localhost | test | Sleep | 566 | | NULL |
INNODB_TRX
77F | LOCK WAIT | 2008-01-15 13:10:16 | 77F | 2008-01-15 13:10:16 | 1 | 876 | INSERT INTO t09 (D, B, C) VALUES … |
77E | LOCK WAIT | 2008-01-15 13:10:16 | 77E | 2008-01-15 13:10:16 | 1 | 875 | INSERT INTO t09 (D, B, C) VALUES … |
77D | LOCK WAIT | 2008-01-15 13:10:16 | 77D | 2008-01-15 13:10:16 | 1 | 874 | INSERT INTO t09 (D, B, C) VALUES … |
77B | LOCK WAIT | 2008-01-15 13:10:16 | 77B:733:12:1 | 2008-01-15 13:10:16 | 4 | 873 | INSERT INTO t09 (D, B, C) VALUES … |
77A | RUN-NING | 2008-01-15 13:10:16 | NULL | NULL | 4 | 872 | SELECT b, c FROM t09 WHERE … |
E56 | LOCK WAIT | 2008-01-15 13:10:06 | E56:743:6:2 | 2008-01-15 13:10:06 | 5 | 384 | INSERT INTO t2 VALUES … |
E55 | LOCK WAIT | 2008-01-15 13:10:06 | E55:743:38:2 | 2008-01-15 13:10:13 | 965 | 257 | INSERT INTO t2 VALUES … |
19C | RUN-NING | 2008-01-15 13:09:10 | NULL | NULL | 2900 | 130 | INSERT INTO t2 VALUES … |
E15 | RUN-NING | 2008-01-15 13:08:59 | NULL | NULL | 5395 | 61 | INSERT INTO t2 VALUES … |
51D | RUN-NING | 2008-01-15 13:08:47 | NULL | NULL | 9807 | 8 | INSERT INTO t2 VALUES … |
data_lock_waits
77F | 77F:806 | 77E | 77E:806 |
77F | 77F:806 | 77D | 77D:806 |
77F | 77F:806 | 77B | 77B:806 |
77E | 77E:806 | 77D | 77D:806 |
77E | 77E:806 | 77B | 77B:806 |
77D | 77D:806 | 77B | 77B:806 |
77B | 77B:733:12:1 | 77A | 77A:733:12:1 |
E56 | E56:743:6:2 | E55 | E55:743:6:2 |
E55 | E55:743:38:2 | 19C | 19C:743:38:2 |
data_locks
77F:806 | 77F | AUTO_INC | TABLE | test | t09 | NULL | NULL |
77E:806 | 77E | AUTO_INC | TABLE | test | t09 | NULL | NULL |
77D:806 | 77D | AUTO_INC | TABLE | test | t09 | NULL | NULL |
77B:806 | 77B | AUTO_INC | TABLE | test | t09 | NULL | NULL |
77B:733:12:1 | 77B | X | RECORD | test | t09 | PRIMARY | supremum pseudo-record |
77A:733:12:1 | 77A | X | RECORD | test | t09 | PRIMARY | supremum pseudo-record |
E56:743:6:2 | E56 | S | RECORD | test | t2 | PRIMARY | 0, 0 |
E55:743:6:2 | E55 | X | RECORD | test | t2 | PRIMARY | 0, 0 |
E55:743:38:2 | E55 | S | RECORD | test | t2 | PRIMARY | 1922, 1922 |
19C:743:38:2 | 19C | X | RECORD | test | t2 | PRIMARY | 1922, 1922 |
data_locksdata_lock_waitsINNODB_LOCKSINNODB_LOCK_WAITS
SELECT FOR UPDATEInnoDB
RUNNINGINFORMATION_SCHEMAINNODB_TRX
data_locksdata_lock_waits
data_locksdata_lock_waitsINNODB_LOCKSINNODB_LOCK_WAITS
INFORMATION_SCHEMAINNODB_TRXdata_locksdata_lock_waits
数据可能不一致 INNODB_TRX, data_locks,和 data_lock_waits表 这个 data_locks和 data_lock_waits表揭露生活资料 InnoDB 存储引擎,提供锁信息在交易 INNODB_TRX表数据检索从锁表时存在 SELECT被执行,但可能会消失或被时间的查询结果是由客户端所消耗的变化。 加入 data_locks与 data_lock_waits可以显示行 data_lock_waits识别母行 data_locks不再存在或不存在 在交易数据和锁定表可能不与数据一致性 INFORMATION_SCHEMAPROCESSLIST表或性能模式 threads表 例如,你应该小心,当数据的比较 InnoDB交易和锁定表中的数据 PROCESSLIST表即使你的问题单 选择 (加入 INNODB_TRX和 PROCESSLIST,例如),这些表的内容通常是不一致的。这是可能的 INNODB_TRX为了不在参考行 PROCESSLIST或当前正在执行的SQL查询交易显示 _ trx.trx _ InnoDB查询 不同于一 PROCESSLIST.INFO
InnoDBINFORMATION_SCHEMAInnoDBSHOW ENGINE INNODB
STATUSINFORMATION_SCHEMA
InnoDB
INNODB_DATAFILES INNODB_TABLESTATS INNODB_FOREIGN INNODB_COLUMNS INNODB_INDEXES INNODB_FIELDS INNODB_TABLESPACES INNODB_TABLESPACES_BRIEF INNODB_FOREIGN_COLS INNODB_TABLES
INNODB_TABLES提供元数据 InnoDB 表 INNODB_COLUMNS提供元数据 InnoDB 表列 INNODB_INDEXES提供元数据 InnoDB 指标 INNODB_FIELDS提供有关关键列(字段)的元数据 InnoDB 指标 INNODB_TABLESTATS提供了一个从低级状态信息 InnoDB 表是从内存中的数据结构。 INNODB_DATAFILES提供数据文件的路径信息 InnoDB 每个表和一般的表空间文件。 INNODB_TABLESPACES提供元数据 InnoDB 每个表和一般的表空间文件。 INNODB_TABLESPACES_BRIEF提供元数据子集 InnoDB 表空间 INNODB_FOREIGN提供关于外键定义的元数据 InnoDB 表 INNODB_FOREIGN_COLS提供关于被定义在外键列的元数据 InnoDB 表
InnoDBTABLE_IDSPACE
InnoDB
t1InnoDB
创建一个测试数据库和表 t1: MySQL的> CREATE DATABASE test;MySQL的> USE test;MySQL的> CREATE TABLE t1 (col1 INT,col2 CHAR(10),col3 VARCHAR(10))ENGINE = InnoDB;MySQL的> CREATE INDEX i1 ON t1(col1);在创建表 t1,查询 INNODB_TABLES定位元数据 测试/ T1 : mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test/t1' \G*************************** 1. row *************************** TABLE_ID: 71 NAME: test/t1 FLAG: 1 N_COLS: 6 SPACE: 57 ROW_FORMAT: Compact ZIP_PAGE_SIZE: 0 INSTANT_COLS: 0表 t1有一个 table_id Of 71 .the FLAG现场提供的比特级信息表的格式和存储特性。有六列,其中三列是隐藏的 InnoDB ( DB_ROW_ID, _ TRX _ DB ID ,和 DB_ROLL_PTR)。该表的ID 空间 57(0值表示该表驻留在系统表空间)。这个 ROW_FORMAT紧凑 zip_page_size 只适用于表一 Compressed行格式 瞬间 显示列数增加立即使用 ALTER TABLE ... ADD COLUMN与 ALGORITHM=INSTANT使用 TABLE_ID信息 INNODB_TABLES,查询 INNODB_COLUMNS关于表的列信息表 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_COLUMNS where TABLE_ID = 71\G*************************** 1。行*************************** table_id:71名称:col1 POS:0 M型:6:1027:4 prtype Len has_default:0default_value:空*************************** 2。行*************************** table_id:71名称:COL2 POS:1米型:2:524542:10 prtype Len has_default:0default_value:空*************************** 3。行*************************** table_id:71名称:col3名次:2米型:1:524303:10 prtype Len has_default:0default_value:空 除了对 TABLE_ID柱 姓名 , INNODB_COLUMNS提供的序号位置( 销售时点情报系统 )每列(从0和递增的顺序),列 MTYPE或 “ 主要类型 “ (6 = INT, 2 = CHAR, 1 = VARCHAR), thePRTYPE或 “ 精密型 “ (二值位代表MySQL数据类型、字符集编码,并为空性),和列长度( LEN页:1的 你_违约 和 DEFAULT_VALUE列仅适用于列添加立即使用 修改表…添加列 与 ALGORITHM=INSTANT使用 TABLE_ID信息 INNODB_TABLES再次,查询 INNODB_INDEXES关于与表的索引信息 T1 mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_INDEXES WHERE TABLE_ID = 71 \G*************************** 1. row *************************** INDEX_ID: 111 NAME: GEN_CLUST_INDEX TABLE_ID: 71 TYPE: 1 N_FIELDS: 0 PAGE_NO: 3 SPACE: 57 MERGE_THRESHOLD: 50 *************************** 2. row *************************** INDEX_ID: 112 NAME: i1 TABLE_ID: 71 TYPE: 0 N_FIELDS: 1 PAGE_NO: 4 SPACE: 57 MERGE_THRESHOLD: 50INNODB_INDEXES返回两个指标数据。第一个指标是 gen_clust_index ,这是一个聚集索引的创建 InnoDB如果表中没有定义聚集索引。第二指数( 1 )是用户定义的辅助索引。 这个 INDEX_ID对于指数是独特的在所有的数据库实例标识符。这个 table_id 确定的表,索引关联的。该指数 TYPEvalue indicates the type of index (1 = Clustered Index, 0 = Secondary index). Then_fileds 价值领域,包括数 PAGE_NO为索引B树的根页号,和 空间 是在索引所在的表空间ID。非零值表示指数不存在于系统表空间。 MERGE_THRESHOLD定义在一个索引页的数据量的百分比阈值。如果在一个索引页的数据量低于此值(默认为50)当删除一行或一行后缩短了更新操作, InnoDB 试图索引页与相邻的索引页合并。 使用 INDEX_ID信息 INNODB_INDEXES,查询 INNODB_FIELDS有关索引字段的信息 1 mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FIELDS where INDEX_ID = 112 \G*************************** 1. row *************************** INDEX_ID: 112 NAME: col1 POS: 0INNODB_FIELDS提供 姓名 索引的字段及其顺序的索引位置。如果指数(I1)已经在多个领域定义, INNODB_FIELDS将为每个索引字段的元数据。 使用 SPACE信息 INNODB_TABLES,查询 INNODB_TABLESPACES有关表的表空间表 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLESPACES WHERE SPACE = 57 \G*************************** 1。行***************************空间:57名:测试/ T1标志:16417 row_format:动态page_size:16384 zip_page_size:0 space_type:单fs_block_size:4096 file_size:114688allocated_size:98304server_version:8.0.4 space_version:1. 除了对 SPACE我的表空间和 姓名 相关表的, INNODB_TABLESPACES提供空间 标志 数据,这是位信息表的格式和存储特性。还提供了空间 ROW_FORMAT, page_size ,和其他几个表空间元数据项。 使用 SPACE信息 INNODB_TABLES再次,查询 INNODB_DATAFILESfor the租赁of the表空间的数据文件。 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_DATAFILES WHERE SPACE = 57 \G*************************** 1。行***************************空间:57条路径:/测试/ t1.ibd。 数据文件位于 test在MySQL的目录 数据 目录。如果在 文件表 表空间创建在MySQL数据目录的位置使用 DATA DIRECTORY的条款 CREATE TABLE语句,表空间 路径 将是一个完全合格的路径。 最后一步,在表中插入一行 t1( TABLE_ID = 71)和视图中的数据 INNODB_TABLESTATS表本表数据由MySQL优化器计算指数使用查询时使用 InnoDB 表这个信息是从内存中的数据结构。 mysql>
INSERT INTO t1 VALUES(5, 'abc', 'def');Query OK, 1 row affected (0.06 sec) mysql>SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLESTATS where TABLE_ID = 71 \G*************************** 1. row *************************** TABLE_ID: 71 NAME: test/t1 STATS_INITIALIZED: Initialized NUM_ROWS: 1 CLUST_INDEX_SIZE: 1 OTHER_INDEX_SIZE: 0 MODIFIED_COUNTER: 1 AUTOINC: 0 REF_COUNT: 1这个 STATS_INITIALIZED指出是否统计已收集表。 num_rows 是目前的估计数的表中的行。这个 CLUST_INDEX_SIZE和 其他_指数_大小 田野报告存储集群和表的辅助索引的磁盘页面的数量,分别。这个 MODIFIED_COUNTER值显示行的外键的DML操作和级联操作修改数。这个 autoinc 价值是下一个数字发行任何递增的基础操作。有没有自动递增列定义表 t1,所以值为0。这个 折扣计数 价值是一个计数器。当计数器达到0,这意味着表的元数据可以逐出表缓存。
INNODB_FOREIGNINNODB_FOREIGN_COLSINNODB_FOREIGNINNODB_FOREIGN_COLS
创建测试数据库与父表和子表: mysql>
CREATE DATABASE test;mysql>USE test;mysql>CREATE TABLE parent (id INT NOT NULL,PRIMARY KEY (id)) ENGINE=INNODB;mysql>CREATE TABLE child (id INT, parent_id INT,INDEX par_ind (parent_id),CONSTRAINT fk1FOREIGN KEY (parent_id) REFERENCES parent(id)ON DELETE CASCADE) ENGINE=INNODB;在父表和子表的创建,查询 INNODB_FOREIGN定位为国外关键数据 测试/儿童 和 test/parent外键关系: MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FOREIGN \G*************************** 1。行*************************** ID:测试/ fk1for_name:测试/ childref_name:测试/母n_cols:1型:1 元数据包括外键 ID( FK1 ),这是命名为“ CONSTRAINT这是对孩子表定义。这个 for_name 是孩子的名字表的外键定义。 REF_NAME是父表的名称(的 “ 引用 “ 目录(续) N_COLS在外键索引的列数 类型 是一个表示位标志提供关于外键列的附加信息的数值。在这种情况下,的 TYPE值为1,这表明 级联删除 期权是外键指定。看到 INNODB_FOREIGN为更多的信息关于表的定义 类型 价值观 使用外键 ID,查询 INNODB_FOREIGN_COLS查看关于外键列的数据。 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FOREIGN_COLS WHERE ID = 'test/fk1' \G*************************** 1。行*************************** ID:测试/ fk1for_col_name:parent_idref_col_name:ID名次:0 FOR_COL_NAME是在子表的外键列的名称,并 中领领领 是引用列在父表的名称。这个 POS值在外键索引键字段的顺序位置,从零开始。
InnoDBINNODB_TABLESINNODB_TABLESPACESINNODB_TABLESTATS
IF()PAGE_SIZEOTHER_INDEX_SIZEROUND()
MySQL的> SELECT a.NAME, a.ROW_FORMAT,@page_size :=IF(a.ROW_FORMAT='Compressed',b.ZIP_PAGE_SIZE, b.PAGE_SIZE)AS page_size,ROUND((@page_size * c.CLUST_INDEX_SIZE)/(1024*1024)) AS pk_mb,ROUND((@page_size * c.OTHER_INDEX_SIZE)/(1024*1024)) AS secidx_mbFROM INFORMATION_SCHEMA.INNODB_TABLES aINNER JOIN INFORMATION_SCHEMA.INNODB_TABLESPACES b on a.NAME = b.NAMEINNER JOIN INFORMATION_SCHEMA.INNODB_TABLESTATS c on b.NAME = c.NAMEWHERE a.NAME LIKE 'employees/%'ORDER BY a.NAME DESC;------------------------ ------------ ----------- ------- ----------- |名字| row_format | page_size | pk_mb | secidx_mb | ------------------------ ------------ ----------- ------- ----------- |员工/职称|动态| 16384 | 20 | 11 | |员工薪金|动态| 16384 | 93 | 34 | |员工/员工|动态| 16384 | 15 | 0 | |员工/ dept_manager |动态| 16384 | 0 0 | | |员工/ dept_emp |动态| 16384 | 12 |十| |员工/部门|动态| 16384 | 0 0 | | ------------------------ ------------ ----------- ------- -----------
FULLTEXT
MySQL的> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_FT%';表中的信息------------------------------------------- | _ _ _模式(FT | InnoDB _ %)------------------------------------------- | InnoDB _ FT _ InnoDB配置| | _ FT _被_消去| | InnoDB _ FT _消去| | InnoDB默认_ FT _ _ +屏蔽词| | InnoDB _ FT _指数_ | | InnoDB表_ FT _指数_ | -------------------------------------------缓存
表概述
INNODB_FT_CONFIG:显示的元数据 全文 一个指数和相关处理 InnoDB表 INNODB_FT_BEING_DELETED:提供了一个快照 INNODB_FT_DELETED表仅用于在 OPTIMIZE TABLE维护操作。什么时候 OPTIMIZE TABLE是跑的 INNODB_FT_BEING_DELETED表是空的,和doc_ids远离 INNODB_FT_DELETED表因为内容 INNODB_FT_BEING_DELETED通常有一个短暂的一生中,这台具有有限的监控和调试工具。有关运行 OPTIMIZE TABLE在表 全文 指标,看 第12.9.6,“微调MySQL全文搜索” INNODB_FT_DELETED行:记录中删除 全文 指数为 InnoDB表为了避免昂贵的索引重组在DML操作的 InnoDB FULLTEXT关于新指标,删除的文字信息分别存储,过滤掉的搜索结果,当你执行文本搜索,然后取出主要的搜索指数只有当你运行 OPTIMIZE TABLEINNODB_FT_DEFAULT_STOPWORDA队列表: 停用词 这是默认的创建 FULLTEXT指数 INNODB_FT_INDEX_TABLE:包含了倒排索引的使用过程中对数据的文本搜索 全文 指数 INNODB_FT_INDEX_CACHE:包含新插入的行在令牌信息 全文 指数为了避免昂贵的索引重组在DML操作,了解新的索引词的信息分别存储,并结合主要的搜索指数只有 OPTIMIZE TABLE运行时,当服务器关闭,或者当缓存的大小超过一个极限的定义 innodb_ft_cache_size或 innodb_ft_total_cache_size
INNODB_FT_DEFAULT_STOPWORDinnodb_ft_aux_tabledatabase_nametable_nameInnoDBINFORMATION_SCHEMA
FULLTEXTINFORMATION_SCHEMA
在创建一个表 FULLTEXT指数和插入一些数据: MySQL的> CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)) ENGINE=InnoDB;MySQL的> INSERT INTO articles (title,body) VALUES('MySQL Tutorial','DBMS stands for DataBase ...'),('How To Use MySQL Well','After you went through a ...'),('Optimizing MySQL','In this tutorial we will show ...'),('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),('MySQL vs. YourSQL','In the following database comparison ...'),('MySQL Security','When configured properly, MySQL ...');设置 innodb_ft_aux_table变量表的名字与 全文 指数如果没有设置这个变量,这 InnoDB全文 INFORMATION_SCHEMA表出现空荡荡的,除了 INNODB_FT_DEFAULT_STOPWORD表 MySQL的> SET GLOBAL innodb_ft_aux_table = 'test/articles';查询 INNODB_FT_INDEX_CACHE表,这表明新插入的行中的信息 全文 指数为了避免昂贵的索引重组在DML操作,新插入的行的数据保留在 FULLTEXT直到索引缓存 OPTIMIZE TABLE运行(或直到服务器关闭或缓存超过限制)。 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE LIMIT 5;------------ -------------- ------------- ----------- -------- ---------- |字| first_doc_id | last_doc_id | doc_count | doc_id |位置| ------------ -------------- ------------- ----------- -------- ---------- | 1001 | 5 | 5 | 1 | 5 | 0 | |后| 3 | 3 | 1 | 3 | 22 | |比较| 6 | 6 1 6 44 | | | | |配置| 7 | 7 | 1 | 7 | 20 | |数据库| 2 | 6 | 2 | 2 | 31 | ------------ -------------- ------------- ----------- -------- ---------- 使 innodb_optimize_fulltext_only和运行 OPTIMIZE TABLE在表中包含 全文 指数此操作将该内容 FULLTEXT在主索引缓存 全文 指数 innodb_optimize_fulltext_only变化的方式 OPTIMIZE TABLE语句运行 InnoDB 表,旨在使暂时,在维护操作 InnoDB表 全文 指标 mysql>
SET GLOBAL innodb_optimize_fulltext_only=ON;Query OK, 0 rows affected (0.00 sec) mysql>OPTIMIZE TABLE articles;+---------------+----------+----------+----------+ | Table | Op | Msg_type | Msg_text | +---------------+----------+----------+----------+ | test.articles | optimize | status | OK | +---------------+----------+----------+----------+查询 INNODB_FT_INDEX_TABLE表观的主要数据信息 全文 指标,包括就得从数据信息 FULLTEXT索引缓存 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE LIMIT 5;------------ -------------- ------------- ----------- -------- ---------- |字| first_doc_id | last_doc_id | doc_count | doc_id |位置| ------------ -------------- ------------- ----------- -------- ---------- | 1001 | 5 | 5 | 1 | 5 | 0 | |后| 3 | 3 | 1 | 3 | 22 | |比较| 6 | 6 1 6 44 | | | | |配置| 7 | 7 | 1 | 7 | 20 | |数据库| 2 | 6 | 2 | 2 | 31 | ------------ -------------- ------------- ----------- -------- ---------- 这个 INNODB_FT_INDEX_CACHE表现在空自 OPTIMIZE TABLE操作冲 全文 索引缓存 mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE LIMIT 5;Empty set (0.00 sec)从删除一些记录 test/articles表 MySQL的> DELETE FROM test.articles WHERE id < 4;查询行,3行受影响(0.11秒) 查询 INNODB_FT_DELETED表本表中删除记录行 全文 指数为了避免昂贵的索引重组在DML操作,了解新的删除记录信息分别存储,过滤搜索结果的时候你做文本搜索,然后取出主要的搜索指数当你运行 OPTIMIZE TABLEMySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DELETED;-------- | DOC _ ID | -------- | 2 3 4 | | | | | -------- 运行 OPTIMIZE TABLE删除删除的记录 MySQL的> OPTIMIZE TABLE articles;--------------- ---------- ---------- ---------- |表| OP | msg_type | msg_text | --------------- ---------- ---------- ---------- | test.articles |优化|状态|好| --------------- ---------- ---------- ---------- 这个 INNODB_FT_DELETED表应该现在出现空 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DELETED;空集合(0秒) 查询 INNODB_FT_CONFIG表这个表格包含的元数据 全文 指数及相关处理: optimize_checkpoint_limit是多少秒后一 OPTIMIZE TABLE止损 synced_doc_id是下一个 DOC _ ID 将发行 stopword_table_name是的 database/table一个用户定义的表名称的词。这场出现空如果没有自定义词表。 use_stopword指示是否一词用桌子,它的定义是当 全文 创建索引
mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_CONFIG;+---------------------------+-------+ | KEY | VALUE | +---------------------------+-------+ | optimize_checkpoint_limit | 180 | | synced_doc_id | 8 | | stopword_table_name | | | use_stopword | 1 | +---------------------------+-------+
InnoDBInnoDB
InnoDB
mysql> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_BUFFER%';
+-----------------------------------------------+
| Tables_in_INFORMATION_SCHEMA (INNODB_BUFFER%) |
+-----------------------------------------------+
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_POOL_STATS |
+-----------------------------------------------+
表概述
INNODB_BUFFER_PAGE:对每个页面中的信息 InnoDB 缓冲池 INNODB_BUFFER_PAGE_LRU:持有约在页面信息 InnoDB 缓冲池,特别是它们是如何下令在LRU列表决定驱逐从缓冲池页面,当它变得完整。这个 INNODB_BUFFER_PAGE_LRU表具有相同的列为 INNODB_BUFFER_PAGE表,除了那 INNODB_BUFFER_PAGE_LRU桌子上有一个 _ LRU的位置 而不是列 BLOCK_ID专栏 INNODB_BUFFER_POOL_STATS:提供了缓冲池的状态信息。同样的信息是由 SHOW ENGINE INNODB STATUS输出,或可使用 InnoDB 缓冲池的服务器状态变量。
INNODB_BUFFER_PAGEINNODB_BUFFER_PAGE_LRU
TABLE_NAME/
mysql>SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);+----------+ | COUNT(*) | +----------+ | 1516 | +----------+
mysql>SELECT(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0)) AS system_pages,(SELECT COUNT(*)FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ROUND((system_pages/total_pages) * 100)) AS system_page_percentage;+--------------+-------------+------------------------+ | system_pages | total_pages | system_page_percentage | +--------------+-------------+------------------------+ | 295 | 8192 | 4 | +--------------+-------------+------------------------+
PAGE_TYPE
mysql>SELECT DISTINCT PAGE_TYPE FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NULL OR (INSTR(TABLE_NAME, '/') = 0 AND INSTR(TABLE_NAME, '.') = 0);+-------------------+ | PAGE_TYPE | +-------------------+ | SYSTEM | | IBUF_BITMAP | | UNKNOWN | | FILE_SPACE_HEADER | | INODE | | UNDO_LOG | | ALLOCATED | +-------------------+
TABLE_NAMENOT LIKE
'%INNODB_TABLES%'
MySQL的> SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NOT NULL AND TABLE_NAME NOT LIKE '%INNODB_TABLES%';---------- |计数(*)| ---------- | 7897 | ----------
mysql>SELECT(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NOT NULL AND (INSTR(TABLE_NAME, '/') > 0 OR INSTR(TABLE_NAME, '.') > 0)) AS user_pages,(SELECT COUNT(*)FROM information_schema.INNODB_BUFFER_PAGE) AS total_pages,(SELECT ROUND((user_pages/total_pages) * 100)) AS user_page_percentage;+------------+-------------+----------------------+ | user_pages | total_pages | user_page_percentage | +------------+-------------+----------------------+ | 7897 | 8192 | 96 | +------------+-------------+----------------------+
mysql>SELECT DISTINCT TABLE_NAME FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME IS NOT NULL AND (INSTR(TABLE_NAME, '/') > 0 OR INSTR(TABLE_NAME, '.') > 0)AND TABLE_NAME NOT LIKE '`mysql`.`innodb_%';+-------------------------+ | TABLE_NAME | +-------------------------+ | `employees`.`salaries` | | `employees`.`employees` | +-------------------------+
INDEX_NAMEemployees.salaries
MySQL的> SELECT INDEX_NAME, COUNT(*) AS Pages,ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@global.innodb_page_size, COMPRESSED_SIZE))/1024/1024)AS 'Total Data (MB)'FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE INDEX_NAME='emp_no' AND TABLE_NAME = '`employees`.`salaries`';| ------------ ------- -----------------总指数数据页| | _ name(MB)| ------------ ------- ----------------- | EMP _不| 1609 | 25 | ------------ -------;
employees.salaries
MySQL的> SELECT INDEX_NAME, COUNT(*) AS Pages,ROUND(SUM(IF(COMPRESSED_SIZE = 0, @@global.innodb_page_size, COMPRESSED_SIZE))/1024/1024)AS 'Total Data (MB)'FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGEWHERE TABLE_NAME = '`employees`.`salaries`'GROUP BY INDEX_NAME;------------ ------- ----------------- | index_name |页|总数据(MB)| ------------ ------- ----------------- | emp_no | 1608 | 25 | |初级| 6086 | 95 | ------------ ------- -----------------
INNODB_BUFFER_PAGE_LRUINNODB_BUFFER_PAGEBLOCK_ID
employees.employees
MySQL的> SELECT COUNT(LRU_POSITION) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE_LRUWHERE TABLE_NAME='`employees`.`employees`' AND LRU_POSITION < 3072;--------------------- |计数(lru_position)| --------------------- | 548 | ---------------------
INNODB_BUFFER_POOL_STATSSHOW ENGINE INNODB
STATUS
mysql> SELECT * FROM information_schema.INNODB_BUFFER_POOL_STATS \G
*************************** 1. row ***************************
POOL_ID: 0
POOL_SIZE: 8192
FREE_BUFFERS: 1
DATABASE_PAGES: 8173
OLD_DATABASE_PAGES: 3014
MODIFIED_DATABASE_PAGES: 0
PENDING_DECOMPRESS: 0
PENDING_READS: 0
PENDING_FLUSH_LRU: 0
PENDING_FLUSH_LIST: 0
PAGES_MADE_YOUNG: 15907
PAGES_NOT_MADE_YOUNG: 3803101
PAGES_MADE_YOUNG_RATE: 0
PAGES_MADE_NOT_YOUNG_RATE: 0
NUMBER_PAGES_READ: 3270
NUMBER_PAGES_CREATED: 13176
NUMBER_PAGES_WRITTEN: 15109
PAGES_READ_RATE: 0
PAGES_CREATE_RATE: 0
PAGES_WRITTEN_RATE: 0
NUMBER_PAGES_GET: 33069332
HIT_RATE: 0
YOUNG_MAKE_PER_THOUSAND_GETS: 0
NOT_YOUNG_MAKE_PER_THOUSAND_GETS: 0
NUMBER_PAGES_READ_AHEAD: 2713
NUMBER_READ_AHEAD_EVICTED: 0
READ_AHEAD_RATE: 0
READ_AHEAD_EVICTED_RATE: 0
LRU_IO_TOTAL: 0
LRU_IO_CURRENT: 0
UNCOMPRESS_TOTAL: 0
UNCOMPRESS_CURRENT: 0
SHOW ENGINE INNODB
STATUS
SHOW ENGINE INNODB
STATUS
mysql> SHOW ENGINE INNODB STATUS \G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 579084
Buffer pool size 8192
Free buffers 1
Database pages 8173
Old database pages 3014
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 15907, not young 3803101
0.00 youngs/s, 0.00 non-youngs/s
Pages read 3270, created 13176, written 15109
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 8173, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
...
mysql> SHOW STATUS LIKE 'Innodb_buffer%';
+---------------------------------------+-------------+
| Variable_name | Value |
+---------------------------------------+-------------+
| Innodb_buffer_pool_dump_status | not started |
| Innodb_buffer_pool_load_status | not started |
| Innodb_buffer_pool_resize_status | not started |
| Innodb_buffer_pool_pages_data | 8173 |
| Innodb_buffer_pool_bytes_data | 133906432 |
| Innodb_buffer_pool_pages_dirty | 0 |
| Innodb_buffer_pool_bytes_dirty | 0 |
| Innodb_buffer_pool_pages_flushed | 15109 |
| Innodb_buffer_pool_pages_free | 1 |
| Innodb_buffer_pool_pages_misc | 18 |
| Innodb_buffer_pool_pages_total | 8192 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 2713 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 33069332 |
| Innodb_buffer_pool_reads | 558 |
| Innodb_buffer_pool_wait_free | 0 |
| Innodb_buffer_pool_write_requests | 11985961 |
+---------------------------------------+-------------+
INNODB_METRICS
INNODB_METRICS
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts" \G
*************************** 1. row ***************************
NAME: dml_inserts
SUBSYSTEM: dml
COUNT: 46273
MAX_COUNT: 46273
MIN_COUNT: NULL
AVG_COUNT: 492.2659574468085
COUNT_RESET: 46273
MAX_COUNT_RESET: 46273
MIN_COUNT_RESET: NULL
AVG_COUNT_RESET: NULL
TIME_ENABLED: 2014-11-28 16:07:53
TIME_DISABLED: NULL
TIME_ELAPSED: 94
TIME_RESET: NULL
STATUS: enabled
TYPE: status_counter
COMMENT: Number of rows inserted
启用、禁用、复位计数器
innodb_monitor_enable:使一个或多个计数器。 SET GLOBAL innodb_monitor_enable = [counter-name|module_name|pattern|all];
innodb_monitor_disable:禁用一个或多个计数器。 SET GLOBAL innodb_monitor_disable = [counter-name|module_name|pattern|all];
innodb_monitor_reset:重置一个或多个计数器的计数值为零。 SET GLOBAL innodb_monitor_reset = [counter-name|module_name|pattern|all];
innodb_monitor_reset_all:重置所有值的一个或多个计数器。一个计数器必须在使用前被禁用 innodb_monitor_reset_allSET GLOBAL innodb_monitor_reset_all = [counter-name|module_name|pattern|all];
logmetadata_table_handles_closedmy.cnf
[mysqld]innodb_monitor_enable = module_recovery,metadata_table_handles_opened,metadata_table_handles_closed
innodb_monitor_enableinnodb_monitor_enable
计数器
INNODB_METRICS
SHOW ENGINE INNODB
STATUSSHOW ENGINE INNODB
STATUSINNODB_METRICS
INNODB_METRICSINNODB_METRICS
MySQL的> SELECT name, subsystem, status FROM INFORMATION_SCHEMA.INNODB_METRICS ORDER BY NAME;子系统名称------------------------------------------ ------------------------选择| | |状态自适应选择| ------------------------------------------ ------------------------ | _哈希_页面添加_ _ |自适应哈希指数| _残疾人| |自适应哈希_页面删除_ _ |自适应哈希指数_ _ |残疾人| _ |自适应哈希_ rows _增值|自适应_ _ |残疾人|哈希指数|自适应_ _ rows删除哈希散列_ _ _ NO _收|自适应哈希指数_ _ |残疾人| |自适应_ _ _ rows删除哈希散列索引|自适应_ _ |残疾人| |自适应_ _ rows _ |自适应更新哈希哈希索引_ _ |残疾人| | _ _ |自适应哈希搜索自适应散列索引_ _ | | |启用自适应哈希搜索_ _ _ btree指数_ |自适应哈希_ |启用缓冲数据读取| | _ _ |启用缓冲数据缓冲区| | | _ _写缓冲功能的| | | | _冲洗_自适应缓冲缓冲区缓冲区残疾人| | | | _冲洗_自适应_ AVG _护照|缓冲缓冲|残疾人| | _冲洗_自适应_ AVG _ _ EST |缓冲时间缓冲|残疾人| | _冲洗_自适应_ AVG _时_ |缓冲槽|残疾人| |缓冲_ _自适应_ AVG _冲洗时间_ | |残疾人线程缓冲缓冲| | _冲洗_自适应_页面缓冲| |残疾人| |缓冲_冲洗_完全自适应_ _页面缓冲| |残疾人| |缓冲_冲洗_ AVG _页缓冲_率| |残疾人| |缓冲_冲洗_ AVG _ |缓冲|残疾人| |护照_冲洗缓冲时间缓冲_ AVG _ | |残疾人| |缓冲_冲洗_背景|缓冲缓冲|残疾人| | _冲洗_背景_页面缓冲| |残疾人| |缓冲_冲洗_背景_完全_页面缓冲| |残疾人| |缓冲_ _ |批量冲洗缓冲区缓冲区残疾人| | | _间歇冲洗_ _ Num _扫描|缓冲缓冲|残疾人| | _间歇冲洗_ _页面缓冲| |残疾人| |缓冲_间歇冲洗_ _扫描|缓冲缓冲|残疾人| | _间歇冲洗_ _扫描_呼叫通过_ | |残疾人| |缓冲器缓冲器_间歇冲洗_ _完全_页面缓冲| |残疾人| |缓冲_冲洗_ lsn _ AVG _率|缓冲缓冲|残疾人| | _冲洗_近邻|缓冲缓冲|残疾人| | _冲洗_近邻_页面缓冲| |残疾人| |缓冲_冲洗_近邻_完全| _页面缓冲|残疾人| |缓冲_冲洗冲洗_ _ N到_ _ red _时代|缓冲缓冲|残疾人| | _冲洗冲洗_ _ N到_ _请求缓冲| |残疾人| |缓冲_冲洗肮脏的_ PCT _ _ | |禁用缓存
计数器模块
SUBSYSTEMINNODB_METRICSdml
MySQL的> SET GLOBAL innodb_monitor_enable = module_dml;MySQL的> SELECT name, subsystem, status FROM INFORMATION_SCHEMA.INNODB_METRICSWHERE subsystem ='dml';------------- ----------- --------- |名字|子系统|状态| ------------- ----------- --------- | dml_reads | DML |启用| | dml_inserts | DML |启用| | dml_deletes | DML |启用| | dml_updates | DML |启用| ------------- ----------- ---------
module_nameinnodb_monitor_enable
module_adaptive_hash(subsystem =adaptive_hash_index ) module_buffer(subsystem =缓冲区 ) module_buffer_page(subsystem =buffer_page_io ) module_compress(subsystem =压缩 ) module_ddl(subsystem =DDL ) module_dml(subsystem =DML ) module_file(subsystem =file_system ) module_ibuf_system(subsystem =change_buffer ) module_icp(subsystem =ICP ) module_index(subsystem =指数 ) module_innodb(subsystem =InnoDB ) module_lock(subsystem =锁具 ) module_log(subsystem =恢复 ) module_metadata(subsystem =元数据 ) module_os(subsystem =操作系统 ) module_purge(subsystem =净化 ) module_trx(subsystem =交易 )
INNODB_METRICS
创建一个简单的 InnoDB表 MySQL的> USE test;数据库changedmysql > CREATE TABLE t1 (c1 INT) ENGINE=INNODB;查询行,0行受影响(0.02秒) 使 dml_inserts计数器 MySQL的> SET GLOBAL innodb_monitor_enable = dml_inserts;查询行,0行受影响(0.01秒) 描述了 dml_inserts计数器中可以找到 评论 列的 INNODB_METRICS表 MySQL的> SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts";------------- ------------------------- |名字|评论| ------------- ------------------------- | dml_inserts |行数插入| ------------- ------------------------- 查询 INNODB_METRICS表为 _插入DML 计数器数据。因为没有DML操作已经完成,该计数器的值为零或零。这个 TIME_ENABLED和 _ elapsed时 值指示当计数器最后被启用,因为这时间有多少秒。 mysql>
SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts" \G*************************** 1. row *************************** NAME: dml_inserts SUBSYSTEM: dml COUNT: 0 MAX_COUNT: 0 MIN_COUNT: NULL AVG_COUNT: 0 COUNT_RESET: 0 MAX_COUNT_RESET: 0 MIN_COUNT_RESET: NULL AVG_COUNT_RESET: NULL TIME_ENABLED: 2014-12-04 14:18:28 TIME_DISABLED: NULL TIME_ELAPSED: 28 TIME_RESET: NULL STATUS: enabled TYPE: status_counter COMMENT: Number of rows inserted插入三行数据到表 mysql>
INSERT INTO t1 values(1);Query OK, 1 row affected (0.00 sec) mysql>INSERT INTO t1 values(2);Query OK, 1 row affected (0.00 sec) mysql>INSERT INTO t1 values(3);Query OK, 1 row affected (0.00 sec)查询 INNODB_METRICS对于再次表 _插入DML 计数器数据。一批反价值已经增加的包括 COUNT, 最大_计数 , AVG_COUNT,和 count_reset 。指的是 INNODB_METRICS对这些价值观的描述表定义。 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××1。××××××××××××××××××××××××一×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××:子系统名称:DML DML:_刀片3计数最大计数:3分钟_ _计数:计数:计数零平均_ 0.046153846153846156 _ _计数复位:复位:3max _ _ 3min _计数计数复位:复位:nullavg _ _零时间:2014年启用_—12—04 28 14 18队球队_ _残疾人:空运行时间:时间:_ 65复位启用状态:零状态_型:评论:插入的行数计数器 重置 dml_inserts计数器,和查询 INNODB_METRICS对于再次表 _插入DML 计数器数据。这个 %_RESET值进行了报道,如 count_reset 和 MAX_RESET,设置回零。这样的价值观 计数 , MAX_COUNT,和 【中文解释】 ,累计收集数据从时间计数器启用,不受复位。 mysql>
SET GLOBAL innodb_monitor_reset = dml_inserts;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1. row *************************** NAME: dml_inserts SUBSYSTEM: dml COUNT: 3 MAX_COUNT: 3 MIN_COUNT: NULL AVG_COUNT: 0.03529411764705882 COUNT_RESET: 0 MAX_COUNT_RESET: 0 MIN_COUNT_RESET: NULL AVG_COUNT_RESET: 0 TIME_ENABLED: 2014-12-04 14:18:28 TIME_DISABLED: NULL TIME_ELAPSED: 85 TIME_RESET: 2014-12-04 14:19:44 STATUS: enabled TYPE: status_counter COMMENT: Number of rows inserted重置所有计数器的值,必须先禁用计数器。禁用计数器集 STATUS价值 关闭 mysql>
SET GLOBAL innodb_monitor_disable = dml_inserts;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G*************************** 1. row *************************** NAME: dml_inserts SUBSYSTEM: dml COUNT: 3 MAX_COUNT: 3 MIN_COUNT: NULL AVG_COUNT: 0.030612244897959183 COUNT_RESET: 0 MAX_COUNT_RESET: 0 MIN_COUNT_RESET: NULL AVG_COUNT_RESET: 0 TIME_ENABLED: 2014-12-04 14:18:28 TIME_DISABLED: 2014-12-04 14:20:06 TIME_ELAPSED: 98 TIME_RESET: NULL STATUS: disabled TYPE: status_counter COMMENT: Number of rows inserted笔记 通配符匹配计数器和模块名支持。例如,而不是指定的全 dml_inserts计数器名称,可以指定 容器的_)% 。您还可以启用,禁用,或重置多个柜台或模块一次使用通配符匹配。例如,指定 dml_%启用、禁用,或重置开始所有计数器 容器的_ % 后反被禁用,您可以重置所有计数器值的使用 innodb_monitor_reset_all选项所有的值都设置为零或空。 MySQL的> SET GLOBAL innodb_monitor_reset_all = dml_inserts;查询好,为受影响的行(0.001秒)MySQL > SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME="dml_inserts"\G×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××1。××××××××××××××××××××××××一×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××:子系统名称:DML DML:_插入计数最大计数为0 _空:空_字数:字数:AVG _ _零计数计数复位:复位:0max _ _ nullmin _ _计数计数复位:复位:nullavg _ _启用时间:时间_空空空的时间运行时间的设置:_ _:空:空时_复位状态设置状态:评论:_型:插入的行数计数器
INNODB_TEMP_TABLE_INFOInnoDB
mysql> SHOW TABLES FROM INFORMATION_SCHEMA LIKE 'INNODB_TEMP%';
+---------------------------------------------+
| Tables_in_INFORMATION_SCHEMA (INNODB_TEMP%) |
+---------------------------------------------+
| INNODB_TEMP_TABLE_INFO |
+---------------------------------------------+
INNODB_TEMP_TABLE_INFO
创建一个简单的 InnoDB临时表: MySQL的> CREATE TEMPORARY TABLE t1 (c1 INT PRIMARY KEY) ENGINE=INNODB;查询 INNODB_TEMP_TABLE_INFO查看临时表的元数据 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G*************************** 1。行*************************** table_id:194名称:# sql7a79_1_0 n_cols:4空间:182 这个 TABLE_ID对于临时表的唯一标识符。这个 姓名 列显示系统生成的临时表的名称,它是以 “ # SQL “ 。列数( N_COLS)是4而不是1因为 InnoDB 总是有三个隐藏的表列( DB_ROW_ID, _ TRX _ DB ID ,和 DB_ROLL_PTR) 启动MySQL查询 INNODB_TEMP_TABLE_INFOMySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G返回空集因为 INNODB_TEMP_TABLE_INFO和它里面的数据不保留在服务器关闭磁盘。 创建一个新的临时表 mysql>
CREATE TEMPORARY TABLE t1 (c1 INT PRIMARY KEY) ENGINE=INNODB;查询 INNODB_TEMP_TABLE_INFO查看临时表的元数据 MySQL的> SELECT * FROM INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO\G*************************** 1。行*************************** table_id:196名称:# sql7b0e_1_0 n_cols:4空间:184 这个 SPACE我是新的因为它是动态生成的服务器上重新启动。
INFORMATION_SCHEMA.FILES
InnoDBINFORMATION_SCHEMA.FILES
INNODB_TABLESPACESINNODB_DATAFILES
InnoDBINFORMATION_SCHEMA.FILESINFORMATION_SCHEMA.FILES
mysql>SELECT FILE_ID, FILE_NAME, FILE_TYPE, TABLESPACE_NAME, FREE_EXTENTS,TOTAL_EXTENTS, EXTENT_SIZE, INITIAL_SIZE, MAXIMUM_SIZE, AUTOEXTEND_SIZE, DATA_FREE, STATUS ENGINEFROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME LIKE 'innodb_system' \G*************************** 1. row *************************** FILE_ID: 0 FILE_NAME: ./ibdata1 FILE_TYPE: TABLESPACE TABLESPACE_NAME: innodb_system FREE_EXTENTS: 0 TOTAL_EXTENTS: 12 EXTENT_SIZE: 1048576 INITIAL_SIZE: 12582912 MAXIMUM_SIZE: NULL AUTOEXTEND_SIZE: 67108864 DATA_FREE: 4194304 ENGINE: NORMAL
FILE_IDInnoDB
mysql>SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%.ibd%' ORDER BY FILE_ID;+---------+---------------------------------------+ | FILE_ID | FILE_NAME | +---------+---------------------------------------+ | 2 | ./mysql/plugin.ibd | | 3 | ./mysql/servers.ibd | | 4 | ./mysql/help_topic.ibd | | 5 | ./mysql/help_category.ibd | | 6 | ./mysql/help_relation.ibd | | 7 | ./mysql/help_keyword.ibd | | 8 | ./mysql/time_zone_name.ibd | | 9 | ./mysql/time_zone.ibd | | 10 | ./mysql/time_zone_transition.ibd | | 11 | ./mysql/time_zone_transition_type.ibd | | 12 | ./mysql/time_zone_leap_second.ibd | | 13 | ./mysql/innodb_table_stats.ibd | | 14 | ./mysql/innodb_index_stats.ibd | | 15 | ./mysql/slave_relay_log_info.ibd | | 16 | ./mysql/slave_master_info.ibd | | 17 | ./mysql/slave_worker_info.ibd | | 18 | ./mysql/gtid_executed.ibd | | 19 | ./mysql/server_cost.ibd | | 20 | ./mysql/engine_cost.ibd | | 21 | ./sys/sys_config.ibd | | 23 | ./test/t1.ibd | | 26 | /home/user/test/test/t2.ibd | +---------+---------------------------------------+
FILE_IDInnoDB
mysql>SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%ibtmp%';+---------+-----------+ | FILE_ID | FILE_NAME | +---------+-----------+ | 22 | ./ibtmp1 | +---------+-----------+
InnoDBFILE_IDInnoDB
MySQL的> SELECT FILE_ID, FILE_NAME FROM INFORMATION_SCHEMA.FILESWHERE FILE_NAME LIKE '%undo%';
InnoDB
InnoDB
InnoDB
你通常必须熟悉如何使用 性能模式特征 。例如,你应该知道如何使仪器和消费者,以及如何查询 performance_schema表中检索数据。一个介绍性的概述,看 25.1节,“性能模式快速启动” 你应该熟悉绩效模式的仪器,可用于 InnoDB。查看 InnoDB 相关的工具,你可以查询 setup_instruments对于包含仪器名称表 InnoDB ' mysql>
SELECT * FROM setup_instruments WHERE NAME LIKE '%innodb%';+-------------------------------------------------------+---------+-------+ | NAME | ENABLED | TIMED | +-------------------------------------------------------+---------+-------+ | wait/synch/mutex/innodb/commit_cond_mutex | NO | NO | | wait/synch/mutex/innodb/innobase_share_mutex | NO | NO | | wait/synch/mutex/innodb/autoinc_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_zip_mutex | NO | NO | | wait/synch/mutex/innodb/cache_last_read_mutex | NO | NO | | wait/synch/mutex/innodb/dict_foreign_err_mutex | NO | NO | | wait/synch/mutex/innodb/dict_sys_mutex | NO | NO | | wait/synch/mutex/innodb/recalc_pool_mutex | NO | NO | ... | wait/io/file/innodb/innodb_data_file | YES | YES | | wait/io/file/innodb/innodb_log_file | YES | YES | | wait/io/file/innodb/innodb_temp_file | YES | YES | | stage/innodb/alter table (end) | YES | YES | | stage/innodb/alter table (flush) | YES | YES | | stage/innodb/alter table (insert) | YES | YES | | stage/innodb/alter table (log apply index) | YES | YES | | stage/innodb/alter table (log apply table) | YES | YES | | stage/innodb/alter table (merge sort) | YES | YES | | stage/innodb/alter table (read PK and internal sort) | YES | YES | | stage/innodb/buffer pool load | YES | YES | | memory/innodb/buf_buf_pool | NO | NO | | memory/innodb/dict_stats_bg_recalc_pool_t | NO | NO | | memory/innodb/dict_stats_index_map_t | NO | NO | | memory/innodb/dict_stats_n_diff_on_level | NO | NO | | memory/innodb/other | NO | NO | | memory/innodb/row_log_buf | NO | NO | | memory/innodb/row_merge_sort | NO | NO | | memory/innodb/std | NO | NO | | memory/innodb/sync_debug_latches | NO | NO | | memory/innodb/trx_sys_t::rw_trx_ids | NO | NO | ... +-------------------------------------------------------+---------+-------+ 155 rows in set (0.00 sec)关于仪表的附加信息 InnoDB对象,你可以查询性能模式 实例表 ,为检测对象的附加信息。相关实例表 InnoDB包括: 笔记 Mutexes和读写锁相关的 InnoDB缓冲池是不包括在该覆盖;同样的输出 显示引擎InnoDB互斥 命令 例如,查看有关仪表 InnoDB文件对象的性能架构在执行文件I/O设备,你可能会发出以下查询: MySQL的> SELECT * FROM file_instances WHERE EVENT_NAME LIKE '%innodb%'\G* * * * * * * * * * * * * * * * * * * * * * * * * * * 1。行* * * * * * * * * * * * * * * * * * * * * * * * * * * _ /路径/文件名:8.0 - to / MySQL /日期/ ibdata1event _ name:/我/文件/等/ InnoDB数据_ InnoDB _ FileOpen _ count:3 * * * * * * * * * * * * * * * * * * * * * * * * * * * 2。行* * * * * * * * * * * * * * * * * * * * * * * * * * * _ /路径/文件名:8.0 - to / MySQL /日期/ IB _ logfile0event _ name:等我/ / / / _ InnoDB InnoDB日志文件_ FileOpen _ count 2:* * * * * * * * * * * * * * * * * * * * * * * * * * * 3。行* * * * * * * * * * * * * * * * * * * * * * * * * * * _ /路径/文件名:8.0 - to / MySQL /日期/ IB _ logfile1event _ name:等我/ / / / _ InnoDB InnoDB日志文件_ FileOpen _ count 2:* * * * * * * * * * * * * * * * * * * * * * * * * * * 4。行* * * * * * * * * * * * * * * * * * * * * * * * * * * _ /路径/文件名:8.0 - to / MySQL /发动机/ MySQL /日期等_ cost.ibdevent _ name:文件/ / / /我InnoDB数据_ InnoDB _ FileOpen _ count:3。 你应该熟悉 performance_schema表存储 InnoDB 事件数据。表相关 InnoDB相关的事件包括: 这个 等待事件 表店,which等事件。 实习 商店的事件,日期for which InnoDBALTER TABLE和缓冲池负荷操作。有关更多信息,参见 第15.15.1,“监测表进步InnoDB表的使用性能模式” ,和 监测缓冲池负荷进步使用性能模式
如果你只是感兴趣 InnoDB相关的对象,使用条款 在event_name像''%1 InnoDB % 或 WHERE NAME LIKE '%innodb%'当(as required)查询这些表。
ALTER TABLE
ALTER TABLEWORK_ESTIMATEDALTER TABLEALTER TABLEALTER TABLEWORK_ESTIMATEDALTER TABLE
ALTER TABLE
stage/innodb/alter table (read PK and internal sort)这个阶段是活动时: ALTER TABLE在阅读的关键阶段。它开始 WORK_COMPLETED=0和 WORK_ESTIMATED将估计的页数主键。当阶段完成, work_estimated 更新主键中的页面的实际数量。 stage/innodb/alter table (merge sort):这一阶段是每个指标反复加 ALTER TABLE运营 stage/innodb/alter table (insert):这一阶段是每个指标反复加 ALTER TABLE运营 stage/innodb/alter table (log apply index):这个阶段包括DML日志生成应用程序时 ALTER TABLE运行 stage/innodb/alter table (flush)在这一阶段开始, work_estimated 是一个更准确的估计的基础上更新,刷新列表的长度。 stage/innodb/alter table (log apply table)这一阶段包括:产生并发DML测井中的应用 ALTER TABLE运行。这个阶段的持续时间取决于表的变化程度。如果没有并行DML运行表相是瞬间。 stage/innodb/alter table (end)任何剩余的工作:包括冲洗阶段后出现的,如重新执行DML,桌上同时 ALTER TABLE运行
InnoDBALTER
TABLE
修改表的使用性能模式监测实例
stage/innodb/alter table%ALTER TABLE
使 stage/innodb/alter%仪器 MySQL的> UPDATE setup_instruments SET ENABLED = 'YES' WHERE NAME LIKE 'stage/innodb/alter%';查询行,7行受影响(0秒)的行匹配:7改变:7警告:0 使舞台事件消费表,其中包括 events_stages_current, events_stages_history,和 events_stages_history_longMySQL的> UPDATE setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%stages%';查询行,3行受影响(0秒)的行匹配:3改变:3警告:0 运行一个 ALTER TABLE运营在这个例子中,一个 中_ name 列添加到员工的样本数据库的员工表。 mysql>
ALTER TABLE employees.employees ADD COLUMN middle_name varchar(14) AFTER first_name;Query OK, 0 rows affected (9.27 sec) Records: 0 Duplicates: 0 Warnings: 0检查的进展 ALTER TABLE通过查询性能模式运行 events_stages_current表。在舞台的事件,这取决于shown differs ALTER TABLE阶段是目前正在进行中。这个 work_completed 列显示完成工作。这个 WORK_ESTIMATED柱提供剩余工作的估计。 MySQL的> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM events_stages_current;------------------------------------------------------ ---------------- ---------------- | event_name | work_completed | work_estimated | ------------------------------------------------------ ---------------- ---------------- |阶段/ InnoDB /修改表(读PK和内部排序)| 280 | 1245 | ------------------------------------------------------ ---------------- ----------------一行集(0.01秒) 这个 events_stages_current表返回空集如果 ALTER TABLE操作完成。在这种情况下,你可以检查 events_stages_history表查看已完成的操作事件数据。例如: MySQL的> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM events_stages_history;------------------------------------------------------ ---------------- ---------------- | event_name | work_completed | work_estimated | ------------------------------------------------------ ---------------- ---------------- |阶段/ InnoDB /修改表(读PK和内部排序)| 886 | 1213 | |阶段/ InnoDB /修改表(冲洗)| 1213 | 1213 | |阶段/ InnoDB /修改表(日志申请表)| 1597 | 1597 | |阶段/ InnoDB /修改表(结束)| 1597 | 1597 | |阶段/ InnoDB /修改表(日志申请表)| 1981 | 1981 | ------------------------------------------------------ ---------------- ---------------- 5行集(0秒) 如上图所示,该 WORK_ESTIMATED值的调整是在 修改表 处理.估计工作的初始阶段完成后是1213。什么时候 ALTER TABLE处理完成, work_estimated 将实际值,这是1981。
InnoDB
InnoDB
要查看可用的 InnoDB互斥等工具,查询的性能模式 setup_instruments表全部 InnoDB 互斥等工具默认是关闭的。 mysql>
SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb%';+---------------------------------------------------------+---------+-------+ | NAME | ENABLED | TIMED | +---------------------------------------------------------+---------+-------+ | wait/synch/mutex/innodb/commit_cond_mutex | NO | NO | | wait/synch/mutex/innodb/innobase_share_mutex | NO | NO | | wait/synch/mutex/innodb/autoinc_mutex | NO | NO | | wait/synch/mutex/innodb/autoinc_persisted_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_flush_state_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_LRU_list_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_free_list_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_zip_free_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_zip_hash_mutex | NO | NO | | wait/synch/mutex/innodb/buf_pool_zip_mutex | NO | NO | | wait/synch/mutex/innodb/cache_last_read_mutex | NO | NO | | wait/synch/mutex/innodb/dict_foreign_err_mutex | NO | NO | | wait/synch/mutex/innodb/dict_persist_dirty_tables_mutex | NO | NO | | wait/synch/mutex/innodb/dict_sys_mutex | NO | NO | | wait/synch/mutex/innodb/recalc_pool_mutex | NO | NO | | wait/synch/mutex/innodb/fil_system_mutex | NO | NO | | wait/synch/mutex/innodb/flush_list_mutex | NO | NO | | wait/synch/mutex/innodb/fts_bg_threads_mutex | NO | NO | | wait/synch/mutex/innodb/fts_delete_mutex | NO | NO | | wait/synch/mutex/innodb/fts_optimize_mutex | NO | NO | | wait/synch/mutex/innodb/fts_doc_id_mutex | NO | NO | | wait/synch/mutex/innodb/log_flush_order_mutex | NO | NO | | wait/synch/mutex/innodb/hash_table_mutex | NO | NO | | wait/synch/mutex/innodb/ibuf_bitmap_mutex | NO | NO | | wait/synch/mutex/innodb/ibuf_mutex | NO | NO | | wait/synch/mutex/innodb/ibuf_pessimistic_insert_mutex | NO | NO | | wait/synch/mutex/innodb/log_sys_mutex | NO | NO | | wait/synch/mutex/innodb/log_sys_write_mutex | NO | NO | | wait/synch/mutex/innodb/mutex_list_mutex | NO | NO | | wait/synch/mutex/innodb/page_zip_stat_per_index_mutex | NO | NO | | wait/synch/mutex/innodb/purge_sys_pq_mutex | NO | NO | | wait/synch/mutex/innodb/recv_sys_mutex | NO | NO | | wait/synch/mutex/innodb/recv_writer_mutex | NO | NO | | wait/synch/mutex/innodb/redo_rseg_mutex | NO | NO | | wait/synch/mutex/innodb/noredo_rseg_mutex | NO | NO | | wait/synch/mutex/innodb/rw_lock_list_mutex | NO | NO | | wait/synch/mutex/innodb/rw_lock_mutex | NO | NO | | wait/synch/mutex/innodb/srv_dict_tmpfile_mutex | NO | NO | | wait/synch/mutex/innodb/srv_innodb_monitor_mutex | NO | NO | | wait/synch/mutex/innodb/srv_misc_tmpfile_mutex | NO | NO | | wait/synch/mutex/innodb/srv_monitor_file_mutex | NO | NO | | wait/synch/mutex/innodb/buf_dblwr_mutex | NO | NO | | wait/synch/mutex/innodb/trx_undo_mutex | NO | NO | | wait/synch/mutex/innodb/trx_pool_mutex | NO | NO | | wait/synch/mutex/innodb/trx_pool_manager_mutex | NO | NO | | wait/synch/mutex/innodb/srv_sys_mutex | NO | NO | | wait/synch/mutex/innodb/lock_mutex | NO | NO | | wait/synch/mutex/innodb/lock_wait_mutex | NO | NO | | wait/synch/mutex/innodb/trx_mutex | NO | NO | | wait/synch/mutex/innodb/srv_threads_mutex | NO | NO | | wait/synch/mutex/innodb/rtr_active_mutex | NO | NO | | wait/synch/mutex/innodb/rtr_match_mutex | NO | NO | | wait/synch/mutex/innodb/rtr_path_mutex | NO | NO | | wait/synch/mutex/innodb/rtr_ssn_mutex | NO | NO | | wait/synch/mutex/innodb/trx_sys_mutex | NO | NO | | wait/synch/mutex/innodb/zip_pad_mutex | NO | NO | | wait/synch/mutex/innodb/master_key_id_mutex | NO | NO | +---------------------------------------------------------+---------+-------+一些 InnoDB互斥的实例在服务器启动时创建,只有仪表如果相关的仪器也在服务器启动时启用。确保所有 InnoDB 互斥情况后启用,添加以下 performance-schema-instrument统治你的MySQL的配置文件: performance-schema-instrument='wait/synch/mutex/innodb/%=ON'
如果你不需要等待事件的所有数据 InnoDB互斥锁,你可以通过添加禁用特定的仪器 仪器性能模式 规则你的MySQL的配置文件。例如,禁用 InnoDB互斥等全文搜索相关事件的工具,添加以下规则: performance-schema-instrument='wait/synch/mutex/innodb/fts%=OFF'
笔记 如较长的前缀 wait/synch/mutex/innodb/fts%优先于较短的前缀,如规则 等待/同步/互斥/会/ % 在加入 performance-schema-instrument规则配置文件,重新启动服务器。所有的 InnoDB 互斥除了全文搜索相关的启用。验证查询 setup_instruments表这个 启用 和 TIMED柱应设置为 对 的工具,你可以 mysql>
SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb%';+-------------------------------------------------------+---------+-------+ | NAME | ENABLED | TIMED | +-------------------------------------------------------+---------+-------+ | wait/synch/mutex/innodb/commit_cond_mutex | YES | YES | | wait/synch/mutex/innodb/innobase_share_mutex | YES | YES | | wait/synch/mutex/innodb/autoinc_mutex | YES | YES | ... | wait/synch/mutex/innodb/master_key_id_mutex | YES | YES | +-------------------------------------------------------+---------+-------+ 49 rows in set (0.00 sec)使消费者通过更新等待事件 setup_consumers表等待事件消费者默认是关闭的。 MySQL的> UPDATE performance_schema.setup_consumers SET enabled = 'YES'WHERE name like 'events_waits%';查询行,3行受影响(0秒)的行匹配:3改变:3警告:0 您可以验证等待事件消费者的查询 setup_consumers表这个 events_waits_current, events_waits_history,和 events_waits_history_long消费者应该启用 MySQL的> SELECT * FROM performance_schema.setup_consumers;---------------------------------- --------- |名字|启用| ---------------------------------- --------- | events_stages_current |没有| | events_stages_history |没有| | events_stages_history_long |没有| | events_statements_current |是| | events_statements_history |是| | events_statements_history_long |没有| | events_transactions_current |是| | events_transactions_history |是| | events_transactions_history_long |没有| | events_waits_current |是| | events_waits_history |是| | events_waits_history_long |是| | global_instrumentation |是| | thread_instrumentation |是| | statements_digest |是| ---------------------------------- --------- 15行集(0秒) 一次仪表和消费者都启用,运行的工作量要监视。在这个例子中,该 mysqlslap 负载模拟客户端是用于模拟的工作量。 shell>
./mysqlslap --auto-generate-sql --concurrency=100 --iterations=10--number-of-queries=1000 --number-char-cols=6 --number-int-cols=6;查询等待事件数据。在这个例子中,等待事件数据是通过查询 events_waits_summary_global_by_event_name表中数据集 events_waits_current, events_waits_history,和 events_waits_history_long表数据是通过总结(事件名称 事件_ name ),这是产生事件的仪器名称。汇总数据包括: COUNT_STAR总结等事件的数量 SUM_TIMER_WAIT在总结时间等待事件的总等待时间。 MIN_TIMER_WAIT在总结时间等待事件的最小等待时间。 AVG_TIMER_WAIT在总结时间的等待事件的平均等待时间。 MAX_TIMER_WAIT最大等待的时间等待事件的时间了。
下面的查询返回的仪器名称( EVENT_NAME), the number of wait events ( count_star ),和总的等待时间,仪器的事件( SUM_TIMER_WAIT)。因为等待时间在皮秒(万亿分之一秒)默认情况下,等待时间除以1000000000显示等待时间。数据是按降序排列,通过总结等事件的数量( count_star )。你可以调整 ORDER BY条款的总等待时间顺序的数据。 MySQL的> SELECT EVENT_NAME, COUNT_STAR, SUM_TIMER_WAIT/1000000000 SUM_TIMER_WAIT_MSFROM performance_schema.events_waits_summary_global_by_event_nameWHERE SUM_TIMER_WAIT > 0 AND EVENT_NAME LIKE 'wait/synch/mutex/innodb/%'ORDER BY COUNT_STAR DESC;--------------------------------------------------------- ------------ ------------------- | event_name | count_star | sum_timer_wait_ms | --------------------------------------------------------- ------------ -------------------等待/同步/互斥/ | InnoDB / trx_mutex | 201111 | 23.4719 |等待/同步/互斥/ | InnoDB / fil_system_mutex | 62244 | 9.6426 |等待/同步/互斥/ | InnoDB / redo_rseg_mutex | 48238 | 3.1135 | |等待/同步/互斥/ / log_sys_mutex InnoDB | 46113 | 2.0434 |等待/同步/互斥/ | InnoDB / trx_sys_mutex | 35134 | 1068.1588 |等待/同步/互斥/ | InnoDB / lock_mutex | 34872 | 1039.2589 |等待/同步/互斥/ | InnoDB / log_sys_write_mutex | 17805 | 1526.0490 | | /同步/互斥/等/ dict_sys_mutex InnoDB | 14912 | 1606.7348 | |等待/同步/ / / trx_undo_mutex InnoDB互斥| 10634 | 1.1424 |等待/同步/互斥/ | InnoDB / rw_lock_list_mutex | 8538 | 0.1960 |等待/同步/互斥/ | InnoDB / buf_pool_free_list_mutex | 5961 |传代后|等待/同步/互斥/ | InnoDB / trx_pool_mutex |四千八百八十五| 8821.7496 | | /同步/互斥/ InnoDB等/ buf_pool_lru_list_mutex | 4364 | 0.2077 |等待/同步/互斥/ | InnoDB / innobase_share_mutex |吗| 0.2650 |等待/同步/互斥/ | InnoDB / flush_list_mutex | 3178 | 0.2349 |等待/同步/互斥/ | InnoDB / trx_pool_manager_mutex |以下| 0.1310 |等待/同步/互斥/ | InnoDB / buf_pool_flush_state_mutex | 1318 | 0.2161 |等待/同步/互斥/ | InnoDB / log_flush_order_mutex | 1250 | 0.0893 |等待/同步/互斥/ | InnoDB / buf_dblwr_mutex | 951 | 0.0918 | | /同步/互斥/创新等670 | 0.0942分贝/ recalc_pool_mutex | |等待/同步/互斥/ | InnoDB / dict_persist_dirty_tables_mutex | 345 | 0.0414 |等待/同步/互斥/ | InnoDB / lock_wait_mutex | 303 | 0.1565 |等待/同步/互斥/ | InnoDB / autoinc_mutex | 196 | 0.0213 |等待/同步/互斥/ | InnoDB / autoinc_persisted_mutex | 196 | 0.0175 |等待/同步/互斥/ | InnoDB / purge_sys_pq_mutex | 117 | 0.0308 |等待/同步/互斥/ | InnoDB / srv_sys_mutex | 94 | 0.0077 |等待/同步/互斥/ | InnoDB / ibuf_mutex | 22 | 0.0086 |等待/同步/互斥/ | InnoDB / recv_sys_mutex | 12 | 0.0008 | |等待/同步/互斥/会/ srv_innodb_monitor_mutex | 4 | 0.0009 | | /同步/互斥/等/ recv_writer_mutex InnoDB 笔记 前面的结果集包含等待事件数据的启动过程中产生的。排除这些数据,你可以使用 events_waits_summary_global_by_event_name启动后,运行您的工作量之前立即表。然而,截断操作本身可能会产生一个微不足道的等待事件数据。 MySQL的> TRUNCATE performance_schema.events_waits_summary_global_by_event_name;
InnoDB
InnoDB
标准 InnoDB监视器显示下列信息: 由主线程的工作背景 信号量等待 有关数据的最近的外交重点和死锁错误 锁等待交易 表格和记录锁的活动事务举行 等待I/O操作和相关统计 插入缓冲和自适应哈希索引统计 重做日志数据 缓冲池数据 行操作数据
这个 InnoDB指纹锁锁监视器附加信息作为标准的一部分 InnoDB 监视器输出
InnoDBstderrstderr
stderr--console
stderr
InnoDBSHOW ENGINE INNODB
STATUSpidpidinnodb_status.pidinnodb-status-file
InnoDB
InnoDB
InnoDB
=====================================2014-10-16 18:37:29 0x7fc2a95c1700 INNODB MONITOR OUTPUT=====================================
InnoDB
innodb_status_outputinnodb_status_output_locksInnoDB
PROCESS
使标准InnoDB监视器
InnoDBinnodb_status_output
SET GLOBAL innodb_status_output=ON;
InnoDBinnodb_status_output
innodb_status_output
获取标准InnoDB监视器输出的需求
InnoDBSHOW ENGINE
INNODB STATUS\G
MySQL的> SHOW ENGINE INNODB STATUS\G
SHOW ENGINE INNODB
STATUSInnoDB
使InnoDB锁监视器
InnoDBInnoDBInnoDB
InnoDBinnodb_status_output_locksInnoDBInnoDB
SET GLOBAL innodb_status_output=ON;SET GLOBAL innodb_status_output_locks=ON;
InnoDBinnodb_status_output_locksinnodb_status_outputInnoDB
innodb_status_outputinnodb_status_output_locks
InnoDBSHOW ENGINE INNODB
STATUSinnodb_status_output_locks
SHOW ENGINE INNODB
STATUS
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2018-04-12 15:14:08 0x7f971c063700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 4 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 15 srv_active, 0 srv_shutdown, 1122 srv_idle
srv_master_thread log flush and writes: 0
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 24
OS WAIT ARRAY INFO: signal count 24
RW-shared spins 4, rounds 8, OS waits 4
RW-excl spins 2, rounds 60, OS waits 2
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 2.00 RW-shared, 30.00 RW-excl, 0.00 RW-sx
------------------------
LATEST FOREIGN KEY ERROR
------------------------
2018-04-12 14:57:24 0x7f97a9c91700 Transaction:
TRANSACTION 7717, ACTIVE 0 sec inserting
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 3
MySQL thread id 8, OS thread handle 140289365317376, query id 14 localhost root update
INSERT INTO child VALUES (NULL, 1), (NULL, 2), (NULL, 3), (NULL, 4), (NULL, 5), (NULL, 6)
Foreign key constraint fails for table `test`.`child`:
,
CONSTRAINT `child_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`id`) ON DELETE
CASCADE ON UPDATE CASCADE
Trying to add in child table, in index par_ind tuple:
DATA TUPLE: 2 fields;
0: len 4; hex 80000003; asc ;;
1: len 4; hex 80000003; asc ;;
But in parent table `test`.`parent`, in index PRIMARY,
the closest match we can find is record:
PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 80000004; asc ;;
1: len 6; hex 000000001e19; asc ;;
2: len 7; hex 81000001110137; asc 7;;
------------
TRANSACTIONS
------------
Trx id counter 7748
Purge done for trx's n:o < 7747 undo n:o < 0 state: running but idle
History list length 19
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421764459790000, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 7747, ACTIVE 23 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 9, OS thread handle 140286987249408, query id 51 localhost root updating
DELETE FROM t WHERE i = 1
------- TRX HAS BEEN WAITING 23 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 4 page no 4 n bits 72 index GEN_CLUST_INDEX of table `test`.`t`
trx id 7747 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000202; asc ;;
1: len 6; hex 000000001e41; asc A;;
2: len 7; hex 820000008b0110; asc ;;
3: len 4; hex 80000001; asc ;;
------------------
TABLE LOCK table `test`.`t` trx id 7747 lock mode IX
RECORD LOCKS space id 4 page no 4 n bits 72 index GEN_CLUST_INDEX of table `test`.`t`
trx id 7747 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000202; asc ;;
1: len 6; hex 000000001e41; asc A;;
2: len 7; hex 820000008b0110; asc ;;
3: len 4; hex 80000001; asc ;;
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (read thread)
I/O thread 4 state: waiting for i/o request (read thread)
I/O thread 5 state: waiting for i/o request (read thread)
I/O thread 6 state: waiting for i/o request (write thread)
I/O thread 7 state: waiting for i/o request (write thread)
I/O thread 8 state: waiting for i/o request (write thread)
I/O thread 9 state: waiting for i/o request (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
833 OS file reads, 605 OS file writes, 208 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 1 buffer(s)
Hash table size 553253, node heap has 3 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 19643450
Log buffer assigned up to 19643450
Log buffer completed up to 19643450
Log written up to 19643450
Log flushed up to 19643450
Added dirty pages up to 19643450
Pages flushed up to 19643450
Last checkpoint at 19643450
129 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 409606
Buffer pool size 131072
Free buffers 130095
Database pages 973
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 810, created 163, written 404
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 973, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
----------------------
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 65536
Free buffers 65043
Database pages 491
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 411, created 80, written 210
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 491, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
---BUFFER POOL 1
Buffer pool size 65536
Free buffers 65052
Database pages 482
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 399, created 83, written 194
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 482, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=5772, Main thread ID=140286437054208 , state=sleeping
Number of rows inserted 57, updated 354, deleted 4, read 4421
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
Status本节显示时间戳,班长的名字,和秒数,每秒平均数的基础上。秒数是时间的当前时间和最后一次之间 InnoDB监视器输出打印 BACKGROUND THREAD这个 srv_master_thread线显示的主要后台线程完成工作。 SEMAPHORES本节介绍线程等待一个信号量和统计多少次线程需要旋转或互斥信号量或RW锁等待。大量等待信号量的线程可能会导致磁盘I/O,或争用问题 InnoDB。竞争可能是由于查询或问题的并行操作系统的线程调度的重。设置 innodb_thread_concurrency系统变量小于默认值可能有助于在这种情况下。这个 旋轮每等 线显示自旋锁发每OS数量等待互斥。 互斥度量报告 SHOW ENGINE INNODB MUTEXLATEST FOREIGN KEY ERROR本节提供有关最新的外键约束的错误信息。它是不存在的如果没有发生这样的错误。内容包括失败以及失败和参考和引用表的约束信息的声明。 LATEST DETECTED DEADLOCK本节提供有关最新的死锁信息。它是不存在的如果没有发生死锁。内容显示,交易涉及的语句,每个试图执行,他们需要的锁,而交易 InnoDB决定反击打破僵局。锁模式报告的这部分解释 第15.5.1,“InnoDB锁定” TRANSACTIONS如果这段报道锁等候您的应用程序可能有锁争用。输出也可以帮助跟踪事务死锁的原因。 FILE I/O本节提供了有关线程 InnoDB用于执行各种类型的I / O的这些最初的几个致力于一般 InnoDB 处理.内容也显示信息等待I/O操作和统计的I/O性能。 这些线程数的控制 innodb_read_io_threads和 innodb_write_io_threads参数.看到 15.13节,“InnoDB启动选项和系统变量” INSERT BUFFER AND ADAPTIVE HASH INDEX本节说明的状况 InnoDB插入缓冲(也被称为 变化的缓冲 )和自适应哈希索引 LOG本节显示有关 InnoDB日志内容包括当前日志序列号,记录被刷新到磁盘的有多远,和在哪个位置 InnoDB 最后拿了一点。(见 第15.11.3,“InnoDB检查站” 。)的部分也显示信息之前写的写性能统计。 BUFFER POOL AND MEMORY这部分给你读写页面的统计。你可以从这些数字有多少数据文件I/O操作查询目前所做的计算。 对缓冲池的统计描述,看 第15.6.3.9,“监控缓冲池使用InnoDB监控标准” 。对缓冲池的操作的更多信息,参见 第15.6.3.1,“InnoDB缓冲池” ROW OPERATIONS本节说明主线程做,包括数量和速率为每种类型的行运算。
InnoDB
有关备份的信息技术应用于 InnoDB,看到 第15.17.1,“InnoDB Backup” 在恢复时间点的信息,从磁盘故障或损坏的恢复,以及如何 InnoDB执行崩溃恢复,看 第15.17.2,“InnoDB恢复”
InnoDB
InnoDB
热备份
InnoDBInnoDB
冷备份
InnoDB
执行 缓慢关闭 在MySQL服务器,确保没有错误。 复制所有 InnoDB数据文件( ibdata 文件和 .ibd文件)到一个安全的地方。 复制所有 InnoDB日志文件( ib_logfile 文件)到一个安全的地方。 复制你的 my.cnf配置文件到一个安全的地方。
逻辑备份使用mysqldump
--single-transaction
InnoDB
InnoDB
InnoDB
CHECK TABLECHECK
TABLE
InnoDB
InnoDB
InnoDB: The log sequence number 664050266 in the system tablespace does not match the log sequence number 685111586 in the ib_logfiles! InnoDB: Database was not shutdown normally! InnoDB: Starting crash recovery. InnoDB: Using 'tablespaces.open.2' max LSN: 664075228 InnoDB: Doing recovery: scanned up to log sequence number 690354176 InnoDB: Doing recovery: scanned up to log sequence number 695597056 InnoDB: Doing recovery: scanned up to log sequence number 700839936 InnoDB: Doing recovery: scanned up to log sequence number 706082816 InnoDB: Doing recovery: scanned up to log sequence number 711325696 InnoDB: Doing recovery: scanned up to log sequence number 713458156 InnoDB: Applying a batch of 1467 redo log records ... InnoDB: 10% InnoDB: 20% InnoDB: 30% InnoDB: 40% InnoDB: 50% InnoDB: 60% InnoDB: 70% InnoDB: 80% InnoDB: 90% InnoDB: 100% InnoDB: Apply batch completed! InnoDB: 1 transaction(s) which must be rolled back or cleaned up in total 561887 row operations to undo InnoDB: Trx id counter is 4096 ... InnoDB: 8.0.1 started; log sequence number 713458156 InnoDB: Waiting for purge to start InnoDB: Starting in background the rollback of uncommitted transactions InnoDB: Rolling back trx with id 3596, 561887 rows to undo ... ./mysqld: ready for connections....
InnoDB
表空间的发现 表空间的发现过程 InnoDB用于识别的表空间需要重做日志应用。看到 发现在崩溃恢复表空间 重做日志 应用 重做日志应用程序进行初始化时,在接受任何连接。如果所有的改变都是红的 缓冲池 到 表空间 ( ibdata*和 鸡传染性法氏囊病* 文件)在关机或死机时,重做日志应用跳过。 InnoDB也跳过重做日志应用程序如果重做日志文件丢失时。 当前最大的自动增加计数器的值写入到重做日志每个时间价值的变化,这使得它的安全。在恢复过程中, InnoDB扫描日志收集计数器值的变化和应用改变到内存中的表对象。 为更多的信息关于如何 InnoDB处理自动增量值,见 第15.8.1.5,”auto_increment InnoDB”处理 ,和 InnoDB auto_increment计数器初始化 当遇到索引树的腐败, InnoDB写一个腐败标志的重做日志,使腐败标志碰撞安全。 InnoDB 还写在记忆腐败标志数据引擎系统表在每个关卡的私人。在恢复过程中, InnoDB腐败的旗帜读取位置和合并结果标记在内存中的表和索引对象的腐败之前。 删除重做日志加快复苏是不推荐的,即使一些数据丢失是可以接受的。删除重做日志应该只能算是一个干净的关闭后,用 innodb_fast_shutdown设置 零 或 1
不完整的交易是任何活跃在碰撞的时候或交易 快速关机 。它需要回滚未完成事务的时间可以是三或四倍时间的交易活跃量之前就被中断,根据服务器的负载。 取消正在回滚事务你不能。在极端情况下,当收回交易预计将需要很长的时间,它可以更快的开始 InnoDB一个 innodb_force_recovery设置 三 或更大。看到 第15.20.2,迫使InnoDB恢复” 变化的缓冲 合并 应用从改变缓冲区的变化(部分的 系统表空间 对辅助索引页),作为索引页读取到缓冲池。 删除删除标记的记录,不再是交易活跃可见。
InnoDBXA
PREPARE
InnoDB
InnoDB
InnoDB
innodb_data_home_dirinnodb_data_home_dirdatadir
tablespaces.open.1
innodb_scan_directories
innodb_scan_directories
innodb_scan_directories
mysqld --innodb-scan-directories="directory_path_1;directory_path_2"
[mysqld] innodb_scan_directories="directory_path_1;directory_path_2"
innodb_scan_directories
InnoDB: Directories to scan 'directory_path_1;directory_path_2' InnoDB: Scanning 'directory_path_1' InnoDB: Scanning 'directory_path_2' InnoDB: Found 10 '.ibd' file(s)
InnoDBInnoDB
InnoDBInnoDBCREATE TABLE
CREATE TABLE fc1 ( i INT PRIMARY KEY, j INT) ENGINE = InnoDB;CREATE TABLE fc2 ( m INT PRIMARY KEY, n INT, FOREIGN KEY ni (n) REFERENCES fc1 (i) ON DELETE CASCADE) ENGINE = InnoDB;
InnoDBFOREIGN KEY
硕士 INSERT INTO fc1 VALUES (1, 1), (2, 2);查询行,2行受影响(0.09秒)记录:2份:0警告:0master > INSERT INTO fc2 VALUES (1, 1), (2, 2), (3, 1);查询好,三行受影响(0.19秒)记录:三副本:警告:0 0
fc1
master>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) master>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec) slave>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) slave>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec)
DELETE
硕士 DELETE FROM fc1 WHERE i=1;查询行,1行的影响(0.09秒)
fc2
硕士 SELECT * FROM fc2;--- | M | N | --- | 2 | 2 | --- 1行集(0秒)
DELETEfc2
slave> SELECT * FROM fc2;
+---+---+
| m | n |
+---+---+
| 1 | 1 |
| 3 | 1 |
| 2 | 2 |
+---+---+
3 rows in set (0.00 sec)
InnoDB
InnoDBdaemon_memcachedInnoDBgetincr
InnoDBaddincrInnoDB
daemon_memcached
直接进入 InnoDB存储引擎避免分析和规划架空SQL。 运行 memcached 在同一个进程空间为MySQL服务器避免传递请求返回的网络开销和四。 数据使用 memcached 协议透明地写入 InnoDB表,而无需通过MySQL的SQL层。你可以控制写入频率达到更高性能的非关键数据更新时的原。 要求通过数据 memcached 协议透明地查询从 InnoDB表,而无需通过MySQL的SQL层。 随后对相同数据的请求是从 InnoDB缓冲池。缓冲池的内存缓存处理。你可以调整性能的数据密集型的操作使用 InnoDB 配置选项 数据是非结构化或结构化,根据应用程序的类型。你可以创建一个新的数据表,或使用现有的表。 InnoDB可以处理的合成与分解多个列的值到一个单一的 memcached 项目的价值,减少字符串解析和连接在你的应用程序所需的。例如,你可以存储字符串值 2|4|6|8在 memcached 高速缓存,并有 InnoDB基于分隔符的值分割,然后将结果存储在四个数字列。 内存和磁盘之间的转换是自动处理,简化了应用程序的逻辑。 数据存储在一个MySQL数据库来防止死机,停电,和腐败。 你可以访问底层 InnoDB表通过SQL报告、分析、即席查询、批量加载、多步交易计算,设置操作如并集和交集,等操作,适合于SQL的表达能力和灵活性。 你可以确保高可用性应用 daemon_memcached插件上 主服务器 在使用MySQL复制组合。
整合 memcached MySQL提供了一种方法,在内存中的数据持久性,所以你可以使用它的数据更重要的种类。你可以使用更多的 add, 增加 类似的写操作,并在你的应用程序而不用担心数据会丢失。你可以停止和启动 memcached 失去了缓存数据更新服务器。为了防止意外中断,你可以利用 InnoDB崩溃恢复、复制和备份功能。 的方式 InnoDB不快 主键 查找是一种天然的适合 memcached 一项查询。直接的、低层次的数据库访问路径使用的 daemon_memcached插件是更有效率的关键值的查找比等价的SQL查询。 序列化的特点 memcached ,它可以将复杂的数据结构,二进制文件,或甚至代码块storeable字符串,提供一个简单的方法来获得这些对象到数据库。 因为你可以通过SQL访问底层数据,您可以生成报告,搜索或更新多个键,呼叫等功能 AVG()和 max() 打开(放) memcached 数据所有这些操作都是昂贵或复杂的使用 memcached 本身 你不需要手动加载数据到 memcached 在启动。作为特定的键是由一个应用程序的请求,从数据库中检索的值是自动缓存在内存使用 InnoDB缓冲池 因为 memcached 消耗相对较少的CPU和内存占用是容易控制的,它可以运行在一个舒适的MySQL实例在同一系统。 因为数据的一致性是由用于定期执行的机制 InnoDB表,您不必担心陈旧 memcached 数据或回退逻辑在缺少关键案例数据库查询。
InnoDBInnoDB
daemon_memcached
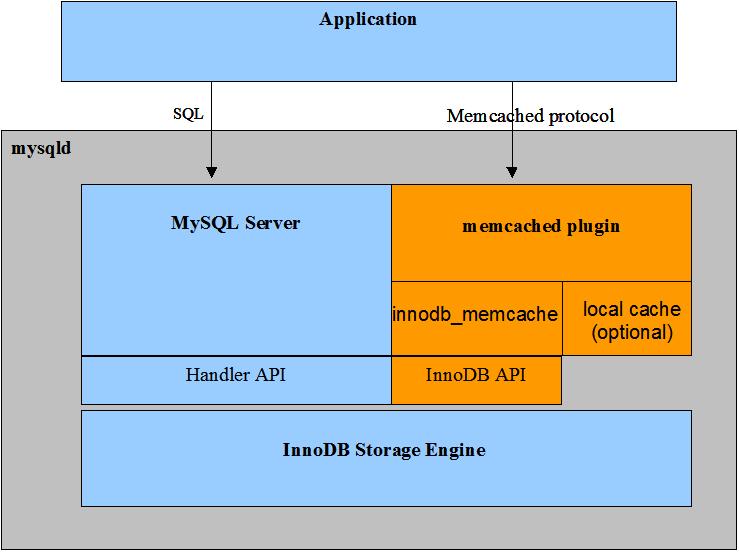
daemon_memcached
memcached 作为一个守护进程插件 mysqld 。两 mysqld 和 memcached 运行在相同的进程空间,具有非常低的延迟访问数据。 直接访问 InnoDB表,绕过SQL解析器,优化器,甚至处理API层。 标准 memcached 协议,包括协议的文本和二进制协议。这个 daemon_memcached插件通过所有55兼容性测试的 memcapable 命令 多柱支撑。你可以映射多个列进 “ 价值 “ 的键/值存储的一部分,与列值由用户指定的分隔符分隔。 默认情况下,该 memcached 协议是用来读写数据直接 InnoDB,让MySQL管理内存使用 InnoDB 缓冲池 。默认设置是一个组合的高可靠性、数据库应用最少的惊喜。例如,默认设置,避免在数据库端未提交的数据,或过期的数据返回 memcached get请求 高级用户可以配置系统作为传统 memcached 服务器,只有在缓存的所有数据 memcached 发动机(内存缓存),或结合使用的 “ memcached 引擎 “ (内存缓存)和 InnoDBmemcached 发动机( InnoDB作为后端的持久性存储)。
如何控制往往数据之间来回传送 InnoDB和 memcached 通过作战 innodb_api_bk_commit_interval, daemon_memcached_r_batch_size,和 daemon_memcached_w_batch_size配置选项。批量大小选项默认为最大的可靠性值1。 指定的能力 memcached 选择通过 daemon_memcached_option配置参数。例如,你可以改变端口 memcached 听,减少同时连接的最大数目,换一个键/值对的最大内存大小,或启用调试的错误日志消息。 这个 innodb_api_trx_level配置选项控制交易 隔离级别 在查询处理 memcached 。虽然 memcached 没有概念 交易 ,您可以使用此选项来控制多久 memcached 看到的变化,在使用的表发出的SQL语句造成的 daemon_memcached 插件默认情况下, innodb_api_trx_level是集 READ UNCOMMITTED这个 innodb_api_enable_mdl选项可以用来锁定表在MySQL的水平,这样的映射表不能删除或改变 DDL 通过SQL接口。没有锁,桌子可以从MySQL层下降,但保持在 InnoDB存储到 memcached 或其他一些用户停止使用它。 “ MDL “ 代表 “ 元数据锁定 “
InnoDBmemcached
安装: memcached 图书馆是MySQL服务器,使安装和设置相对简单。安装与运行 innodb_memcached_config.sql脚本创建一个 demo_test 表 memcached 使用,发出 INSTALL PLUGIN语句启用 daemon_memcached 插件,并添加所需的 memcached 选择一个MySQL的配置文件或启动脚本。你仍然可以安装传统 memcached 如公用事业附加分布 memcp , memcat ,和 memcapable 比较与传统的 memcached ,看到 安装 memcached 部署:与传统 memcached ,这是典型的运行大量低容量 memcached 服务器在一个典型的部署 daemon_memcached插件,然而,涉及少量的中等或高性能已在运行MySQL服务器。这种配置的好处是提高个人数据库服务器的效率而不是利用未使用的内存或分布在多台服务器查找。在默认配置中,很少的内存使用 memcached 在内存中查找服务,并从 InnoDB缓冲池 ,自动缓存最近频繁使用的数据。与传统的MySQL服务器实例,保存的价值 innodb_buffer_pool_size配置选项实际高(不在操作系统级别的分页),使尽可能多的工作是在内存中进行。 比较与传统的 memcached ,看到 memcached 部署 有效期:默认情况下(即使用 innodb_only缓存策略),从最新的数据 InnoDB 表总是返回,所以到期期权没有实际效果。如果你改变缓存策略 caching或 唯一的隐藏 ,到期期权照常工作,但请求的数据可能是陈腐的如果是更新基础表从内存缓存到期之前。 比较与传统的 memcached ,看到 数据有效 namespaces: memcached 像一个大的目录,你给文件名称的前缀和后缀精心保持文件的冲突。这个 daemon_memcached插件可以让你使用类似的命名约定为键,增加一个。在关键的格式名称 @ @ table_idkeytable_id解码参考具体的表,使用从测绘数据 innodb_memcache.containers 表这个 key是在抬头或写入到指定的表。 这个 @@符号只适用于个人的电话 得到 , add,和 配置 的功能,而不是其他如 incr或 删除 。指定用于随后的默认表 memcached 在一个会话中执行一个操作, get要求使用 @ @ 符号与 table_id,但没有关键部分。例如: 得到@ @ table_id随后 get, 配置 , incr, 删除 和其他操作,使用指定的表 table_id在 innodb_memcache.containers.name 专栏 比较与传统的 memcached ,看到 使用命名空间 散列分布:默认配置,使用 innodb_only缓存策略,适用于传统的部署配置,所有数据可在所有的服务器,如一套复制从服务器。 如果你的身体划分数据,作为一个分散配置,你可以把数据在一些机器上运行 daemon_memcached插件,用传统的 memcached 散列机制,某个特定的机器的路由请求。在MySQL的一面,你会让所有的数据被插入的 add请求 memcached 所以,适当的值存储在相应的服务器数据库中。 比较与传统的 memcached ,看到 memcached 散列/分布类型 内存使用:默认情况下(与 innodb_only缓存Policy),the memcached 协议通过信息来回 InnoDB表,和 InnoDB 缓冲池的内存中查找,而不是处理 memcached 内存使用量的增长和收缩。内存比较少用的 memcached 侧面 如果你切换缓存策略 caching或 唯一的隐藏 ,正常的规则 memcached 内存使用申请。记忆 memcached 数据值分配条款 “ 板 “ 。你可以控制用于板坯尺寸和最大内存 memcached 无论哪种方式,你可以监控和故障排除 daemon_memcached插件使用熟悉的 统计 系统通过标准协议访问,在 Telnet 会话,例如。额外的设施不包括在 daemon_memcached插件你可以使用 memcached-tool脚本 安装全 memcached 销售 比较与传统的 memcached ,看到 在内存分配 memcached 用法:MySQL线程和线程 memcached 线程并存于同一服务器。限制线程由操作系统适用于线程的总数。 比较与传统的 memcached ,看到 memcached 线程的支持 日志:“因为usage memcached 守护进程是运行在MySQL服务器写 stderr,的 V , -vv,和 - VVV 选择日志输出写入MySQL 错误日志 比较与传统的 memcached ,看到 memcached 日志 memcached 操作:熟悉 memcached 等操作 get, 配置 , add,和 删除 可用。序列化(即确切的字符串格式表示复杂的数据结构)取决于语言接口。 比较与传统的 memcached ,看到 基本 memcached 运营 使用 memcached 作为一个MySQL前端:这是主要目的的 InnoDBmemcached 插件一个集成的 memcached 守护进程,提高应用程序的性能,并具有 InnoDB处理数据传输之间的内存和硬盘可以简化应用程序的逻辑。 比较与传统的 memcached ,看到 使用 memcached 作为一个MySQL缓存层 事业:MySQL服务器包括 libmemcached图书馆而不是额外的命令行工具。使用命令如 memcp , memcat ,和 memcapable 命令,安装一个全 memcached 销售什么时候 memrm 和 memflush 从缓存中删除项目,该项目也从底层的删除 InnoDB表 比较与传统的 memcached ,看到 libmemcached 命令行实用工具 编程接口:您可以通过访问MySQL服务器 daemon_memcached插件使用所有支持的语言: C和C , Java , Perl , Python , PHP ,和 红宝石 。指定服务器的主机名和端口与传统 memcached 服务器默认情况下,该 daemon_memcached插件侦听端口 一万一千二百一十一 。你可以同时使用 文本和二进制协议 。你可以定制 行为 属于 memcached 函数在运行时。序列化(即确切的字符串格式表示复杂的数据结构)取决于语言接口。 比较与传统的 memcached ,看到 开发一个 memcached 应用 常见问题:MySQL传统广泛的常见问题 memcached 。FAQ主要是适用的,除非使用 InnoDB表作为存储介质 memcached 数据意味着,你可以使用 memcached 更多的写密集型应用于前,而不是作为一个只读缓存。
daemon_memcached
daemon_memcached
这个 daemon_memcached插件只支持Linux,Solaris,和OS X平台上。不支持其他操作系统。 当建立MySQL从源,你必须建立 -DWITH_INNODB_MEMCACHED=ON。这个建造选项在MySQL插件目录生成两个共享库( plugin_dir),是需要运行 daemon_memcached 插件: libmemcached.so: the memcached 后台插件MySQL innodb_engine.so:一个 InnoDB API插件 memcached
libevent必须安装 如果你没有从源代码构建的MySQL, libevent图书馆是不包括在您的安装。使用安装方法为您的操作系统安装 libevent 1.4.12或后。例如,根据不同的操作系统,你可以使用 apt-get, 百胜餐饮集团 ,或 port install。例如,在Ubuntu Linux,使用: sudo的ATP - get install libevent DEV 如果你安装MySQL从源代码发布, libevent1.4.12捆绑包,位于MySQL源代码目录的顶层。如果你使用捆绑版 libevent ,无需行动。如果你想使用本地系统版本 libevent,你必须与建立MySQL -DWITH_LIBEVENT建立选项设置 系统 或 yes
配置 daemon_memcached插件可以互动 InnoDB 表运行 innodb_memcached_config.sql配置脚本,它位于 MYSQL_HOME分享 。这个脚本安装 _ memcache InnoDB 三所需的表数据库( cache_policies, _配置选项 ,和 containers)。它还安装了 demo_test 在示例表 test数据库 MySQL的> sourceMYSQL_HOME/share/innodb_memcached_config.sql运行 innodb_memcached_config.sql脚本是一种一次性手术。表留在原地,以后如果你卸载并重新安装 daemon_memcached 插件 mysql>
USE innodb_memcache;mysql>SHOW TABLES;+---------------------------+ | Tables_in_innodb_memcache | +---------------------------+ | cache_policies | | config_options | | containers | +---------------------------+ mysql>USE test;mysql>SHOW TABLES;+----------------+ | Tables_in_test | +----------------+ | demo_test | +----------------+Of these tables,the innodb_memcache.containers表是最重要的。中的条目 容器 提供一个映射表 InnoDB表列。每个 InnoDB 用表 daemon_memcached插件需要在入口 容器 表 这个 innodb_memcached_config.sql脚本中插入一个进入 容器 为提供一个映射表 demo_test表它也插入一行数据到 demo_test 表这个数据让你立即验证安装设置完成后。 mysql>
SELECT * FROM innodb_memcache.containers\G*************************** 1. row *************************** name: aaa db_schema: test db_table: demo_test key_columns: c1 value_columns: c2 flags: c3 cas_column: c4 expire_time_column: c5 unique_idx_name_on_key: PRIMARY mysql>SELECT * FROM test.demo_test;+----+------------------+------+------+------+ | c1 | c2 | c3 | c4 | c5 | +----+------------------+------+------+------+ | AA | HELLO, HELLO | 8 | 0 | 0 | +----+------------------+------+------+------+为更多的信息关于 innodb_memcache表和 demo_test 示例表,看 第15.19.8,“InnoDB Memcached插件内” 激活 daemon_memcached插件运行 INSTALL PLUGIN声明: MySQL的> INSTALL PLUGIN daemon_memcached soname "libmemcached.so";一旦安装了这个插件,它会自动启动MySQL服务器重启一次。
daemon_memcached
重新编织数据 test.demo_test表。单一数据的行 demo_test 桌上有一个关键值 AAtelnet localhost 11211尝试连接到127.0.0.1…localhost。转义字符是“^ ]”。 get AA价值8 12hello AA,helloend 使用插入数据 set命令 set BB 10 0 16GOODBYE, GOODBYE存储 哪里: set是命令,存储一个值 BB是关键 10是一个用于操作标志;忽视 memcached 但可以由客户端用来表示任何类型的信息;指定 0如果未使用 0是expiration时间(TTL)specify; 零 如果未使用 16在字节的值块的长度 GOODBYE, GOODBYE是储存价值
验证数据插入存储在MySQL连接到MySQL服务器,查询 test.demo_test表 MySQL的> SELECT * FROM test.demo_test;---- ------------------ ------ ------ ------ | C1 C2 C3 C4 | | | | C5 | ---- ------------------ ------ ------ ------ | AA |你好,你好| 8 | 0 | 0 | | BB |再见,再见| 10 | 1 | 0 | ---- ------------------ ------ ------ ------ 回到Telnet会话和检索数据的插入,你前面使用的关键 BBget BB价值10 16goodbye BB,goodbyeend quit
InnoDB
gettest.demo_test
InnoDB
创建一个 InnoDB表表必须具有唯一索引有一个键列。城市的表的键列 city_id ,它被定义为主键。该表还必须包括柱 flags, 中国科学院 ,和 expiry价值观。可能有一个或多个值的列。这个 城市 表三值的列( name, 状态 , country) 笔记 没有特别的要求相对于列名只要有效的映射添加到 innodb_memcache.containers表 MySQL的> CREATE TABLE city (city_id VARCHAR(32),name VARCHAR(1024),state VARCHAR(1024),country VARCHAR(1024),flags INT,cas BIGINT UNSIGNED,expiry INT,primary key(city_id)) ENGINE=InnoDB;添加项目到 innodb_memcache.containers表, daemon_memcached 插件知道如何访问 InnoDB表。satisfy the the entry must innodb_memcache.containers 表定义。用于描述每一个领域,看 第15.19.8,“InnoDB Memcached插件内” mysql>
DESCRIBE innodb_memcache.containers;+------------------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------------------+--------------+------+-----+---------+-------+ | name | varchar(50) | NO | PRI | NULL | | | db_schema | varchar(250) | NO | | NULL | | | db_table | varchar(250) | NO | | NULL | | | key_columns | varchar(250) | NO | | NULL | | | value_columns | varchar(250) | YES | | NULL | | | flags | varchar(250) | NO | | 0 | | | cas_column | varchar(250) | YES | | NULL | | | expire_time_column | varchar(250) | YES | | NULL | | | unique_idx_name_on_key | varchar(250) | NO | | NULL | | +------------------------+--------------+------+-----+---------+-------+这个 innodb_memcache.containers对于城市表表项的定义是: MySQL的> INSERT INTO `innodb_memcache`.`containers` (`name`, `db_schema`, `db_table`, `key_columns`, `value_columns`,`flags`, `cas_column`, `expire_time_column`, `unique_idx_name_on_key`)VALUES ('default', 'test', 'city', 'city_id', 'name|state|country','flags','cas','expiry','PRIMARY');default被指定为 containers.name 柱配置 city表为默认 InnoDB 桌子是用 daemon_memcached插件 多 InnoDB表列( 姓名 , state, 国家 )映射到 containers.value_columns使用 “ | “ 分隔符 这个 flags, 例_柱 ,和 expire_time_column田野里的 innodb_memcache.containers 表通常不重要的应用程序使用 daemon_memcached插件然而,指定 InnoDB 表列要求每个。当插入数据,指定 0如果他们不使用这些列。
更新后的 innodb_memcache.containers表,重新启动 _ Memcache守护进程 插件应用更改 mysql>
UNINSTALL PLUGIN daemon_memcached;mysql>INSTALL PLUGIN daemon_memcached soname "libmemcached.so";使用Telnet,数据插入 city表格的使用 memcached set命令 telnet localhost 11211尝试连接到127.0.0.1…localhost。转义字符是“^ ]”。 set B 0 0 22BANGALORE|BANGALORE|IN存储 使用MySQL查询 test.city表来验证你插入的数据存储。 MySQL的> SELECT * FROM test.city;--------- ----------- ----------- --------- ------- ------ -------- | city_id |名字|状态|国|旗帜| CAS |到期| --------- ----------- ----------- --------- ------- ------ -------- | B |班加罗尔|班加罗尔|在| 0 | 3 | 0 | --------- ----------- ----------- --------- ------- ------ -------- 使用MySQL,插入额外的数据进 test.city表 MySQL的> INSERT INTO city VALUES ('C','CHENNAI','TAMIL NADU','IN', 0, 0 ,0);MySQL的> INSERT INTO city VALUES ('D','DELHI','DELHI','IN', 0, 0, 0);MySQL的> INSERT INTO city VALUES ('H','HYDERABAD','TELANGANA','IN', 0, 0, 0);MySQL的> INSERT INTO city VALUES ('M','MUMBAI','MAHARASHTRA','IN', 0, 0, 0);笔记 建议您指定一个值 0对于 旗帜 , cas_column,和 _到期时间_柱 如果他们不使用领域 使用Telnet,问题 memcached get命令来检索你插入使用MySQL数据。 get H| H 0值22hyderabad泰| inend
memcacheddaemon_memcached_option
-p11222daemon_memcached_option
mysqld .... --daemon_memcached_option="-p11222"
daemon_memcached_option
daemon_memcached
daemon_memcached_engine_lib_name:指定共享库的实现 InnoDB memcached 插件默认设置是 innodb_engine.sodaemon_memcached_engine_lib_path:路径的目录包含共享库的实现 InnoDB memcached 插件。默认是空的茶叶,茶叶representing a插件目录。 daemon_memcached_r_batch_size:定义批量提交读取操作的大小( 得到 )。它specifies the number of memcached 读操作之后, 犯罪 发生. daemon_memcached_r_batch_size默认设置为1,每 得到 请求访问最近提交的数据在 InnoDB表格,数据是否是通过更新 memcached 或通过SQL。当该值大于1,读操作的计数器每 get呼叫。一 flush_all 调用读写计数器重置 daemon_memcached_w_batch_size:定义批量提交大小写操作( 配置 , replace, 追加 , prepend, 增加 , decr,等等) daemon_memcached_w_batch_size设置为1默认所以没有未提交的数据丢失在停电的情况下,因此,对基础表的访问最新数据的SQL查询。当该值大于1,写操作的计数器每 添加 , set, 增加 , decr,和 删除 呼叫。一 flush_all调用读写计数器重置
daemon_memcached_engine_lib_namedaemon_memcached_engine_lib_path
daemon_memcacheddaemon_memcached
daemon_memcached
MySQL的> UNINSTALL PLUGIN daemon_memcached;MySQL的> INSTALL PLUGIN daemon_memcached soname "libmemcached.so";
daemon_memcached
多去操作
InnoDB
test.city
mysql>USE test;mysql>SELECT * FROM test.city;+---------+-----------+-------------+---------+-------+------+--------+ | city_id | name | state | country | flags | cas | expiry | +---------+-----------+-------------+---------+-------+------+--------+ | B | BANGALORE | BANGALORE | IN | 0 | 1 | 0 | | C | CHENNAI | TAMIL NADU | IN | 0 | 0 | 0 | | D | DELHI | DELHI | IN | 0 | 0 | 0 | | H | HYDERABAD | TELANGANA | IN | 0 | 0 | 0 | | M | MUMBAI | MAHARASHTRA | IN | 0 | 0 | 0 | +---------+-----------+-------------+---------+-------+------+--------+
get
telnet 127.0.0.1 11211Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'.get B C D H MVALUE B 0 22 BANGALORE|BANGALORE|IN VALUE C 0 21 CHENNAI|TAMIL NADU|IN VALUE D 0 14 DELHI|DELHI|IN VALUE H 0 22 HYDERABAD|TELANGANA|IN VALUE M 0 21 MUMBAI|MAHARASHTRA|IN END
getcontainers.name
get @@aaa.AA BB值“8 12hello @aaa.aa,hellovalue BB 10 16goodbye,goodbyeend
get
范围查询
daemon_memcached<><=>=
test.city
mysql> SELECT * FROM test.city;
+---------+-----------+-------------+---------+-------+------+--------+
| city_id | name | state | country | flags | cas | expiry |
+---------+-----------+-------------+---------+-------+------+--------+
| B | BANGALORE | BANGALORE | IN | 0 | 1 | 0 |
| C | CHENNAI | TAMIL NADU | IN | 0 | 0 | 0 |
| D | DELHI | DELHI | IN | 0 | 0 | 0 |
| H | HYDERABAD | TELANGANA | IN | 0 | 0 | 0 |
| M | MUMBAI | MAHARASHTRA | IN | 0 | 0 | 0 |
+---------+-----------+-------------+---------+-------+------+--------+
telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
B
get @>B
VALUE C 0 21
CHENNAI|TAMIL NADU|IN
VALUE D 0 14
DELHI|DELHI|IN
VALUE H 0 22
HYDERABAD|TELANGANA|IN
VALUE M 0 21
MUMBAI|MAHARASHTRA|IN
END
Mget @<M
get @<M
VALUE B 0 22
BANGALORE|BANGALORE|IN
VALUE C 0 21
CHENNAI|TAMIL NADU|IN
VALUE D 0 14
DELHI|DELHI|IN
VALUE H 0 22
HYDERABAD|TELANGANA|IN
END
Mget @<=M
get @<=M
VALUE B 0 22
BANGALORE|BANGALORE|IN
VALUE C 0 21
CHENNAI|TAMIL NADU|IN
VALUE D 0 14
DELHI|DELHI|IN
VALUE H 0 22
HYDERABAD|TELANGANA|IN
VALUE M 0 21
MUMBAI|MAHARASHTRA|IN
Bget @>B@<M
get @>B@<MC值的0 21chennai |泰米尔纳德邦|价值0 14delhi |德里|至H 0 22hyderabad |特|时尚
@<@<=@>@>=getgetB@>C
get @<M@>B@>CC值的0 21chennai |泰米尔纳德邦|价值0 14delhi |德里|至H 0 22hyderabad | |在特
daemon_memcached
daemon_memcached
daemon_memcached
InnoDBInnoDB
daemon_memcached
daemon_memcacheddaemon_memcached
安装该开发工具库。例如,在使用Ubuntu, apt-get 获得图书馆: sudo apt-get -f install libsasl2-2 sasl2-bin libsasl2-2 libsasl2-dev libsasl2-modules
建立 daemon_memcached插件的共享库SASL能力增加 ENABLE_MEMCACHED_SASL=1你的 CMake 选项 memcached 还提供了 简单的明文密码支持 ,这有利于测试。使简单的明文密码支持,指定 ENABLE_MEMCACHED_SASL_PWDB=1CMake 选项 总之,添加以下三 CMake 备选办法: cmake ... -DWITH_INNODB_MEMCACHED=1 -DENABLE_MEMCACHED_SASL=1 -DENABLE_MEMCACHED_SASL_PWDB=1
安装 daemon_memcached插件,如 第15.19.3,设置innodb memcached插件” 配置用户名和密码文件。(本例使用 memcached 简单的明文密码的支持。) 在一个文件中,创建一个用户命名 testname定义的密码 testpasswd : echo "testname:testpasswd:::::::" >/home/jy/memcached-sasl-db
配置 MEMCACHED_SASL_PWDB环境变量的通知 memcached 用户名称和密码的文件。 export MEMCACHED_SASL_PWDB=/home/jy/memcached-sasl-db
通知 memcached一个明文密码的使用: echo "mech_list: plain" > /home/jy/work2/msasl/clients/memcached.confexport SASL_CONF_PATH=/home/jy/work2/msasl/clients
使用MySQL服务器重新启动SASL memcached -S选项中的编码 daemon_memcached_option配置参数: mysqld ... --daemon_memcached_option="-S"
测试设置,使用SASL启用客户端等 SASL -启用libmemcached memcp --servers=localhost:11211 --binary --username=testname --password=
passwordmyfile.txt memcat --servers=localhost:11211 --binary --username=testname --password=passwordmyfile.txt如果你指定了一个错误的用户名或密码,操作拒绝与 memcache error AUTHENTICATION FAILURE消息在这种情况下,检查组在明文密码 memcached SASL分贝 文件验证您提供的凭据是正确的。
InnoDB
与 daemon_memcached插件,取代传统 memcached 低功率的机器上运行的服务器,你有相同数量的 memcached 服务器的MySQL服务器,有大量的磁盘存储和内存在较高功率的机器上运行。你可以利用一些现有的代码,与 memcached API,但是可能需要的由于不同的服务器配置是适应。 存储的数据通过 daemon_memcached插件进入 VARCHAR, TEXT,或 BLOB列,必须转化为数值运算。你可以在应用程序端执行转换,或使用 (CAST) 函数在查询 来自一个数据库的背景,你可以用通用的SQL表有很多列。表访问 memcached 代码可能只有几个甚至一个单柱保持数据的值。 你会适应你的应用程序,执行单排查询,插入,更新,或删除部分,提高代码的关键部分的性能。两 查询 (读)和 DML (写)操作可以大大加快时,通过 InnoDBmemcached 接口绩效改进为写一般大于性能改进的读取,所以你可能会专注于适应代码执行记录或记录在网站互动的选择。
daemon_memcached
memcached 钥匙不能包含空格或换行符,因为这些字符作为分隔符的ASCII协议。如果您使用的是包含空格或哈希查找的值,变换成价值没有空间之前使用它们作为键调用 add(), set() , get(),等等。尽管在理论上,这些人物都是在程序中使用二进制协议,密钥允许,你应该限制使用密钥来保证与范围广泛的客户端兼容性的特点。 如果有一个短暂的数字 主键 柱在 InnoDB表,用它作为一种独特的查找键 memcached 通过将整数字符串值。如果 memcached 服务器用于多个应用程序,或一个以上 InnoDB表,考虑修改的名义保证,它是独一无二的。例如,在表名,或数据库名称和表名称,数值之前。 笔记 这个 daemon_memcached插件支持插入和读取映射 InnoDB 表中有一个 INTEGER定义为主键 你不能使用一个分区表数据的查询或存储使用 memcached 这个 memcached 协议通过数值约为字符串。在底层存储数值 InnoDB表,实现计数器可用于SQL等功能 Sum() 或 AVG()的,例如: 使用 VARCHAR有足够的字符列持有最大的预期数所有数字(和额外的字符是否适合正负号、小数点,或两者都有)。 在任何查询执行使用列值的算法,使用 CAST()函数将该值从字符串,整数,或其他一些数字类型。例如: #字母条目作为zero.select投回来(C2为无符号整数)从demo_test;#自会有0个数值,不能取消它们。#测试字符串值,发现都是整数的,平均只有those.select AVG(CAST(C2为无符号整数))从demo_test C2之间“0”和“9999999999”;#观点让你隐藏的查询的复杂性。结果已经转换;#无需重复转换函数和WHERE子句中每个time.create视图数作为选择C1键,铸造(C2为无符号整数)值从demo_test C2之间的“0”和“9999999999”;选择和(Val)数; 笔记 在结果集的任何字母的值被转换为0的电话 CAST()。当使用等功能 的AVG() ,这取决于结果集中的行数,包括 WHERE子句过滤掉非数字值
如果 InnoDB列作为键能值超过250字节,哈希值小于250字节。 使用现有的表 daemon_memcached插件,定义在它的入口 innodb_memcache.containers 表使表默认为所有 memcached 请求,指定一个值 default在 姓名 列,然后重新启动MySQL服务器使改变生效。如果您使用多台不同类 memcached 数据,在建立多个条目 innodb_memcache.containers表 姓名 您选择的值,然后发出 memcached 在形式上的要求 get @@name或 集@ @ name在应用程序中指定要用于后续的表 memcached 请求 对于使用非预定义的表格实例 test.demo_test表,看 例15,“用你自己的表与InnoDB Memcached应用” 。所需的表格布局,看 第15.19.8,“InnoDB Memcached插件内” 使用多个 InnoDB表列值 memcached 键/值对指定列的名称,用逗号、分号、空格隔开,或在管道的特点 value_columns场的 innodb_memcache.containers 入境的 InnoDB表例如,指定 COL1,COL2,col3 或 col1|col2|col3在 value_columns 场 将该列的值到使用管道字符作为分隔符一个字符串通过之前的字符串 memcached add或 配置 电话.字符串是解压后自动进入正确的列。每个 get调用返回一个字符串包含的列值,也由管字符分隔。你可以打开值使用适当的应用程序语言的语法。
memcached
daemon_memcachedpython-memcache
创建 multicol包括人口、面积表存储的国家信息,与驾驶员侧的数据( “R” 权利和 'L'For left). MySQL的> USE test;MySQL的> CREATE TABLE `multicol` (`country` varchar(128) NOT NULL DEFAULT '',`population` varchar(10) DEFAULT NULL,`area_sq_km` varchar(9) DEFAULT NULL,`drive_side` varchar(1) DEFAULT NULL,`c3` int(11) DEFAULT NULL,`c4` bigint(20) unsigned DEFAULT NULL,`c5` int(11) DEFAULT NULL,PRIMARY KEY (`country`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;插入一条记录到 innodb_memcache.containers表, daemon_memcached 插件可以访问 multicol表 MySQL的> INSERT INTO innodb_memcache.containers(name,db_schema,db_table,key_columns,value_columns,flags,cas_column,expire_time_column,unique_idx_name_on_key)VALUES('bbb','test','multicol','country','population,area_sq_km,drive_side','c3','c4','c5','PRIMARY');MySQL的> COMMIT;这个 innodb_memcache.containers记录的 多色 列于表 name价值 “BBB” ,这是表标识符 笔记 如果一个单 InnoDB表用于所有 memcached 应用程序的 name值可设定 默认 避免使用 @@符号转换表 这个 db_schema栏目设置 测试 ,这是数据库的名称, multicol表驻留 这个 db_table栏目设置 多色 ,它的名字是 InnoDB表 key_columns是一套独特的 国家 专栏这个 country列定义为在主键 多色 表定义 而不是一个单一的 InnoDB表列包含复合数据值,数据分为三列的表格中( 人口 , area_sq_km,和 drive_side )。容纳多个值的列,用逗号分隔的列表中指定的列 value_columns场。在定义的列 value_columns 现场使用时,存储或检索值的列。 值为 flags, expire _时 ,和 cas_column字段中使用基于价值观 demo.test 示例表。这些领域通常是不显着的应用程序使用 daemon_memcached因为MySQL插件保持数据同步,无需担心数据到期或过期。 这个 unique_idx_name_on_key字段设置为 首要 ,指的是在独特的定义主要指标 country列在 多色 表
Python应用复制到一个文件。在这个例子中,该示例脚本复制到一个文件名为 multicol.py样品的Python应用将数据插入到 multicol表中的所有密钥数据,演示如何访问 InnoDB 表通过 daemon_memcached插件 import sys, osimport memcachedef connect_to_memcached(): memc = memcache.Client(['127.0.0.1:11211'], debug=0); print "Connected to memcached." return memcdef banner(message): print print "=" * len(message) print message print "=" * len(message)country_data = [("Canada","34820000","9984670","R"),("USA","314242000","9826675","R"),("Ireland","6399152","84421","L"),("UK","62262000","243610","L"),("Mexico","113910608","1972550","R"),("Denmark","5543453","43094","R"),("Norway","5002942","385252","R"),("UAE","8264070","83600","R"),("India","1210193422","3287263","L"),("China","1347350000","9640821","R"),]def switch_table(memc,table): key = "@@" + table print "Switching default table to '" + table + "' by issuing GET for '" + key + "'." result = memc.get(key)def insert_country_data(memc): banner("Inserting initial data via memcached interface") for item in country_data: country = item[0] population = item[1] area = item[2] drive_side = item[3] key = country value = "|".join([population,area,drive_side]) print "Key = " + key print "Value = " + value if memc.add(key,value): print "Added new key, value pair." else: print "Updating value for existing key." memc.set(key,value)def query_country_data(memc): banner("Retrieving data for all keys (country names)") for item in country_data: key = item[0] result = memc.get(key) print "Here is the result retrieved from the database for key " + key + ":" print result (m_population, m_area, m_drive_side) = result.split("|") print "Unpacked population value: " + m_population print "Unpacked area value : " + m_area print "Unpacked drive side value: " + m_drive_sideif __name__ == '__main__': memc = connect_to_memcached() switch_table(memc,"bbb") insert_country_data(memc) query_country_data(memc) sys.exit(0)Python应用笔记: 没有数据库的权限运行应用程序所需的数据操作,因为执行 memcached 接口唯一需要的信息端口号在本地系统上 memcached 恶魔听 确保应用程序使用 multicol表的 switch_table() 函数被调用时,它执行一个虚拟 get或 配置 要求使用 @@符号。这个 姓名 在要求值 bbb,这是 多色 表中定义的标识符 innodb_memcache.containers.name场 一个更具描述性的 name值可以用在现实世界的应用。这个例子只是说明了一个表标识符指定而不是表名 得到@ @… 请求 本函数用于插入和查询数据演示如何将一个Python数据结构为管分离值发送数据到MySQL add或 配置 的要求,以及如何拆管分离的返回值 get请求这种额外的处理,只需在映射一个 memcached 多个MySQL表列值。
运行Python应用。 shell>
python multicol.py如果成功,该示例应用程序返回的输出: Connected to memcached. Switching default table to 'bbb' by issuing GET for '@@bbb'. ============================================== Inserting initial data via memcached interface ============================================== Key = Canada Value = 34820000|9984670|R Added new key, value pair. Key = USA Value = 314242000|9826675|R Added new key, value pair. Key = Ireland Value = 6399152|84421|L Added new key, value pair. Key = UK Value = 62262000|243610|L Added new key, value pair. Key = Mexico Value = 113910608|1972550|R Added new key, value pair. Key = Denmark Value = 5543453|43094|R Added new key, value pair. Key = Norway Value = 5002942|385252|R Added new key, value pair. Key = UAE Value = 8264070|83600|R Added new key, value pair. Key = India Value = 1210193422|3287263|L Added new key, value pair. Key = China Value = 1347350000|9640821|R Added new key, value pair. ============================================ Retrieving data for all keys (country names) ============================================ Here is the result retrieved from the database for key Canada: 34820000|9984670|R Unpacked population value: 34820000 Unpacked area value : 9984670 Unpacked drive side value: R Here is the result retrieved from the database for key USA: 314242000|9826675|R Unpacked population value: 314242000 Unpacked area value : 9826675 Unpacked drive side value: R Here is the result retrieved from the database for key Ireland: 6399152|84421|L Unpacked population value: 6399152 Unpacked area value : 84421 Unpacked drive side value: L Here is the result retrieved from the database for key UK: 62262000|243610|L Unpacked population value: 62262000 Unpacked area value : 243610 Unpacked drive side value: L Here is the result retrieved from the database for key Mexico: 113910608|1972550|R Unpacked population value: 113910608 Unpacked area value : 1972550 Unpacked drive side value: R Here is the result retrieved from the database for key Denmark: 5543453|43094|R Unpacked population value: 5543453 Unpacked area value : 43094 Unpacked drive side value: R Here is the result retrieved from the database for key Norway: 5002942|385252|R Unpacked population value: 5002942 Unpacked area value : 385252 Unpacked drive side value: R Here is the result retrieved from the database for key UAE: 8264070|83600|R Unpacked population value: 8264070 Unpacked area value : 83600 Unpacked drive side value: R Here is the result retrieved from the database for key India: 1210193422|3287263|L Unpacked population value: 1210193422 Unpacked area value : 3287263 Unpacked drive side value: L Here is the result retrieved from the database for key China: 1347350000|9640821|R Unpacked population value: 1347350000 Unpacked area value : 9640821 Unpacked drive side value: R
查询 innodb_memcache.containers表观你插入的早期记录 多色 表第一个记录的样本输入 demo_test表,在初始创建 daemon_memcached 插件的设置。第二记录是你插入的入口 multicol表 MySQL的> SELECT * FROM innodb_memcache.containers\G*************************** 1。行***************************名称:AAA db_schema:测试db_table:demo_test key_columns:C1 C2 C3 value_columns:国旗:cas_column:C4 expire_time_column:c5unique_idx_name_on_key:主要*************************** 2。行***************************名称:BBB db_schema:测试db_table:多色key_columns:国家value_columns:人口、area_sq_km,drive_side标志:C3 C4 cas_column:expire_time_column:c5unique_idx_name_on_key:初级 查询 multicol表观的Python应用插入数据。该数据可用于MySQL 查询 这说明,同样的数据可以使用SQL或通过应用程序访问(使用适当的 MySQL连接器或API ) mysql>
SELECT * FROM test.multicol;+---------+------------+------------+------------+------+------+------+ | country | population | area_sq_km | drive_side | c3 | c4 | c5 | +---------+------------+------------+------------+------+------+------+ | Canada | 34820000 | 9984670 | R | 0 | 11 | 0 | | China | 1347350000 | 9640821 | R | 0 | 20 | 0 | | Denmark | 5543453 | 43094 | R | 0 | 16 | 0 | | India | 1210193422 | 3287263 | L | 0 | 19 | 0 | | Ireland | 6399152 | 84421 | L | 0 | 13 | 0 | | Mexico | 113910608 | 1972550 | R | 0 | 15 | 0 | | Norway | 5002942 | 385252 | R | 0 | 17 | 0 | | UAE | 8264070 | 83600 | R | 0 | 18 | 0 | | UK | 62262000 | 243610 | L | 0 | 14 | 0 | | USA | 314242000 | 9826675 | R | 0 | 12 | 0 | +---------+------------+------------+------------+------+------+------+笔记 总是允许足够的尺寸保持必要的数字、小数点、符号、前导零,所以当定义的长度,作为数字列。太长值字符串列如 VARCHAR通过删除一些字符截断,从而产生无意义的数字值。 可选地,运行在报告类型查询 InnoDB那商店的表 memcached 数据 你可以通过SQL查询生成报表,进行计算和测试的任何列,不只是 country键列。(因为下面的例子使用的数据来自少数几个国家,数字只是为了说明的目的。)下面的查询返回的国家里人们靠右行驶的平均人口,和国家的名字开始的平均尺寸 “ U “ : mysql>
SELECT AVG(population) FROM multicol WHERE drive_side = 'R';+-------------------+ | avg(population) | +-------------------+ | 261304724.7142857 | +-------------------+ mysql>SELECT SUM(area_sq_km) FROM multicol WHERE country LIKE 'U%';+-----------------+ | sum(area_sq_km) | +-----------------+ | 10153885 | +-----------------+因为 population和 area_sq_km 列存储字符数据而不是强类型的数字数据、功能等 AVG()和 Sum() 通过将每个值一个数。这种方法 不工作 运营商如 <或 > ,例如,当比较的基于字符的值, 9 > 1000,这是不希望的一个条款,如 人口倒序 。最准确的分型治疗,进行反对的意见,铸造数字列到适当类型的查询。这种技术可以让你的问题简单 SELECT *从数据库的查询应用,同时确保铸造、过滤和排序是正确的。下面的示例显示一个视图,可以查询到人口降序找到排名前三位的国家,反映在最新数据的结果 多色 表,并与人口和面积的数字为数字处理: mysql>
CREATE VIEW populous_countries ASSELECTcountry,cast(population as unsigned integer) population,cast(area_sq_km as unsigned integer) area_sq_km,drive_side FROM multicolORDER BY CAST(population as unsigned integer) DESCLIMIT 3;mysql>SELECT * FROM populous_countries;+---------+------------+------------+------------+ | country | population | area_sq_km | drive_side | +---------+------------+------------+------------+ | China | 1347350000 | 9640821 | R | | India | 1210193422 | 3287263 | L | | USA | 314242000 | 9826675 | R | +---------+------------+------------+------------+ mysql>DESC populous_countries;+------------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------------+------+-----+---------+-------+ | country | varchar(128) | NO | | | | | population | bigint(10) unsigned | YES | | NULL | | | area_sq_km | int(9) unsigned | YES | | NULL | | | drive_side | varchar(1) | YES | | NULL | | +------------+---------------------+------+-----+---------+-------+
InnoDBdaemon_memcached
如果有关键值比几个字节长,它可能是更有效地使用数字自动递增列为 主键 的 InnoDB表,并创建一个独特的 次要指标 在列中包含的 memcached 核心价值观。这是因为 InnoDB表现最好的大型插入如果主键值的排列顺序添加(因为他们与自动增量值)。主键值都包含在二级指标,占用不必要的空间,如果主键是一个很长的字符串值。 如果你存储几个不同类别的信息使用 memcached ,考虑设立一个独立的 InnoDB对于每种类型的数据表。在定义额外的表标识符 innodb_memcache.containers 表,并使用 @@table_id.key符号来存储和检索不同表中的项目。物理上划分不同类型的信息,允许你调整优化空间利用每个表的特点、性能和可靠性。例如,你可能会使 压缩 一台拥有博客,而不是一个表保存缩略图。你可以备份一个表比另一个更频繁,因为它认为重要的数据。你可以创建额外的 二级指标 表经常被用来使用SQL生成报告。 优选的配置使用一套稳定的表定义 daemon_memcached 插件,并离开桌子的地方永久。变化的 innodb_memcache.containers表格生效一次 innodb_memcache.containers 查询表。在容器的表项进行处理,在启动,并征询意见时无法识别的表标识符(定义 containers.name请使用) @ @ 符号。因此,新的作品,可见只要你使用相关的表标识符,但改变现有的条目需要服务器重启才生效。 当您使用默认的 innodb_only缓存策略,调用 () , set(), (增加) ,等等可以成功但仍然触发调试信息等 while expecting 'STORED', got unexpected response 'NOT_STORED。调试信息的出现是因为新的和更新的值是直接发送到 InnoDB 没有被保存在内存中的缓存表,由于 innodb_only缓存策略
InnoDBInnoDB
采用SQL查询
GETWHERE
SQL:SELECT col FROM tbl WHERE key = 'key_value';memcached:get key_valueSQL:SELECT col FROM tbl WHERE col1 = val1 and col2 = val2 and col3 = val3;memcached:# Since you must always know these 3 values to look up the key,# combine them into a unique string and use that as the key# for all ADD, SET, and GET operations.key_value = val1 + ":" + val2 + ":" + val3get key_valueSQL:SELECT 'key exists!' FROM tbl WHERE EXISTS (SELECT col1 FROM tbl WHERE KEY = 'key_value') LIMIT 1;memcached:# Test for existence of key by asking for its value and checking if the call succeeds,# ignoring the value itself. For existence checking, you typically only store a very# short value such as "1".get key_value
使用系统内存
daemon_memcachedinnodb_buffer_pool_sizeinnodb_buffer_pool_instances
减少冗余I/O
InnoDBinnodb_doublewriteinnodb_flush_log_at_trx_commitinnodb_flush_method
减少交易费用
daemon_memcached_r_batch_sizedaemon_memcached_w_batch_size
daemon_memcached_r_batch_sizeNdaemon_memcached_w_batch_sizeN
daemon_memcached_w_batch_size100daemon_memcached_w_batch_size
InnoDBadd
daemon_memcached
daemon_memcachedsetget
daemon_memcached
频率的提交
InnoDBdaemon_memcached_w_batch_size=1daemon_memcached_w_batch_sizedaemon_memcached_w_batch_sizeinnodb_api_bk_commit_interval
InnoDB
事务隔离
getInnoDBinnodb_api_trx_levelREPEATABLE READinnodb_api_trx_level
禁用行锁memcached DML操作
innodb_api_disable_rowlockdaemon_memcachedOFFgetinnodb_api_disable_rowlock
innodb_api_disable_rowlock
allowing或disallowing DDL
ALTER TABLEinnodb_api_enable_mdlCREATE INDEX
数据存储在磁盘上,在内存中,或两者
innodb_memcache.cache_policiesinnodb_onlycache-only
cachingInnoDBcaching
getincrdelete
getcachingflushInnoDB
MySQL的> SELECT * FROM innodb_memcache.cache_policies;-------------- ------------- ------------- --------------- -------------- | policy_name | get_policy | set_policy | delete_policy | flush_policy | -------------- ------------- ------------- --------------- -------------- | cache_policy | innodb_only | innodb_only | innodb_only | innodb_only | -------------- ------------- ------------- --------------- -------------- MySQL > UPDATE innodb_memcache.cache_policies SET set_policy = 'caching'WHERE policy_name = 'cache_policy';
innodb_memcache.cache_policies
mysql>UNINSTALL PLUGIN daemon_memcached;mysql>INSTALL PLUGIN daemon_memcached soname "libmemcached.so";
daemon_memcacheddaemon_memcached
memcachedaddsetdecrdeletekey
t1innodb_memcache.containerskey_columnsvalue_columns
插入T1(键,值(Val) some_key, some_value);SELECT val FROM t1 WHERE key =some_key;UPDATE t1 SET val =new_valueWHERE key =some_key;UPDATE t1 SET val = val + x WHERE key =some_key;DELETE FROM t1 WHERE key =some_key;
TRUNCATE TABLEDELETEt1
TRUNCATE TABLE t1; DELETE FROM t1;
InnoDB
当查询一个表,也是通过 memcached 界面,记住 memcached 操作可以配置为将周期性的而不是每次写操作。这种行为是由 daemon_memcached_w_batch_size选项如果此选项设置为一个值大于 一 ,使用 READ UNCOMMITTED查询发现,刚插入的行。 MySQL的> SET SESSSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;MySQL的> SELECT * FROM demo_test;””””””””””。| CX | CY | C1 C2作为| CZ | | | CB | C3与C4 C5 | | | |””””””””””。| | |零零零零| A11 | | 123456789 | | 10 | |零零(3 |空|”-----------”””””””” 当修改一个表使用SQL,也通过 memcached 界面,您可以配置 memcached 行动开始一个新的交易周期而不是每一个读操作。这种行为是由 daemon_memcached_r_batch_size选项如果此选项设置为一个值大于 一 ,使用SQL表的更改立即可见的不 memcached 运营 这个 InnoDB表是(意向共享)或IX(意图独占)锁定在一个事务中的所有操作。如果你增加 daemon_memcached_r_batch_size和 daemon_memcached_w_batch_size基本上从他们的默认值 一 ,桌子是最有可能锁定之间的每个操作,防止 DDL statements on the表。
daemon_memcached
daemon_memcached
daemon_memcached
使用 daemon_memcached与MySQL的插件 二进制日志 ,使 innodb_api_enable_binlog配置选项 主服务器 。此选项只能设置在服务器启动。你还必须使MySQL二进制日志在主服务器上使用 --log-bin选项你可以在MySQL的配置文件中添加这些选项,或在 mysqld 命令行 mysqld ... --log-bin -–innodb_api_enable_binlog=1
配置主、从服务器,如 第17.1.2,“建立复制二进制日志文件的位置 使用 mysqldump 创建一个主数据快照,快照和同步到从服务器。 master shell>
mysqldump --all-databases --lock-all-tables > dbdump.dbslave shell>mysql < dbdump.db在主服务器上,问题 SHOW MASTER STATUS获得硕士双对数坐标 MySQL的> SHOW MASTER STATUS;在从服务器,使用 CHANGE MASTER TO语句设置一个从服务器,使用主二进制对数坐标。 MySQL的> CHANGE MASTER TOMASTER_HOST='localhost',MASTER_USER='root',MASTER_PASSWORD='',MASTER_PORT = 13000,MASTER_LOG_FILE='0.000001,MASTER_LOG_POS=114;开始的奴隶 mysql>
START SLAVE;如果错误日志打印输出类似下面的奴隶,准备复制。 2013-09-24T13:04:38.639684Z 49 [Note] Slave I/O thread: connected to master 'root@localhost:13000', replication started in log '0.000001' at position 114
InnoDB
demo_testdaemon_memcached
使用 set命令插入一个关键记录 test1 一个标志值, 10,到期价值 零 1,CAS的价值之和,在value of t1telnet 127.0.0.1 11211尝试连接到127.0.0.1…127.0.0.1.escape字符是^ ]”。 set test1 10 0 1t1存储 在主服务器上,检查记录插入 demo_test表假设 demo_test 表格是以前没有修改的,应该是有两个记录。一个关键的记录 AA,并记录您刚刚插入,一个关键 test1 。这个 c1柱图的关键, C2 列的值的 c3柱标志的价值, C4 柱的CAS值,和 c5柱的过期时间。过期时间设置为0,因为它是使用。 MySQL的> SELECT * FROM test.demo_test;------- -------------- ------ ------ ------ | C1 C2 C3 C4 | | | | C5 | ------- -------------- ------ ------ ------ | AA |你好,你好| 8 | 0 | 0 | | test1 | T1 | 10 | 1 | 0 | ------- -------------- ------ ------ ------ 检查相同的记录复制到从服务器。 mysql>
SELECT * FROM test.demo_test;+-------+--------------+------+------+------+ | c1 | c2 | c3 | c4 | c5 | +-------+--------------+------+------+------+ | AA | HELLO, HELLO | 8 | 0 | 0 | | test1 | t1 | 10 | 1 | 0 | +-------+--------------+------+------+------+使用 set命令来更新值的关键 新 telnet 127.0.0.1 11211Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'.set test1 10 0 2newSTORED更新被复制到从服务器(注意, cas价值也更新) MySQL的> SELECT * FROM test.demo_test;------- -------------- ------ ------ ------ | C1 C2 C3 C4 | | | | C5 | ------- -------------- ------ ------ ------ | AA |你好,你好| 8 | 0 | 0 | | test1 |新| 10 | 2 | 0 | ------- -------------- ------ ------ ------ 删除 test1记录使用 删除 命令 telnet 127.0.0.1 11211Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'.delete test1DELETED当 delete操作复制到奴隶的 test1 在奴隶的记录也被删除。 mysql>
SELECT * FROM test.demo_test;+----+--------------+------+------+------+ | c1 | c2 | c3 | c4 | c5 | +----+--------------+------+------+------+ | AA | HELLO, HELLO | 8 | 0 | 0 | +----+--------------+------+------+------+删除所有行的表的使用 flush_all命令 telnet 127.0.0.1 11211尝试连接到127.0.0.1…127.0.0.1.escape字符是^ ]”。 flush_all好啊 MySQL的> SELECT * FROM test.demo_test;空集合(0秒) 远程登录到主服务器并输入两个新记录。 telnet 127.0.0.1 11211Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'set test2 10 0 4againSTOREDset test3 10 0 5again1STORED确认两记录被复制到从服务器。 mysql>
SELECT * FROM test.demo_test;+-------+--------------+------+------+------+ | c1 | c2 | c3 | c4 | c5 | +-------+--------------+------+------+------+ | test2 | again | 10 | 4 | 0 | | test3 | again1 | 10 | 5 | 0 | +-------+--------------+------+------+------+删除所有行的表的使用 flush_all命令 telnet 127.0.0.1 11211尝试连接到127.0.0.1…127.0.0.1.escape字符是^ ]”。 flush_all好啊 检查以确保 flush_all手术是在从服务器复制。 MySQL的> SELECT * FROM test.demo_test;空集合(0秒)
最 memcached 操作映射到 DML 报表(类似于插入,删除,更新)。由于没有实际的SQL语句被MySQL服务器处理,所有 memcached 命令(除 flush_all)使用基于行的复制(RBR)测井,它独立于任何服务器 binlog_format设置 这个 memcached flush_all命令映射到 TRUNCATE TABLE在MySQL 5.7和更早的命令。自 DDL 命令只能使用基于语句的日志, flush_all命令是通过发送一个复制 TRUNCATE TABLE声明。在MySQL 8及以后, flush_all 映射到 DELETE但仍然是通过发送一个复制 TRUNCATE TABLE声明
的概念 交易 通常不被部分 memcached 20 .应用。For performance考虑, daemon_memcached_r_batch_size和 daemon_memcached_w_batch_size用于控制批量读写事务。这些设置不会影响复制。在下面的每个SQL操作 InnoDB 表格复制完成后 默认值 daemon_memcached_w_batch_size是 一 ,这意味着每个 memcached 写操作将立即。此默认设置,产生一定量的性能开销,避免数据不一致,可见在主从服务器。复制的记录总是立即可用的服务器。如果你设置 daemon_memcached_w_batch_size一个值大于 一 通过插入或更新,记录 memcached 不在主服务器上立即可见;查看记录在主服务器上之前,他们承诺,问题 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
InnoDBInnoDBInnoDBInnoDBInnoDBTRUNCATE TABLE
InnoDB
get | |
set | INSERT |
add | INSERT |
replace | UPDATE |
append | UPDATE |
prepend | UPDATE |
incr | UPDATE |
decr | UPDATE |
delete | DELETE |
flush_all | TRUNCATE TABLE |
daemon_memcachedconfig_optionsinnodb_memcached_config.sql
mysql>USE innodb_memcache;Database changed mysql>SHOW TABLES;+---------------------------+ | Tables_in_innodb_memcache | +---------------------------+ | cache_policies | | config_options | | containers | +---------------------------+
cache_policiesmemcachedsetflush
innodb_only使用 InnoDB 作为数据存储 cache-only:使用 memcached 发动机作为数据存储 caching:使用 InnoDB 和 memcached 发动机作为数据存储。在这种情况下,如果 memcached 无法在内存中找到一把钥匙,它搜索的价值 InnoDB表 disable:禁用缓存
policy_name | cache_policy |
get_policy | innodb_onlycachinginnodb_only |
set_policy | innodb_onlycachinginnodb_only |
delete_policy | innodb_onlycachinginnodb_only |
flush_policy | innodb_onlycachinginnodb_only |
config_optionsseparator
Name | config_options
|
Value |
containerscontainersmemcached
containersinnodb_memcached_config.sqlInnoDB
name | InnoDBdaemon_memcachedcontainers.namecontainersInnoDB |
db_schema | InnoDB |
db_table | InnoDB |
key_columns | InnoDB |
value_columns | InnoDBinnodb_memcached.config_optionscol1|col2|col3 |
flags | InnoDBincrvalue_columnsflags0 |
cas_column | InnoDBInnoDB0 |
expire_time_column | InnoDBInnoDB0 |
unique_idx_name_on_key | InnoDBInnoDB |
容器的表列的约束
你必须提供一个值 db_schema, _ DB NAME , key_columns, value_columns 和 unique_idx_name_on_key。指定 零 为 flags, 例_柱 ,和 expire_time_column如果他们不使用。如果不这样做可能会导致安装失败。 key_columns最大限制为: memcached 关键是250个字,这是强制执行的 memcached 。映射的键必须是非空 CHAR或 VARCHAR类型 cas_column:the 中国科学院 价值是一个64位的整数。它必须被映射到一个 BIGINT至少8个字节。如果你不使用这个栏目,设定值 零 表明它是无用的 expiration_time_column:必须映射到一个 INTEGER至少4个字节。到期时间为Unix时间是一个32位的整数(秒数自1月1日,1970年,作为一个32位值),或数秒,从当前的时间。对于后者,秒数不得超过60*60×24×30(30天的秒数)。如果客户端发送的数量较大,服务器认为这是一个真正的Unix时间而不是从当前时间偏移。如果你不使用这个栏目,设定值 零 表明它是无用的 flags:必须被映射到一个 INTEGER至少32位可空。如果你不使用这个栏目,设定值 零 表明它是无用的
多值列映射
在插件初始化,当 InnoDBmemcached 配置信息中定义的 containers表,每个映射的列定义 containers.value_columns 对映射验证 InnoDB桌子。多重 InnoDB 表中的列映射,有检查确保每一列的存在是正确的类型。 在运行时,为 memcached插入操作,如果有更多的限定值比映射的列数,只有映射值的数目了。例如,如果有六个映射的列,并提供了七个分隔的值,只有前六个分隔的值是。第七个分隔的值被忽略。 如果有较少的限定值比未映射的列,列设置为null。如果未填列不能设置为空值,插入操作失败。 如果一个表比映射值多列,外列不影响结果。
innodb_memcached_config.sqltest
innodb_memcached_config.sqlinnodb_memcache.containers
MySQL的> SELECT * FROM innodb_memcache.containers\G*************************** 1。行***************************名称:AAA db_schema:测试db_table:demo_test key_columns:C1 C2 C3 value_columns:国旗:cas_column:C4 expire_time_column:c5unique_idx_name_on_key:primarymysql > SELECT * FROM test.demo_test;---- ------------------ ------ ------ ------ | C1 C2 C3 C4 | | | | C5 | ---- ------------------ ------ ------ ------ | AA |你好,你好| 8 | 0 | 0 | ---- ------------------ ------ ------ ------
InnoDB
如果在MySQL错误日志遇到以下错误你,服务器可能无法启动: 未能打开文件设置rlimit。尝试运行的根或要求较小的maxconns价值。 错误消息是从 memcached 守护进程。一个解决办法是提高对打开的文件数量限制的操作系统。检查和增加打开文件限制不同的操作系统的命令。这个例子表明,Linux和OS X的命令: # Linux shell>
ulimit -n1024 shell>ulimit -n 4096shell>ulimit -n4096 # OS X shell>ulimit -n256 shell>ulimit -n 4096shell>ulimit -n4096另一个方法是减少对允许的并发连接数 memcached 守护进程。在这样做时,编码 -cmemcached 选项中的 daemon_memcached_option在MySQL的配置文件的配置参数。这个 C 选项的默认值为1024。 [mysqld] ... loose-daemon_memcached_option='-c 64'
要解决问题, memcached 守护进程是无法存储或检索 InnoDB表格数据,编码 - VVV memcached 选项中的 daemon_memcached_option在MySQL的配置文件的配置参数。检查MySQL错误日志输出相关的调试 memcached 运营 [mysqld] ... loose-daemon_memcached_option='-vvv'
如果指定抱柱 memcached 价值观是错误的数据类型,如数值类型而不是字符串类型,试图存储键/值对失败没有特定的错误代码或消息。 如果 daemon_memcached插件使MySQL服务器启动的问题,你可以暂时禁用 daemon_memcached 插件在排除下加入这行 [mysqld]在MySQL的配置文件组: daemon_memcached=OFF
例如,如果你运行 INSTALL PLUGIN语句之前运行 _ memcached _ config.sql InnoDB 配置脚本建立必要的数据库和表,服务器可能会崩溃,无法启动。服务器也可以失败,如果你错误地配置项的开始 innodb_memcache.containers表 卸载 memcached 一个MySQL实例插件,发表如下声明: mysql>
UNINSTALL PLUGIN daemon_memcached;如果你运行MySQL的多个实例在同一台机器上的 daemon_memcached插件可以在每一个例子中,使用 daemon_memcached_option配置参数指定一个独特的 memcached 每个端口 daemon_memcached插件 如果一个SQL语句不能找到 InnoDB表或表中没有找到数据,但 memcached API调用检索需要的数据,你可能会丢失的入口 InnoDB表中 innodb_memcache.containers 表,或者你可能没有切换到正确的 InnoDB通过发放表 得到 或 set要求使用 @ @ table_id符号。这个问题也可以如果你改变在现有项目发生 innodb_memcache.containers 无需重新启动MySQL服务器之后表。自由存储机制是足够灵活的,你的要求来存储或检索多个列的值,如 col1|col2|col3仍然可以工作,即使守护进程使用 test.demo _试验 Table which stors values in a single Column . 当定义你自己 InnoDB与使用表 daemon_memcached 插件,并在表的列定义为 NOT NULL值,确保供 不为空 当插入列的表记录到 innodb_memcache.containers表如果 INSERT声明为 innodb_memcache.containers 记录包含较少的限定值比有未映射的列,列设置为 NULL。试图插入一个 无效的 值为 NOT NULL柱的原因 INSERT失败,这可能只是变得明显之后你重新初始化 daemon_memcached 插件将更改应用到 innodb_memcache.containers表 如果 cas_column和 _到期时间_柱 田野里的 innodb_memcached.containers表格设置 无效的 ,返回下列错误尝试加载时 memcached 插件: InnoDB_Memcached: column 6 in the entry for config table 'containers' in database 'innodb_memcache' has an invalid NULL value.
这个 memcached 拒绝使用插件 NULL在 例_柱 和 expire_time_column专栏把这些列的值 零 当列未使用 的长度 memcached 键和值的增加,你可能会遇到的大小和长度的限制。 当钥匙超过250字节, memcached 操作返回一个错误。这是当前的一个固定的范围内 memcached InnoDB桌上的限制可能是如果值超过768字节大小的遭遇,3072字节大小,或一半的 innodb_page_size价值。这些限制主要适用于如果你想创建一个在值列运行生成报表的查询,使用SQL索引列。看到 第15.8.1.7”限制,InnoDB表” 详情 对关键值组合的最大大小为1 MB。
如果你分享的配置文件在不同版本的MySQL服务器,采用最新的配置选项的 daemon_memcached插件可以在旧版本造成的启动错误。为了避免兼容性问题,使用 释放 选项名称前缀。例如,使用 loose-daemon_memcached_option='-c 64'而不是 daemon_memcached_option='-c 64'没有限制或检查来验证字符集设置。 memcached 存储和检索的字节数的键和值,因此是不敏感的字符集。然而,你必须确保 memcached 客户端和MySQL表使用相同的字符集。 memcached 连接被禁止访问包含索引虚拟列表。访问索引虚拟列需要对服务器的回调,但 memcached 连接不能访问服务器端代码。
InnoDB
当一个操作失败或者你怀疑一个bug,看MySQL服务器错误日志(见 5.4.2部分,“错误日志” ) 第三,“服务器错误代码和消息” 提供了一些常见的故障排除信息 InnoDB特定的错误,你可能会遇到的。 如果失败是关系到一个 死锁 ,运行的 innodb_print_all_deadlocks选项启用,每个细节都印僵局MySQL服务器的错误日志。有关死锁,看 第15.5.5,“会”Deadlocks 如果问题是相关的 InnoDB数据字典,看到 第15.20.3,“排除InnoDB数据字典操作” 排除故障时,通常最好是从命令提示符运行MySQL服务器,而不是通过 mysqld_safe 或者是一个Windows服务。你能看到什么 mysqld 打印到控制台,等有更好的把握,是怎么回事。在Windows中,开始 mysqld 与 --console选择直接输出到控制台窗口。 使 InnoDB监视器获得关于问题的信息(见 15.16节,“InnoDB监视器” )。如果问题是性能相关的,或你的服务器似乎是挂了,你应该使标准监控打印的内部状态信息 InnoDB。如果问题是锁,使锁监视器。如果问题是表的创建、表空间或数据字典的操作,请参阅 InnoDB信息架构系统表 检查的内容 InnoDB内部数据字典 InnoDB暂时使标准 InnoDB 在下列条件下输出监视: 一个长的信号灯等 InnoDB找不到缓冲池中的空闲块 对缓冲池的67%是由锁堆或自适应哈希索引占用
如果你怀疑一个表损坏,运行 CHECK TABLE在那张桌子上
InnoDB
初始化的问题
InnoDBibdataInnoDBInnoDB
运行时存在的问题
InnoDB
确保 InnoDB数据文件和目录 InnoDB 日志目录存在 确保 mysqld 要在这些目录创建文件的访问权限。 确保 mysqld 可以读取正确的 my.cnf或 my.ini 选择文件,以便它从您指定的选项。 请确定磁盘未满,你不能超过磁盘配额。 确保你指定的名称的子目录和数据文件不冲突。 Doubleecheck The Sntax of the innodb_data_home_dir和 innodb_data_file_path的值。特别是,任何 马克斯 中的价值 innodb_data_file_path期权是一种硬限制,超过限制导致致命错误。
SELECT ... INTO
OUTFILEtbl_nameInnoDBinnodb_force_recovery[mysqld]
[mysqld]innodb_force_recovery = 1
innodb_force_recoveryinnodb_force_recoveryinnodb_force_recovery=1
innodb_force_recoveryinnodb_force_recovery
innodb_force_recovery
InnoDBINSERTUPDATEDELETEinnodb_force_recoveryinnodb_force_recovery
1( srv_force_ignore_corrupt ) 让服务器运行即使它检测到一个腐败 网页 。试图让 SELECT * FROMtbl_name在腐败指数记录和页面跳转,这有助于在倾销表。 2( srv_force_no_background ) 3( srv_force_no_trx_undo ) 4( srv_force_no_ibuf_merge ) 防止 插入缓冲 合并操作。他们是否会导致崩溃,不做。不计算表 统计 。这个值可以永久损坏的数据文件。使用此值后,会删除并重新创建所有的次要指标。套装 InnoDB为只读 5( srv_force_no_undo_log_scan ) 不看 UNDO日志 启动数据库时: InnoDB甚至将不完全交易的承诺。这个值可以永久损坏的数据文件。套装 InnoDB 为只读 6( _ SRV _队不_ _我日志 ) 不做 重做日志文件 辊与恢复了。这个值可以永久损坏的数据文件。离开一个过时的数据库页,这反过来可能会引入更多的腐败为B-树和其他数据库结构。套装 InnoDB为只读
SELECTinnodb_force_recoveryCREATEDROP
TABLEinnodb_force_recoveryDROP TABLEinnodb_force_recovery
ALTER TABLEinnodb_force_recoveryDROP
ORDER BY
primary_key DESC
innodb_force_recoveryWHERESELECT * FROM t
InnoDB
innodb_file_per_table.ibd
[错误] InnoDB:在文件操作数2操作系统错误。[错误] InnoDB:这个错误是系统找不到指定的路径。[错误]:不能为只读方式打开数据文件设置:'。/测试/ T1。IBD的操作系统错误:71 [警告] InnoDB表空间:忽略`试验/T1 `因为它无法打开。
DROP
TABLE
.ibd
.ibd
.ibd.idb
在新的MySQL实例,在一个同名的数据库重新创建表。 mysql>
CREATE DATABASE sakila;mysql>USE sakila;mysql>CREATE TABLE actor (actor_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,first_name VARCHAR(45) NOT NULL,last_name VARCHAR(45) NOT NULL,last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (actor_id),KEY idx_actor_last_name (last_name))ENGINE=InnoDB DEFAULT CHARSET=utf8;丢弃新创建的表的表空间。 mysql>
ALTER TABLE sakila.actor DISCARD TABLESPACE;复制的孤儿 .idb从你的备份目录到新的数据库目录文件。 内核> cp /backup_directory/actor.ibdpath/to/mysql-5.7/data/sakila/确保 .ibdhas the necessary文件的授权文件。 进口的孤儿 .ibd文件警告说明 InnoDB 将导入的文件没有模式验证。 mysql>
ALTER TABLE sakila.actor IMPORT TABLESPACE; SHOW WARNINGS;Query OK, 0 rows affected, 1 warning (0.15 sec) Warning | 1810 | InnoDB: IO Read error: (2, No such file or directory) Error opening './sakila/actor.cfg', will attempt to import without schema verification查询表的验证 .ibd文件被成功恢复 MySQL的> SELECT COUNT(*) FROM sakila.actor;---------- |计数(*)| ---------- | 200 | ----------
InnoDB
如果您运行的文件空间中的一个 表空间 ,MySQL Table is full错误的发生 InnoDB 回滚的SQL语句 锁等待超时的原因 InnoDB回到只有单个语句,等待锁遇到超时。(有整个事务回滚,启动服务器与 --innodb_rollback_on_timeout选择。)重新声明如果使用当前的行为,或者整个交易如果使用 --innodb_rollback_on_timeout死锁和锁等待超时是在繁忙的服务器正常可能知道他们可能发生和处理应用程序所必需的重试。你可以使他们不太可能做尽可能少的工作的第一个变化之间的数据交易和提交过程中,所以锁持有尽可能短的时间和尽可能多的行。有时分不同的交易之间的工作可能是实际和有用的。 当一个事务回滚发生死锁和锁等待超时,取消在交易报表的影响。但如果开始交易声明 START TRANSACTION或 BEGIN语句回滚不取消声明。进一步的SQL语句成为交易的一部分,直到发生 COMMIT, ROLLBACK,或一些SQL语句引起的隐式提交。 重复键错误回滚的SQL语句,如果您未指定 IGNORE在你的陈述中选择 一 row too long error回滚的SQL语句 其他的误差主要是由代码MySQL层检测(以上 InnoDB存储引擎的水平),和他们滚回相应的SQL语句。锁不回滚一个SQL语句释放。
ROLLBACKSHOW PROCESSLISTState